Week-1
BOOST camp의 첫주가 끝이 났다
정신없이 지내다 아침에 일어나서 오후까지 컴퓨터만 보다보니 5일이 지나갔다.
앞으로의 주말계획은 논문 1편과 1주일치 내용 복습이다
다음주에 발표인 프로젝트는 어찌될지 모르겠다. 열심히 해보려 했는데 생각보다 쉽지가 않네….
많은 사람들과 의견을 나누고 토론하는게 참 좋다.
week 1 정리 시작
5. Variable
먼저 5강 Variable에서 새롭게 안 사실들이다
이 리스트의 복사,
1 | a = [1,2,3,4,5] |
위와 같이 코드를 했을때 b가 가르키는 메모리 주소를 a 가 가르키는 형태이다
원래 파이썬에서 이런 처리를 해주었을때 앝은 복사가 일어남을 알고있었다.
얕은 복사는 학교 객지프 시간에 배워서 개념은 알고있었다. 그때 프린터기기와 원본, 사본의 예시로 교수님께서 설명하셨던 것 같다.
파이썬에서도 C의 포인터와 비슷한 개념이 있는듯 하다. C에서의 얕은 복사또한 포인터가 같은 메모리를 가르킨다.
a가 독립적으로 b의 값을 가지게 하기 위해서 깊은복사나 아니면 b[:]이런식으로 해준다
6. Function and Console I/O
여기서는 f - string을 얻어가자
1 | name = 'cho' |
이걸 잴 많이쓴다고 한다.
나도 원래는 format을 많이 썼었는데 이참에 f-string을 써봐야 겠다
8. String and advanced function concept
문자열 함수중에 좀 익숙하지 않은것들
- a.titile()
- a.startswith
- a.endswith
- a.isdigit()
큰따옴표 선언이후 작은따옴표 사용 or back slash \
2줄 이상저장법 : ‘’’ 3번사용
지역변수와 전역변수의 개념을 파이썬에서 알아보았다
global을 붙히면 함수내부에서 전역변수를 사용가능
이부분 function type hint는 잘 사용하지 않던거라 잊고있었다. 다시 remind 필요
1 | def type_hint_example(name:str)->str: |
이렇게 사용자가 타입을 알수있도록 (var:파라메터 타입) ->리턴타입을 표시
그리고 함수의 설명을 위한 docstring
세개의 따옴표로 docstring 영역표시(함수명 아래)
1 | def add_binary(a,b): |
이제까지 남들이 보는 코드라고 생각안하고 이런걸 몰랐었다
- dynamic typing으로 인해 함수의 interface를 알기 힘들기 때문에 아래와 같이 type hint를 줄수 있다
1 | def do_function(var_name: var_type) -> return_type: |
- 사용자에게 명확하게 알려줄 수 있다.
- mypy또는 IDE,linter등을 통해 코드의 발생가능한 오류를 사전에 확인
- 시스템의 전체적인 안정성
함수작성 가이드 라인
함수는 가능하지만 짧게 여러개를 만든다
함수 이름에 함수의 역할, 의도가 명확히 들어낼 것
하나의 함수에는 유사한 역할을 하는 코드만 포함
인자로 받은 값 자체를 바꾸진 말고 복사로 처리를 해서 다루어 주자
Coding Convention
일반적으로 4space를 권장함
한줄은 79자까지
연산자는 1칸이상 안 띄움
주석은 항상 갱신
코드의 마지막에는 한줄 추가
소문자 엘 대문자 오 대문자 아이사용금지
기준 : flack8 모듈로 체크
9. Data structure
여기서는 namedtuple만 짚고 넘어가자
named tuple이란 Tuple의 형태로 data의 variable들을 사전에 지정해서 저장한다.
1 | from collections import namedtuple |
10. Pythonic Code
이부분 Pythonic Code가 상당히 생소했다
이부분을 잘 짚고 넘어가야 추후 코드를 볼때 다시 인터넷을 뒤지거나 자료를 찾아보는 일이 없을것 같다
그리고 이걸 잘하면 간지나고 있어보임
List comprehension에서 주의해야 할점은
- 이차원 리스트
- FIlter
이차원 리스트를 보면
1 | case1 = ['A','B','C'] |
그리고 enumerate와 zip은 정말 많이 쓰이니 다시한번
index와 요소들을 tuple로 묶어 반환해줌
1 | {i:j for i,j in enumerate('hello my name is cho'.split())} |
이 코드가 좀 함축적으로 나타내고 있지 편한 기능들을
- zip : 2개이상의 list에서 하나씩 추출해서 tuple 형태로 리턴해줌
- map 함수는 iterable한 객체 (반복가능한 타입)과 함수를 주어 반환값들을 하나하나 계산해서 묶어줌, 근데 이후에 list든 뭐든 변환이 필요
또 map함수는 iteration을 생성하기 때문에 generator로
자 이제 진짜 중요한데 몰랐던거
iter 과 next함수
1 | for i in ['a','b','c']: |
이런 반복문에서 내부적으로 __iter__과 __next__가 사용된다
iterable한 객체에 next와 iter함수를 적용시켜 보자
iter을 사용하면
1 | cities = ["Seoul", "Busan", "Jeju"] |
Generator
iterable object의 특수한 형태
얘가 여기에 저장되어있대, 이것만 알고 호출시에 메모리에 올라감
yield를 쓰면 한번에 하나의 element return 리턴임 yeild는
메모리의 주소값만 가지고있다가 yield가 던져줌
제너레이터를 쓰는경우
- list형태의 데이터를 반환해주는 함수
- 데이터의 크기가 매우커서 쓸때, 호출할때만 그걸 메모리에 올려서 사용하는 경우
아래 코드의 차이를 알아보자
1 | x = [i for i in range(10)] |
Module and Project
여기서 좀 생소한데 중요한 개념인 package가 나온다
- 하나의 대형 프로젝트를 만드는 코드의 묶음
- 다양한 모듈들의 합, 폴더로 연결됨
- __init__, main등 키워드 파일명이 사용됨
- 다양한 오픈소스들이 package로 관리가 된다
__init__
현재 폴더가 패키지임을 알리는 초기화 스크립트
없을 경우 패키지로 간주하지 않음
하위폴더와 py파일을 모두 포함함
import 와 all을 사용한다
1 | __all__ = ['image', 'sound', 'stage'] |
이런느낌으로 현재사용할
__main__
1 | from sound import echo |
from game.graphic.render impoer render_test()
from .render import render_test()
- 현재 디렉토리 기준
from ..sound.echo
..2개면 상위 디렉토리로 가자
File/Exeption/Log Handling
- 예상불가능한 예외
- 인터프리터 과정에서 발생하는 예외, 개발자 실수
- 리스트의 범위를 넘어가는 값 호출, 정수 0으로 나눔
- 수행 불가시 인터프리터가 자동 호출
예상이 불가능 한 예외 발생시 exception handling의 대처가 필요하다
1 | try: |
파이썬에서는 try except구문을 권장한다
Python File I/O
read() txt 파일 안에 있는 내용을 문자열로 반환
f = open(‘i_have_a_dream.txt’,’r’)
contents = f.read()
여기서 f는 주소를 가지고 있는거임
print(contents)
f.close()
파이썬에서 with는 무엇인가를 사용후 반납해야 하는 경우 주로 사용이 된다
파일을 열고 닫을때 닫는걸 까먹을 수 있으니 파이썬의 with구문과 함께 사용한다
1 | with open("i_have_a_dream.txt",'r') as my_file: |
with가 끝날때 자동으로 close해줌
indentation이 있을때는 with안의 영역이 계속 사용되고 끝나면 자동으로 반납하는 개념
1 | with open("i_have_a_dream.txt",'r') as f: |
1 | with open("i_have_a_dream.txt",'r') as f: |
data가 너무커서 한번에 메모리에 올릴수 없다면 한줄씩 읽어서 해주고 싶은 작업을 해준다
encoding = ‘utf8’
이걸 이렇게 정해주어야지 헙업도 하고 그럼
1 | with open("i_have_a_dream.txt",mode = 'a', encoding) as f: |
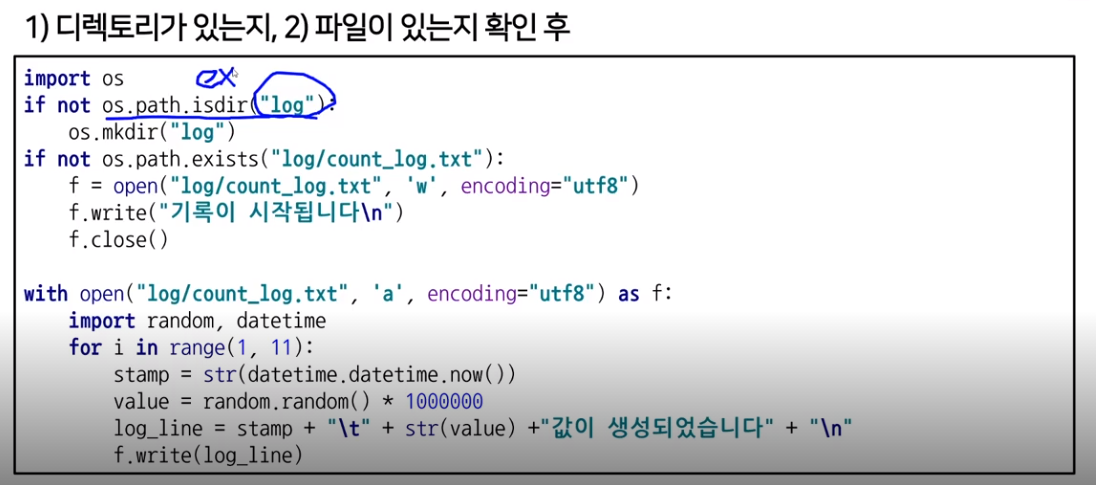
위와 같은 예제를 반드시 확인해 보자
먼저 if not os.path.isdir을 사용하면 현재 dir에 log라는 dir이있는지 확인한다
그이후 log안에 count_log가 업다면
생성해주고 닫는다
with구문 시작시 log를 열어서 그위에 for문을 순회하며 count_log에 문장을 추가한다
Pickle
파이썬의 객체를 영속화하는 built in 객체
객체는 원래 memory에 있어야 한다 이 memory에 있는거를 이 객체를 실행중 정보를 저장하고 이후에 불러올때 사용한다
객체는 원래 interpreter가 끝날때 같이 사라지기 떄문에 이를 저장할 수 있는 pickle을 사용하는 것이다
1 | import pickle |
Logging
레벨별로 기록을 남길 필요가있음
1 | import logging |
개발시점,운영시점마다 다른 log가 남을 수 있도록 지원함
Debug/info/warning/error/critical
- debug : 개발시 기록을 남겨야 하는 로그 정보를 남김
- Info : 처리가 진행되는 동안의 정보를 알림
- warning : 사용자가 잘못 정보를 입력하거나 처리는 가능하나 개발시 의도치 않는 정보가 들어왔을때
- error : 잘못된 처리로 인해 에러가 났으나, 프로그램 동작은 가능 할 때
- critical : 잘못된 처리로 데이터 손실이나 더이상 프로그램이 동작할 수 없음을 알림
위의 코드를 돌려보면 조심해,에러났어,망했다만 표시가 된다
그 이유는 logging level이 warning이상으로 setting이 되어있어서 이다
파이썬의 로깅레벨은 기본적으로 warning부터 이다
logging.basicConfig(level = logging.DEBUG)
steam_handler = logging.FileHandler('my.log',mode = 'w',encoding = 'utf8')
logger.addHandler(steam_handler)
이러한 코드 작성시 1. configparser 실행 설정을 파일에 저장 2. argparser 실행시점에
configparser
프로그램의 실행 설정을 file에 저장함
section, key,value값의 형태로 설정된 파일을 사용
설정파일을 Dict Type으로 호출후 사용
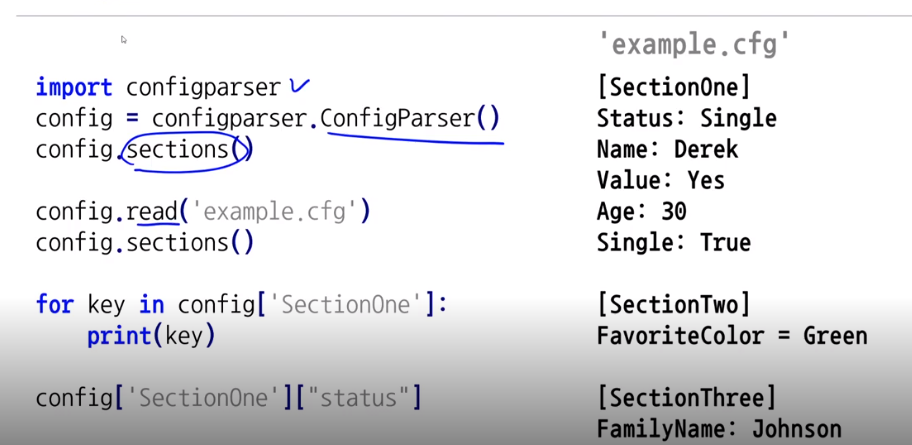
configparser를 사용하여 불러오고
argparser
console 창에서 프로그램 실행시 setting정보를 저장함
comand-Line-Option이라고 많이부름

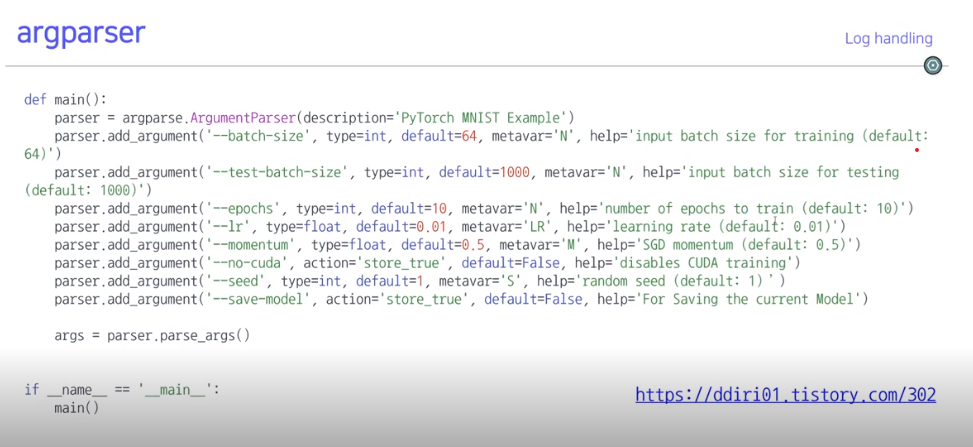
보통 cmd 창에서 명령어를 실행할 때 -나 –를 붙혀서 log파일을 실행한다
ex) ls –help
help하는 이름으로 실행을 시켜보아라 이런느낌 arg값을 넣어준다
보통 -한개는 짧을 때, –는 길때
parser.add_argument사용시 입력을 받아 args에 저장해준다
그때 지정해준 format인 -a면 a에 저장을 해주고
-b나 –b_value면 b에 저장해준다
사용자가 cmd창에서 실험을 할 수 있게 해준다
epoch값, lr값,momentum값,cuda여부등을 바로 실행시에 지정해줄수 있다.
Python data handling
이부분에서 xml, json,csv파일들에 대한 개념을 정리하고 간다
정규식도 꼭 몰랐던 부분이니 짚고 넘어가자
Comma Separate Value
- 엑셀 양식의 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식이라고 생각하면 쉬움
- TSV,SSV등으로 구분해서 만들기도 함
notepad로도 열 수 있고, 쉼표로 구분이 되어있다.
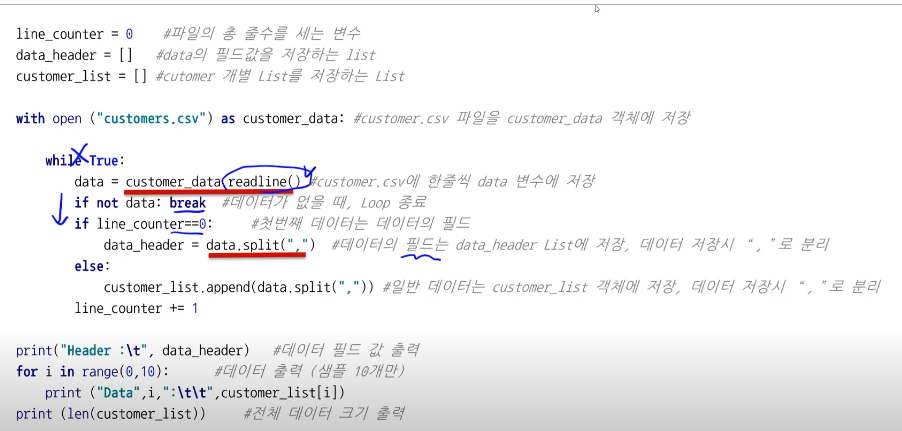
위에서 data_header라는게 있다.
여기에는 데이터의 필드가 담겨있ㅇ며 데이터 저장시 ,로 분리를 하는 코드이다
첫번째 data는 무조건 data의 필드이다 ex) data,index이런 느낌으로 카테고리이다
따라서 첫줄이라면 ,로 나누어서 data_header라는 리스트에 저장해준다
이후 줄부터는 ,로 나누어서 한줄씩 리스트에 저장해준다
text파일 형태로 데이터 처리시 문장내에 들어가있는 “,” 등에 대해 전처리 과정이 필요하다
파이썬에서는 간단히 CSV파일을 처리하기 위해 csv객체를 제공함
1 | import csv |
- delimiter : 글자를 나누는 기준 (default : ‘,’ )
- lineterminator : 중바꿈기준 (default : \r\n)
- quotechar : 문자열을 둘러싸는 신호 문자 (default : “ )
- quoting : 데이터를 나누는 기준이 quotechar에 의해 둘러싸인 라벨
1 | import csv |
위는 유동인구 데이터중 성남의 데이터만을 수집하는 코드이다
window에서 관리되는 코드는 cp949이다
vscode는 utf8이기 떄문에 encoding을 바꾸어 주어햐 한다
따라서 읽을 때 cp949로 읽는다고 별도로 지정한다
encoding은 cp949,
utf8로 왠만하면 저장하기 왠만하면 작은 ‘ 이걸로 나누고
보통 csv는 다른도구를 사용하기 때문에 지금은 이거에 집착할 필요가 없다 왠만하면 pandas를 사용하기 때문에
Web
HTML
제목, 단락, 링크 등 요소 표시를 위해 Tag를 사용
모든 요소들은 꺾쇠 괄호 안에 둘러 쌓여있음
<title> Hello, World </title>
보통 HTML도 일종의 프로그램이기 떄문에 규칙을 분석하여 데이터의 추출이 가능하다
추출된 데이터를 바탕으로 하여 다양한 분석이 가능
string, 정규식 (regex), beautifulSoup
Refular expression
- 복잡한 문자열 패턴을 정의하는 문자 표현 공식
- 특정한 규칙을 가진 문자열의 집합을 추출
기본문법
문자클래스 [ ] : [와] 사이의 문자들과 매치라는 의미
ex) [abc] : 해당글자가 a,b,c중 하나가 있다
- : 범위를 지정가능
정규식 표현을 위해 원래의미가 아닌 다른용도로 사용되는 문자들
. ^ $ * + ? { } [ ] : ( )
.은 전체를 의미한다
* 는 앞에있는글자를을 반복해서 나올 수 있음
+를 하게 되면 앞에 있는 글자를 최소 1회이상 반복
앞에있는글자를 최소한 1회 이상 반보기냐추배
{숫자} : 반복횟수를 지정해줄 수 있다
? : 반복횟수가 1회
| : or ex) (0|1){3} 0이나 1이 3번 반복
정규식 추출 연습
- Expression부분을 수정해가면 Zip로 끝나는 파일명만 추출
- Expression에 (http)(.+)(zip)
정규식 in python
- re모듈을 import 하여 사용 : import re
- 함수 : search - 한개만 찾기, findall - 전체찾기
- 추출된 패턴은 tuple로 반환됨
1 | import re |
urllib의 request한의 urlopen함수를 쓰면 해당 주소에 해당하는 cotents를 가져옴
findall로 해당패턴을 가진 모든 data를 찾아서 tuple의 형태로 list에 담기게됨
따라서 for loop으로 찍어내면 하나씩 나온다
XML
tag어ㅣ tag사이에 값이 표시되고 구조적인 정보를 표현할 수 있음
HTML과 문법이 비슷, 대표적인 데이터 저장방식
XML은 컴퓨터간의 정보를 주고받기 매우유용한 저장방식으로 쓰임
정규표현ㅅㄱ으로 Parsing이 가능함
가장많이 쓰이는 parser인 beautifulsoup
lxml과 html의

from bs4 import BeautifulSoup
soup = BeautifulSOup(book_xml,’lxml’)
soup.find_all(“author”)
tag를 찾는 함수 find_all
1 | import urllib |
이중으로 tag가 쌓여있는 정보는 이중으로 코드도 작성해 주어야 한다
연습 ipg140107.xml분석
분할된 특허문서로 부터 특허의 등록번호,등록일자,출원번호등등을 뽑아 CSV파일로 만들어보자
JSON
파이썬에서 json 모듈을 이용하여손쉽게 파싱 및 저장 가능
데이터 write와 read는 모두 dict 와 상호호환 가능
대부분 요즘은 json을 사용한다
