Pandas & 딥러닝 학습방법
pandas
- 구조화된 데이터의 처리를 지원하는 파이썬 라이브러리
- panel data -> pandas
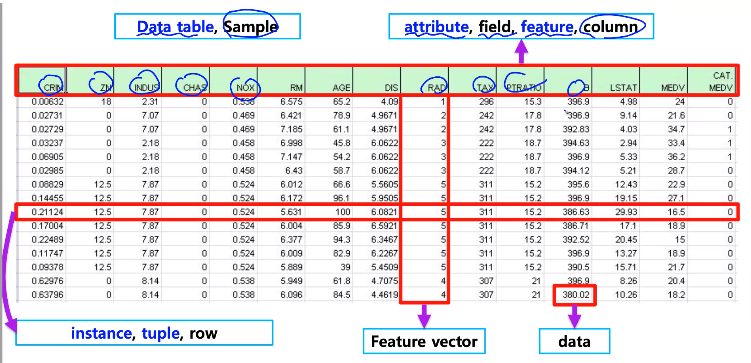
가로줄은 instance, row
data table은 모든 data가 담겨 있는 sample
column은 각각의 feature이름들, data.columns하면 이름들을 각각 지정해 줄 수 있음
feature vector, 각 feature에 해당하는 vector
data는 각각의 값
head는 앞에 5개 출력
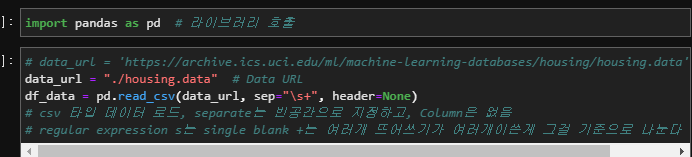
data_url지정 후 , pd.readcsv(data_url, sep=’\s+’, header = None)
header설정시 초기화시 column을 같이 초기화 해줄수 있음
이렇게 read_csv를로 읽어오면 type은 numpy임
Series
Column에 해당하는 데이터의 모음
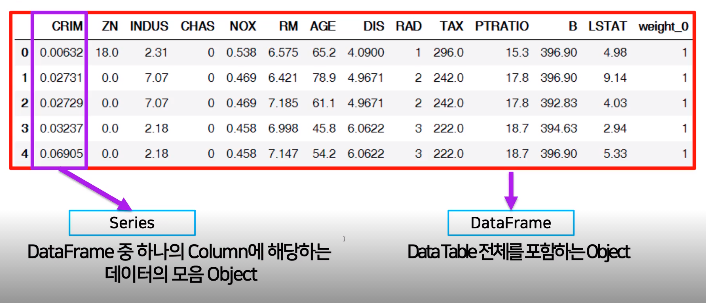
index값이 있다
1 | import pandas |
- subclass of ndarray
- dict타입을 series에 넣어주면, key값들이 index value는 value로 matching되어 생성됨
- Series에 inedx로 접근할때 dict와 비슷하게 접근한다
- astype으로 type변환 가능
- Series.name = ‘number’라고 해서 series의 이름을 지정 가능
- index.name도 지정가능
1 | dict_data_1 = {"a": 1, "b": 2, "c": 3, "d": 4, "e": 5} |
Data Frame
Series data가 모여서 하나의 Data Frame을 이룸
여기서는 Column도 가능
접근 자체를 index와 columns로 함(행렬처럼 접근가능)
각 Colunm들은 type이 달라도 됨
1 | from pandas import Series, DataFrame |
- column을 삭제함
- axis = 1 -> column기준으로 debt를 삭제
- del 을 사용하면 삭제할수 있음
- 거의 csv파일이나 json data
Selection with column names
1개 이상의 columns 추출
list꼴로 넣어주면 dataframe형태로 뽑힌다
fancy index, boolen index
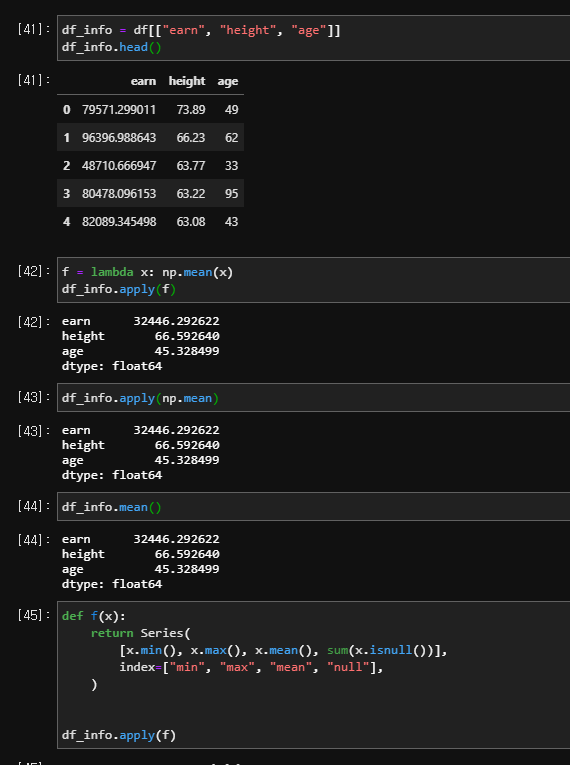
Map apply Lambda

map과 lambda를 사용하여 series data에 lambda함수를 적용해준다
여기서 map을 dict type으로 데이터를 교체하기도 함

index는 그대로 s1을 따르고 dict에 key값에 해당하는 index에 value 값을 넣어준다 나머지는 Nan처리
Series + dataframe
이것도 연산을 할 수 있다
덧셈시 add함수를 사용하여 axis를 잡아주어야 한다
그러면 broadcating이 일어난다
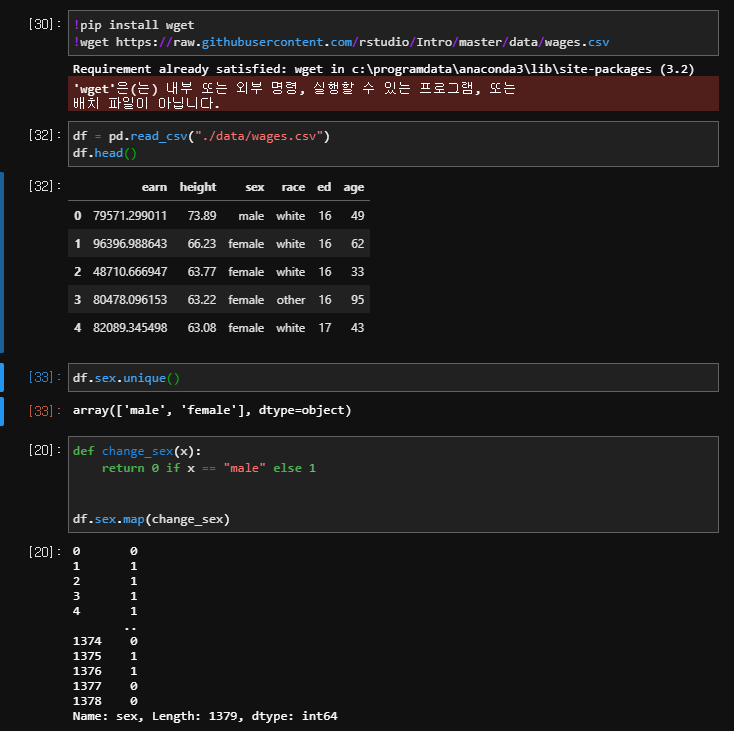
이렇게 처리해주면 숫자로 학습을 해야하는 딥러닝 과정에서 문자열 데이터를 숫자값으로 바꾸어 주어 계산이 가능해진다. 위와같이 함수를 하나 정의해서 map으로 처리해주면 된다
또한 apply라는 함수로 각 column에 대해서 함수연산을 해 줄 수도 있다
pandas2
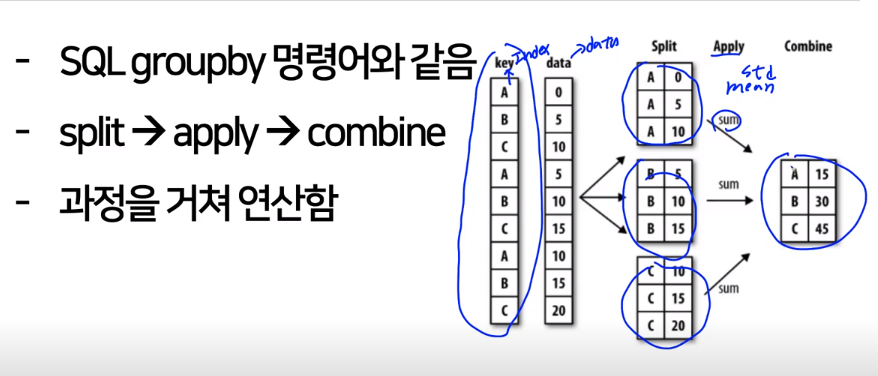
Groupby
- SQL groupby명령어와 같은
- split -> apply -> combine
- 과정을 거쳐 연산함
기존의 data에서 먼저 같은 종류의 index가 같은 것 끼리 묶어서 계속 연산을 진행하는것
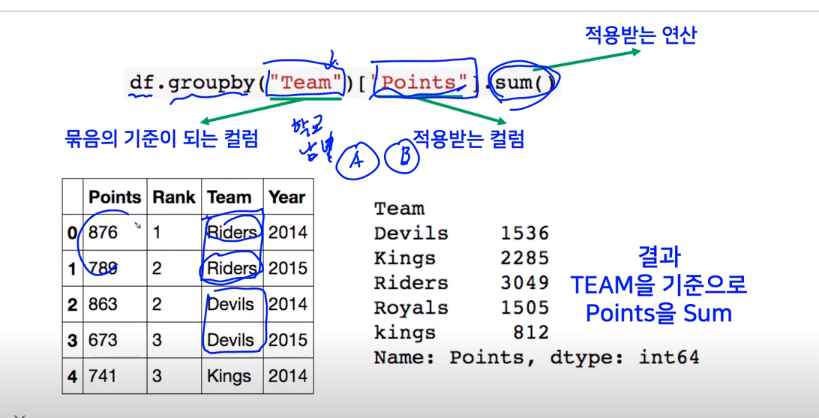
df.groupby("Team")['Points'].sum()
위연산 실행시 Team이라는 column기준으로 Pointsfmf 모두 더해서 모두 같은 team이 같은값을 가지는애들끼리 point를 모두 더한다
한개 이상의 column을 묶을 수 있음
- groupby의 결과(type은 series이다)로 묶인 series에 unstack을 하게 되면 dataframe으로 만들어줌
- swaplevel()로 index의 level을 변경할 수 있음 ( 결과물만 바뀌어서 출력되는거지 , 원본은 바뀌지 X )
- sort_index(level = 0)
- sort_values()
df.groupby(["Team","Year"])['Points'].sum()
이결과로 여러 team과 year로 나누어진 index를 가진 series가 생성되는데
여기서 .sum(level) level값으로 index를 정해 연산을 취해 줄 수 있다.
Grouped
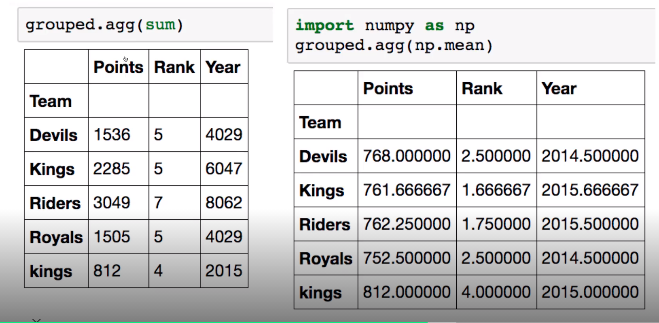
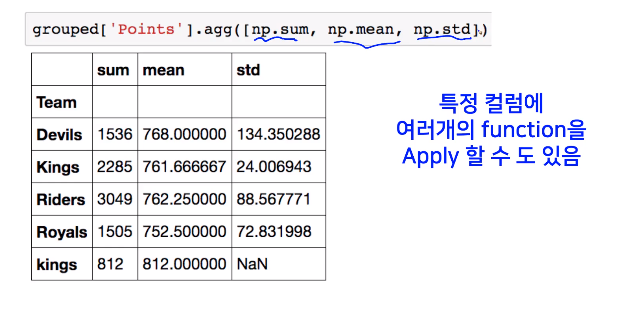
1 | grouped = df.groupby("Team") |
- 추출된 group정보에는 세가지 유형의 apply가 가능함
- Aggregation : 요약된 통계정보를 추출해 줌
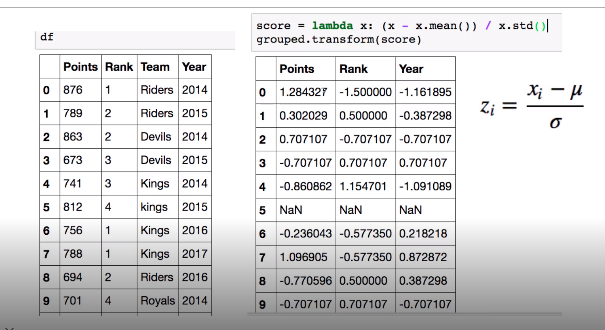
- Transformation : 해당 정보를 변환해줌
- FIltration : 특정 정보를 제거 하여 보여주는 필터링 기능
개별데이터에 이걸 적용할 수 있음
데이터의 변환과정에서 많이 쓴다
groped된 상태에서 group별로 연산을 가능하게 해준다
df.groupby(“Team”).filter(lambda x : len(x) >=3)
딥러닝 학습방법
신경망

각 행벡터인 o는 데이터 X와 가중치 W 그리고 biad항인 b의 합으로 표현된다
입력벡터인 X의 차원 = n x d
출력벡터인 O의 차원 = n x p
d개의 변수로 p개의 선형모델을 만들어 p개의 잠재변수를 설명
X를 O에 Mapping한다고 생각하면 편하다
행렬을 생각하는 방식에서 행렬을 하나의 data를 다른 domain으로 변환하는 operator라고 생각했을때의 개념을 사용한 것이다
Softmax

출력 벡터 o에 exp를 취해주어 각 출력벡터에 대한 확률으로 나타내 준다
분류문제를 풀때 선형모델과 Softmax함수를 결합하여 예측한다
- 신경망은 선형모델과 활성함수를 합성한 함수이다
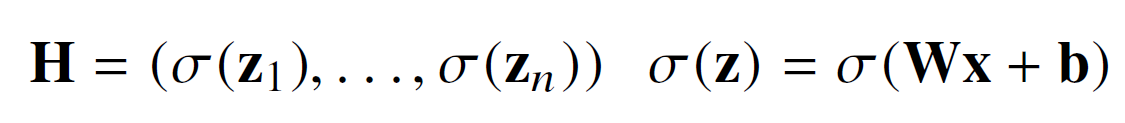
X라는 입력 벡터들에 가중치를 곱해주고 bias를 더해주어 activation functiond을 적용
위의 식은 2 layer의 가장 간단한 NN이다
활성함수란?
- 흔히들 요즘에는 ReLU함수를 사용한다
- 활성함수를 쓰지 않으면 선형모델과 딥러닝은 차이가 없기 때문에 중요한 요소이다
- ex) sigmoid, softmax, ReLU, tanh,
다층 perceptron은 위의 H를 다시 다른 가중치에 곱하고 …. 이후의 과정을 반복한다
- 이론적으로는 2-layer 신경망으로도 함수를 근사할 수 있지만 층이 깊을수록 목적함수를 근사하는데 필요한 node의 숫자가 훨씬 빨리 줄어들어 효율적이다
- 층이 얇으면 wide한 신경망이 되어야 한다
역전파 수식전개
Pandas & 딥러닝 학습방법
https://jo-member.github.io/2021/01/27/2021-01-27-Boostcamp8/