확률론2
Day10 : 확률론2
모수란?
통계적 모델링은 적절한 가정위에서 확률분포를 추정하는것이 목표!
데이터는 유한하기 때문에 근사적으로 확률분포를 추정할 수 밖에 없다
데이터가 특정확률분포를 따른다고 선험적으로 가정한 후 그분포를 결정하는 모수(parameter)를 추정하는 방법을 모수적 방법론이라고 한다
특정확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌면 비모수방법론이다

데이터를 생성하는 원리를 먼저 고려하는 것이 원칙 !!!
데이터로 모수를 추정해보자!
표본평균 : 주어진 데이터의 산술평균

N-1로 나누는게 조금 신기하고 다른 점 -> 불편추정량
중요한 개념
통계량(표본분산, 표본평균)의 확률분포를 표집분포라부르며(sampling distribution)
이게 좀 신기한게 데이터들의 확률분포는 표본분포(sample distribution)이다
모집단의 확률분포가 정규분포를 따르지 않아도 sample의 갯수를 늘린다면 표본평균의 모집분포는 정규분포를 따른다
가능도의 직관적인 정의 : 확률분포함수의 y값
- 셀 수 있는 사건: 가능도 = 확률
- 연속 사건: 가능도 ≠≠ 확률, 가능도 = PDF값

- 수식은 같지만 변수가 다름
최대가능도 추정법 (MLE)
이론적으로 가장 가능성이 높은 모수를 추정하는 방법 중 하나가 바로 MLE다
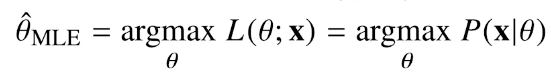
가능도 함수 : 데이터가 주어진 상황에서 $\theta$를 변형 시킴에 따라 변하는 함수로 이해
즉 조건부 함수와 비슷
그러나 $\theta$에 대한 확률이 아닌 대소비교가 가능한 그냥 함수라고 생각을 하자
데이터 집합 X가 독립적으로 추출되었을 경우 로그가능도를 최적화 합니다
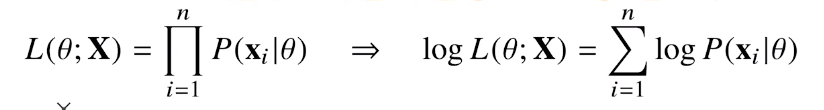
- P(x
i| $\theta$)의 곱이 풀어서 쓰면 로그들의 곱이라 로그의 합으로 나타낼 수 있다
왜 로그가능도를 사용하나요?
데이터의 숫자가 졸라 많아지면 컴퓨터의 정확도로는 Likelyhood를 계산하는 것이 불가능하다
따라서 데이터가 독립일 경우 가능도의 곱셈을 가능도의 덧셈으로 바뀌면 컴퓨터로 연산해서 최적화 가능
경사하강법으로 가능도를 최적화할 때 미분 연산을 사용하게 되는데, 로그 가능도를 사용하면 연산량을
O(n^2^)에서 O(n)으로 줄어든다
대개의 손실함수의 경우 gradient descent를 사용하므로, 음의 로그가능도를 최적화하게 된다.
WHY 음의 로그가능도? -> 손실함수를 최소화 해야하기 때문에 음의 로그가능도 사용
Ex1 : 정규분포
독립적인 표본을 얻었을 때 최대가능도 추정법을 이용하여 모수를 추정하면
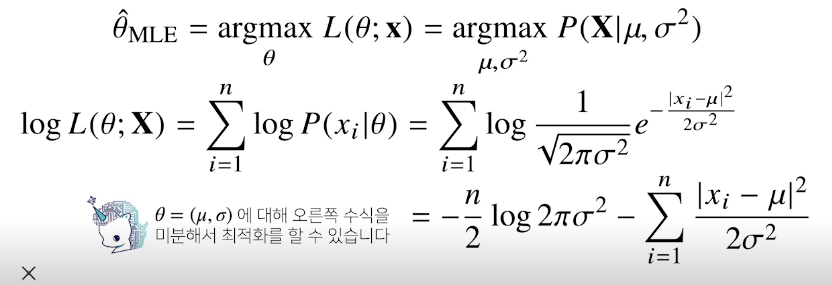
$\theta$($\mu,\sigma$)에 대해 오른쪽 수식을 미분
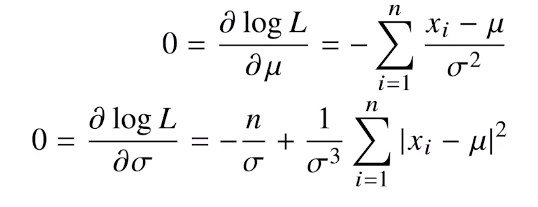
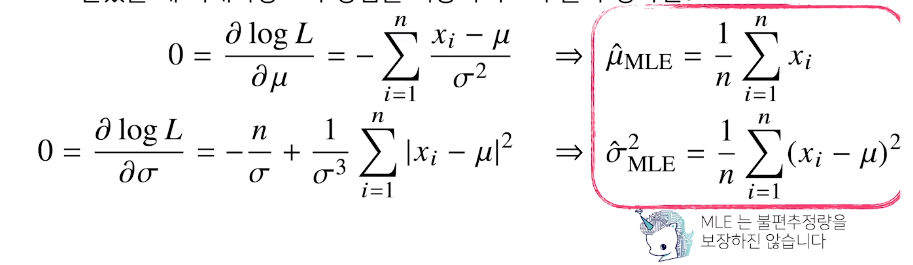
유도과정을 손으로 도출해보기
Ex2 : 카테고리 분포

카테고리 분포이기 때문에 제약식이 생김
여기서의 모수는 1-d 차원 까지 값이 1또는0이될 확률
모두 더했을때 1이 되어야 하는 제약식이 생긴것
근데 이보다 먼저 가테고리 분포에 대한 이해를 해보자

베르누이 독립시행
동전을 100번 던졌다. 그 중 60번 나왔다. 앞면이 나올 확률이 p(모수)라고 하면 가장 이러한 사건이 일어날 가능도가 높은 p를 구해보면..
일단 100번 던져서 60번 앞면이 나오는 확률 P = 100C60 p^60 (1-p)^40
이러한 확률을 p로 미분했을 때 0이 되는 p값이 P가 최대가 될 떄일 것이며 이것이 MLE로 추정되는 모수 p이다.
로그함수의 성질을 생각했을때 P의 증감은 f(p) =log(p^60 (1-p)^40)과 증감이 같다. 즉 f(p) 가 최대가 될때 P도 최대가 된다.
df/dp = 60/p - 40/(1-p) = 0 , 즉 p = 0.6 일때 f’(p) = 0 이 되며 이것이 우리의 직관과 일치한다. (MLE 끝)
이게 이제 이항분포
전추정 : 0.5값을 가지고 싶어서 던졌는데
구분추정 : 신뢰구간
카테고리 확률분포에서 x데이터가 one hot encoding된 벡터구만
그래서 이렇게 표현하는것이였다
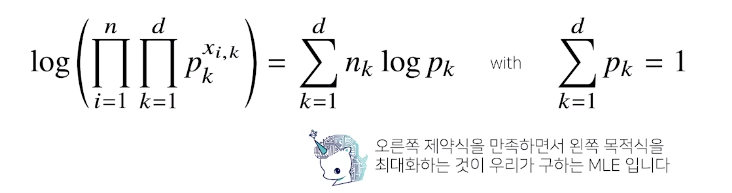
오른쪽 제약식을 만족하면서 왼쪽 목적식을 최대화 -> 최대가능도 추정(MLE)
여기서도 라그랑주가…..
이거 수식전개 해보기
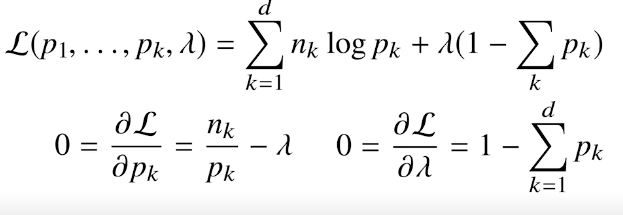
딥러닝에서의 최대가능도 추정법
딥러닝 모델의 가중치를 $\theta$(W1,W2,W3…,WL)이라 표기했을때 마지막 softmax vector은 카테고리분포의 모수(p1,p2…,pk)를 모델링한다
원핫벡터로 표현된 정답 레이블 y = (y1,y2….,yk)를 관찰데이터로 이용해 확률분포인 소프트멕스 벡터의 로그가능도를 최적화 할 수 있다.
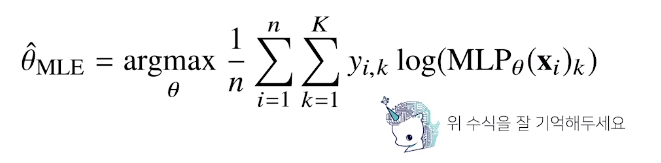
확률분포에서의 거리
- 기계학습에서 유도되는 Loss function들은 모델이 학습하는 확률분포와 데이터에서 관찰되는 확률분포의 거리를 통해 유도된다
두확률분포사이의 거리
- 총변동거리 (Total Variation Distance, TV)
- 쿨백-라이블러 발산
- 바슈타인 거리
쿨백-라이블러 발산 (Kullback - Leibler Divergence)
정의
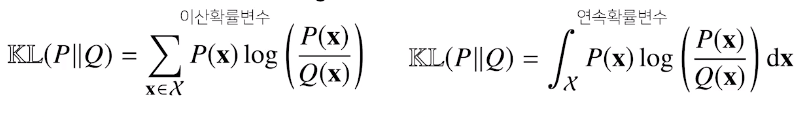
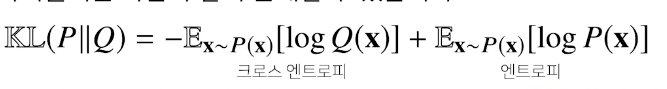
졸라리 어렵다
뭔소리인가 도대체 이게
결국은 정답레이블을 P, 모델 예측을 Q라 두면 ?
Log likelihood를 최대화 하는것과 P와 Q사이의 쿨백하이블러 발산의 최소화는 밀접하다??
두개의 확률분포의 거리를 최소화 한다?
결국 결론은 !!!!!!!!!!!!!
딥러닝 기계학습에서 통계학적인 지식(MLE)들을 사용하여 Loss function을 최소화 시킬수 있다????
피어세션에서 이번 강의에 대한 심도깊은? 토론을 하였다
Further Question
확률과 가능도의 차이는 무엇일까요? (개념적인 차이, 수식에서의 차이, 확률밀도함수에서의 차이)
확률 대신 가능도를 사용하였을 때의 이점은 어떤 것이 있을까요?
다음의 code snippet은 어떤 확률분포를 나타내는 것일까요? 해당 확률분포에서 변수 theta가 의미할 수 있는 것은 무엇이 있을까요?
1 | import numpy as np |
위의 코드를 보자
theta는 0-1 사이에서 0.001의 간격으로 값을 가진다
모든 theta의 합은 1로 이는 결국 확률이다
이번주말에 정리해야 될 것들
- 다양한 확률밀도 함수에대한고찰
- 확률과 가능도
- 가능도에서의 최대가능도 추정법
- MLE의 적용 - 정규분포, 이항분포
- gradient descent 수식전개
- 월요일날 발표 (기본적인 kaggle dataset)
- back propagation 수식전개
- pandas 정리
- 시각화 도구