RNN1
RNN
Sequence Data & Model
소리, 주가, 문자열 등의 데이터를 시퀀스 데이터로 분휴합니다
시계열 데이터는 시간순서에 따라 나열된 데이터로 시퀀스 데이터에 속한다
독립동등분포 가정을 잘 위해하기 때문에 순서를 바꾸거나 과거정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 된다
Markov model : first order autoregressive model
이들의 문제를 해결하기 위해 Latent autoregressive model
hidden state가 과거의 정보들을 summerize한다
다루는 법
- 조건부 확률을 이용(과의 정보를 가지고 미래를 예측 )

바로직전까지의 정보 S-1를 사용해서 현재인 S를 업데이트
반드시 모든 과거의 정보를 가지고 업데이트 하는 것은 아니다
따라서 조건부에 들어가는 데이터의 길이는 가변적이다
고정된 길이인 $\tau$만큼의 시퀀스만 활용하는 경우 Autoregressive Model(자기회귀모델)이라고 부른다
직전과거의 정보랑 직전정보가 아닌 정보들을 Ht로 묶어서 활용
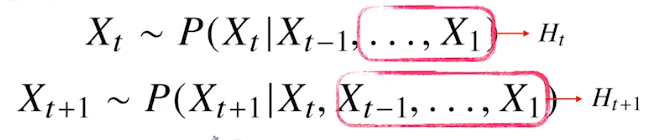
길이가 가변적이지 않고 이제 고정되기 때문에 여러가지 장점을 가지고 있다
사실은 과거의 모든 정보를 고려하기가 힘든 문제점을 고쳐서 이제 이전의 정보를 요약하는Ht를 예측하는 모델 —-> RNN
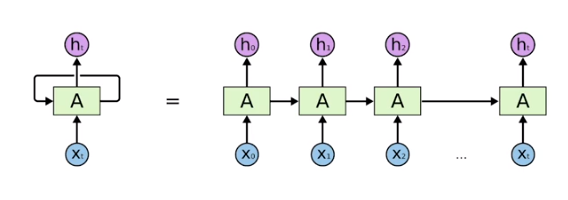
RNN 이해하기
기본적인 모형은 MLP와 유사하다
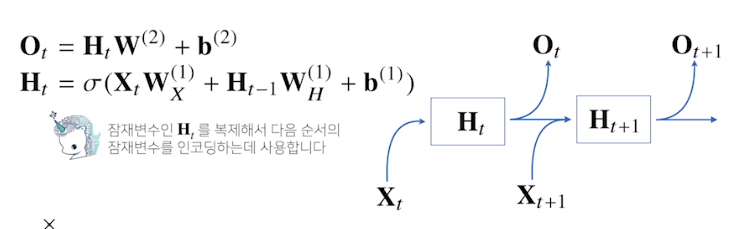
RNN의 역전파는 잠재변수의 연결그래프에 따라 순차적으로 계산한다
Back Propagation Through Time
BTTP를 살펴봅시다
BTTP를 통해 gradient를 계산해보면 미분의 곱으로 이루어진 항이 계산이 된다

길어지면 계산이 불안정해짐으로(gradient vanishing과 같은)문제가 있기 때문에
길이를 끊는것으로 truncated BPTT
Gradient vanishing 문제의 해결??
- 시퀀스 길이가 길어지는 경우에는 BTTP를 통한 역전파 알고리즘의 계산이 불안정해 지므로 길이를 끊는것이 중요하다
- ex) LSTM, GRU …..
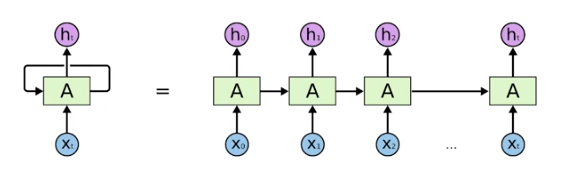
RNN을 시간순으로 쭉 풀면 결국 fully connected layer network가 된다
가장어려운 ? 단점 ? —-> 하나의 fixed rule로 이전의 정보들을 summerize하기 때문에 먼 과거의 정보들이 현재에서 살아남기가 힘들다!! 이게 short term dependencies
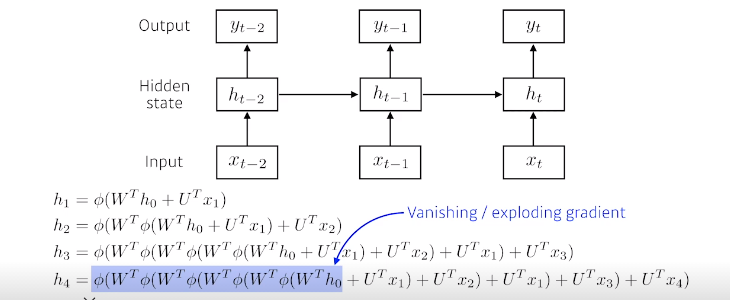
결국 먼 과거의 정보들은 많은 양의 activation function과 W곱의 결과로 vanishing or exploding되는 현상이 일어나게 된다
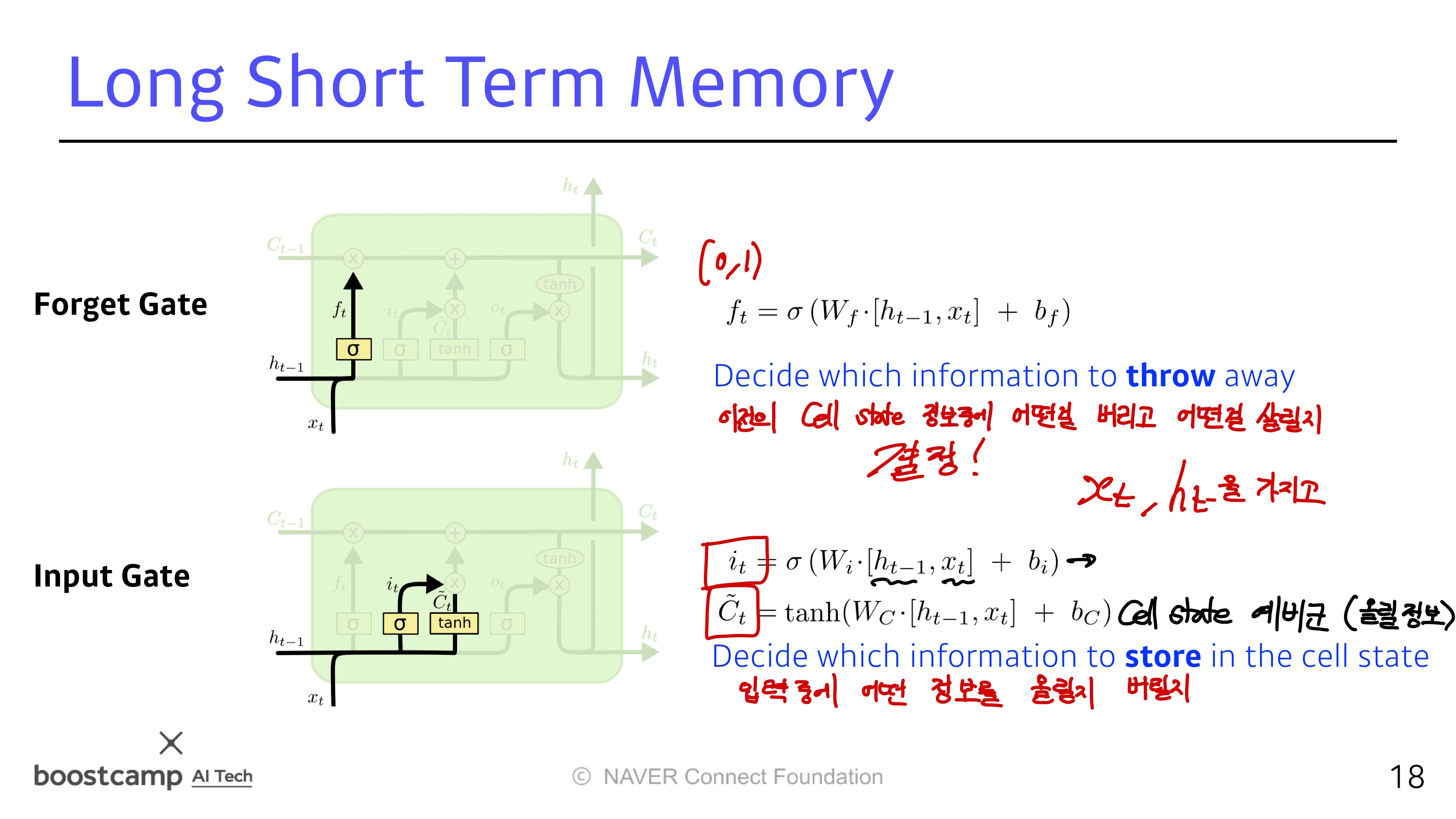
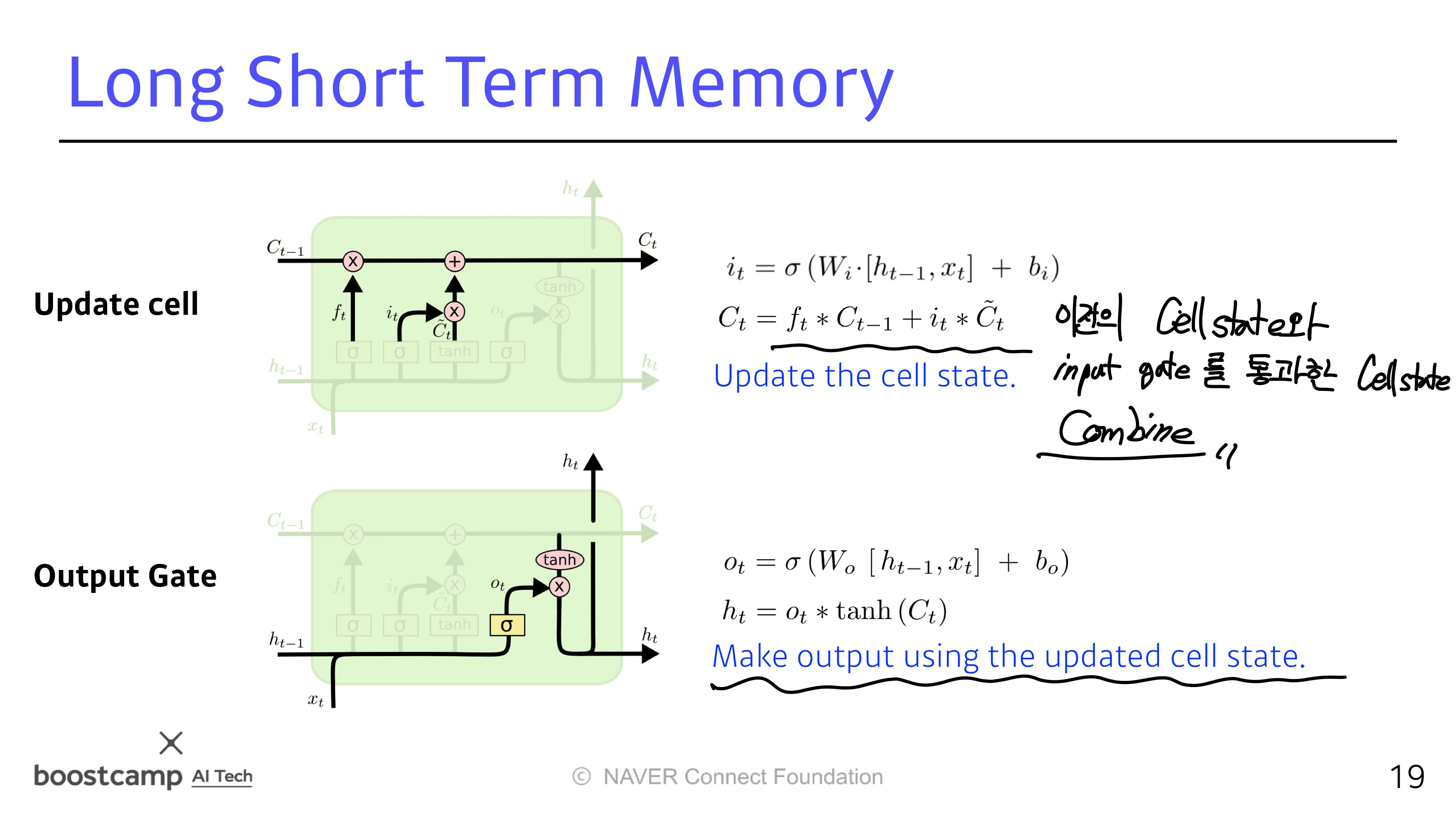
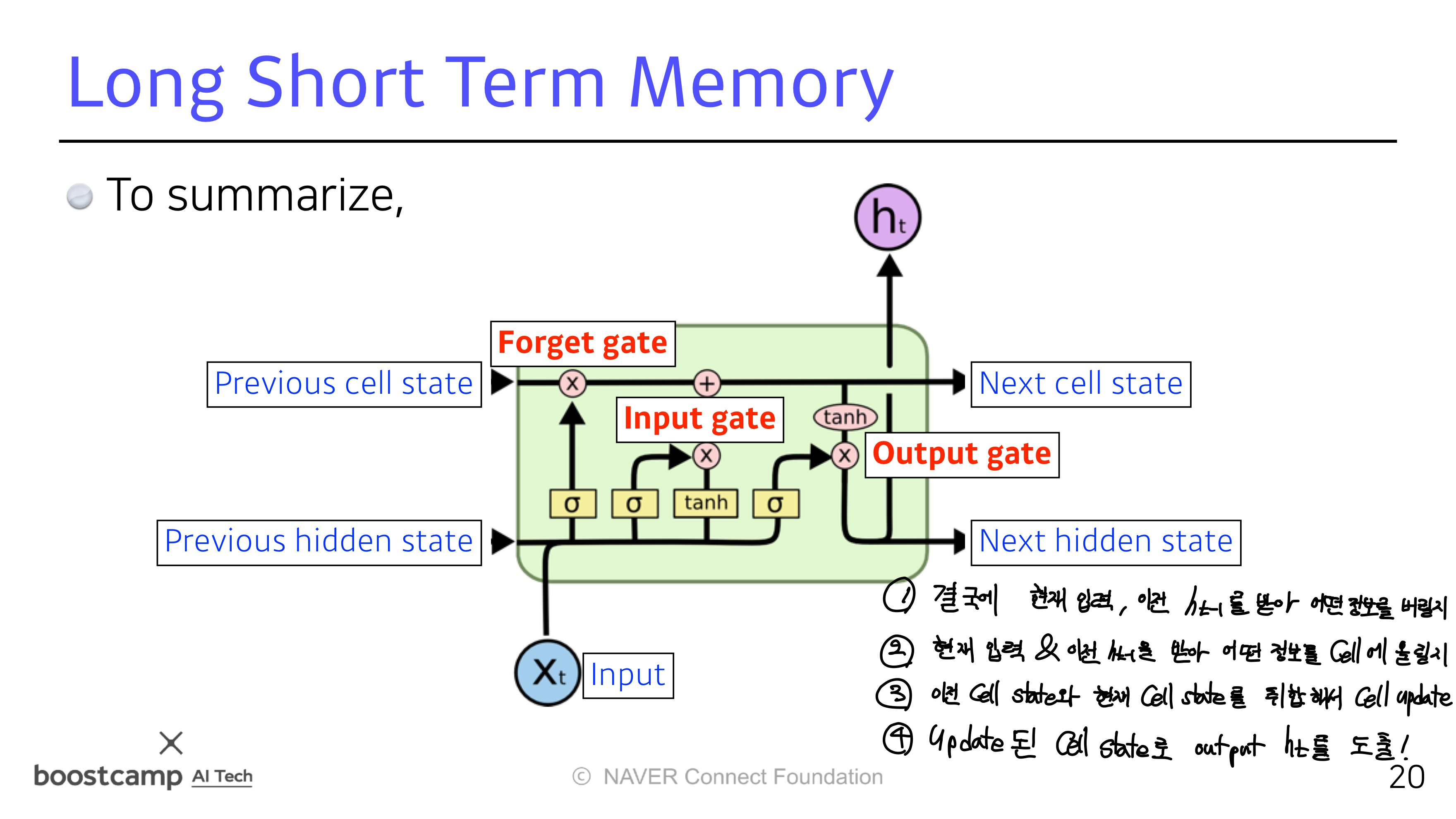
LSTM
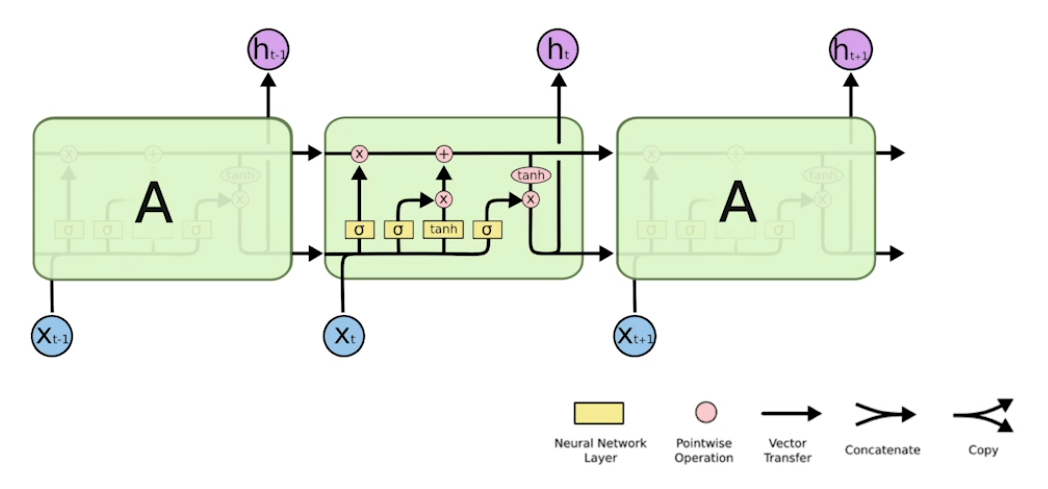
LSTM의 전체적인 구조
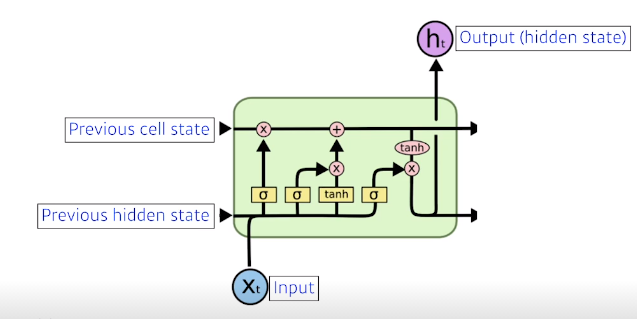
들어오는 입력이 3개 나가는게 3개
실제로 나가는건 ht (hidden state)