Introduction and Motivation
Introduction and Motivation
Machine learning의 목적은 data로 부터 valuable patterns을 뽑아내는 것이다
Dataset에 맞게 Model을 설계, Model은 input과 output의 function을 describe 할 수 있어야 한다
A model is said to learn from data if its performance on a given task improves after the data is taken into account.
Learning이란 data의 pattern이나 struct를 model의 parameter을 자동으로 optimize하며 찾아낸다.
머신러닝 시스템의 근본적인 이해를 위해 수학적인 기반은 매우 중요하다
Finding Words for Intuition
- Predictor : Input data에 맞는 prediction을 해내는 Algorithm
- Data as vectors
- vector as array (computer science view)
- vector as arrow with a direction and magnitude (physics view)
- vector as an object that obeys addition and scaling (mathmatical view)
- Model : input data-set과 비슷한 data를 만들어 내기위해 사용한다. 좋은 모델은 data의 hidden pattern을 뽑아낼 수 있고, 어떠한 일이 다음에 일어날지 예측또한 할 수 있다.
- Learning : 우리가 dataset과 model이 주어졌다고 가정하자. Model을 training하는 작업은 training data에 맞게 model의 parameter를 optimize하는 과정이다
대부분의 training 방법은 산을 오르는 과정과 비슷하다. 이 산의 정상은 maximum score를 의미한다.
우리는 model이 UNSEEN DATA 에서 잘 동작하기를 원한다. 따라서 우리는 model이 이전에 마주친 상황과 다른 상황에 자주 노출시켜 주어야 한다.
- Represent data as vector
- 확률과 optimization view를 사용해 적절한 모델을 선정
- 다양한 numerical optimization 방법을 사용하여 model이 training에 사용된 data가 아닌 다른 data에서 잘 동작하도록 함에 초점을 맞추어 학습
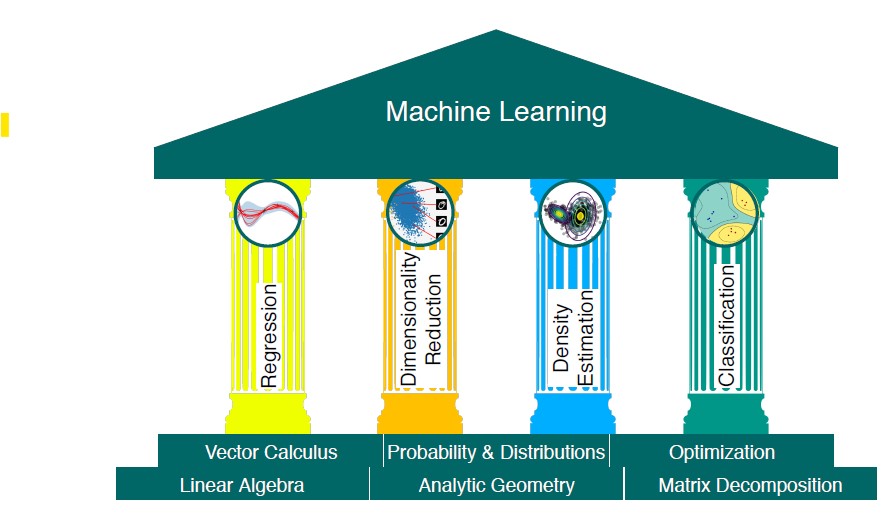 {: .align-center}
{: .align-center}
출처 : Marc Peter Deisenroth, Mathmatics for Machine Learning,(Cambridge University Press)
Introduction and Motivation
https://jo-member.github.io/2020/12/30/2020-12-30-ML&Mathmatics/