Attention Is All You Need
Abstract
Seuence transduction model들은 현재 복잡한 recurrent한 구조 (RNN) 이나 encoder decoder를 포함한 CNN이 주를 이룬다. 가장 좋은성능을 내는 model또한 attention mechanism을 이용하여 encoder와 decoder를 연결하는 형태이다.
이 논문에서는 새로운 방법인 Transformer를 제안
이는 오로지 attention mechanism만을 사용!
이는 RNN이나 CNN보다 더 병렬화가 가능하고 train하는데 적은 시간이 걸린다!
WMT 2014 English to-German data를 사용하여 BLEU라는 score에서 28.4점을 얻었다.(여러 논문을 읽다보면 자주 등장하는 이 BLUE score은 정리해 놓은게 있는데 추후에 posting )
이는 앙상블을 포함한 이전의 가장 좋은 성능보다 2BLUE가 높다.
1. Introduction
RNN모델 (LSTM이나 GRU)는 machine translation과 같은 sequence modeling의 State of the art한(최신의 가장 좋은 성능의) 접근방식으로 알려져있다. RNN은 input과 output의 위치를 계산한 결과를 담고있다. 계산하는 시간이나 순서에 의해 정렬된 위치들은 이전의 hidden state ht-1로 표현된 연속적인 hidden state ht를 생성한다. 이것은 본질적으로 training examples의 병렬화를 배제하며, 이로인해 memory의 한계로 인한 batch size의 한계 때문에 긴 sequence length에 굉장히 critical한 요소로 작용한다. 최근의 연구들은 factorization과 conditional computation(이것에 대한 논문: Oleksii Kuchaiev and Boris Ginsburg. Factorization tricks for LSTM networks, Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer )을 이용한 계산과정의 효율화로 큰 발전을 이루어냈다. 하지만 순차적인 계산에 의한 제약은 아직 남아있다
Attention mechanism은 input과 out사이의 길이에 상관없이 dependencies를 modeling할수있다는 부분에서 sequence modeling과 transduction modeling의 필수적인 부분이 되었다. 하지만 몇몇 경우에서는 아직 attention mechanism과 RNN을 합쳐서 사용하고 있다.
이 연구에서는 Transformer라는 attention mechanism에만 의존하여 input과 output의 dependency를 이끌어내는 architecture을 제안한다. Transformer은 병렬화를 가능하게 하고, 성능을 더욱 향상시킬수 있다
요약 : 우리의 transformer가 training example의 병렬화로 인한 속도 향상과 좋은 점수를 낸다.
2. Background
encoder , decoder에대한 background
중간의 latent space는 input이나 output보다 훨씬 최소화된 vector이다. Sequential한 계산을 줄이는 목표는 기본적인 building block에서 CNN을 사용하여 병렬적으로 input과 output의 hidden representation을 계산하는 ByteNet이나 ConvS2S의 기반을 이루고있다. 위와 같은 model에서는 2개의 input이나 output의 길이가 증가할수록 계산량이 늘어난다.(ByteNet은 log적으로, ConvS2S는 linear하게). 이러한 결과는 거리에 따른 dependencies들을 학습하기에 더욱 어렵게 만든다.
※ (input과 output사이의 길이가 길어지면 계산량이 증가해 서로의 연관관계를 학습하기가 어렵다는 뜻
cnn은 한번에 kernel size를 진짜 커봤자 최대 7x7을 쓰기 때문에 만약 input이 엄청 길다면 CNN연산시 계산량이 증가하게 되고 위치에 대한 정보의 일부만이 담기게됨. 예를 들어 간단하게 she is pretty and good at playing piano with her own piano와 같은 문장에서 뒤에 her과 처음 she는 긴 거리를 가지게 되어서 이 정보를 담기에 CNN은 부적절?).
Transformer에서는 linear나 logmatric하게 계산량이 증가하지 않고 constant한 number로 증가한다.Attention-weigheted position의 평균을 사용하여 Effective한 **해상도?**가 감소함에도Multi-Head Attention과 상호작용 함으로서 계산량을 줄였다.
Self-attention은 서로 다른 position에 있는 sequence를 표현하기 위해 서로를 relating한다.
Self-attention은 reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representation과 같은 분야에서 성공적으로 사용되어져 왔다.
End-to-end memory network은 순서에 따라 정렬된 recurrence가 아닌 recurrent attention mechanism을 기반으로 하고있고, 좋은 성능을 보여주고 있다.
Transformer은 처음으로 RNN을 사용하지 않고 오로지 self-attention만이 쓰인 첫번째 변역 model이다.
요약 : Sequence한 문제에서의 모델
RNN의 단점 : 병렬화의 어려움으로 인한 계산의 복잡도 증가, train 시간의 증가,
(그리고 강의에서 만약 sequential한 데이터중 중간에 어느 하나가빠진다면 해결하기가 어렵다고 했다)
CNN의 단점 : 병렬적인 계산은 이루어 지지만, input이나 output의 길이가 증가할수록 계산도 많고 단어간의 관 계파악이 빡셈
따라서 Attention만 쓴 Transformer 짱
3. Model Atchitecture
가장 경쟁력이 좋은 neural sequence transduction model은 encoder-decoder 구조를 가지고 있다. Encoder은 입력 sequence를 x = (x1,….xn)으로 표현하였고 이를 z = (z1,….zn)으로 map한다. 주어진 z로 decoder가 output sequence인 (y1,…,ym)을 생성해 낸다.(보통 중간의 latent 층은 input과 output에 비해 작은 dimension을 가진다고 조교님께서 설명) 각 step마다 model은 auto-regressive하며, 문장을 생성할때 이전에 생성된 symbol을 additional input으로 가정한다.
※ Auto regressive 복습
(고정된 길이인 $\tau$만큼의 시퀀스만 활용하는 경우 Autoregressive Model(자기회귀모델)이라고 부른다
직전과거의 정보랑 직전정보가 아닌 정보들을 Ht로 묶어서 활용)
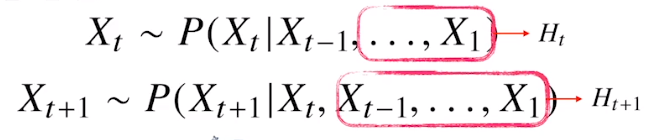
Transformer은 stacked된 self-attention을 사용하고 있고, encoder와 decoder부분에 모두 fully connected layer를 삽입하였다.
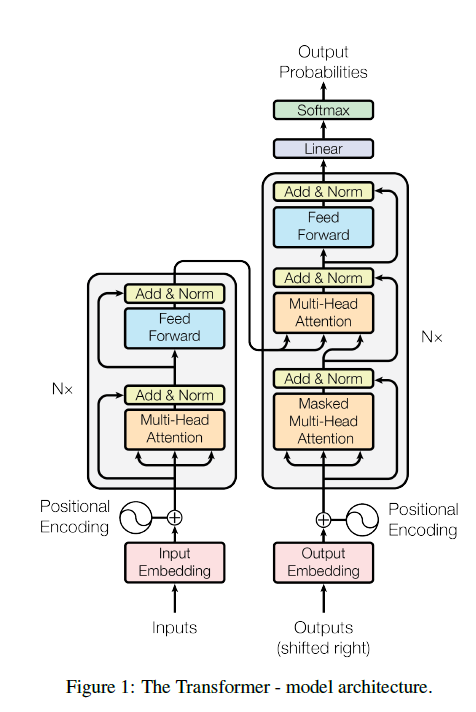
3.1 Encoder and Decoder Stacks
Encoder : encoder은 N=6 (6개)인 각각의 identical한 layer들이 층층이 쌓여있다. 각각의 layer들은 2개의 sub-layer로 구성되어있다. 첫번째는 Multi-Head Attention이고, 두번째는 간단한 fully-connected된 feed-forward network이다.
우리는 각각의 sublayer에 residual connection을 들어 주었다.
※여기서 과연 residual connection을 넣은 이유가 뭘까? overfitting 방지 like ResNet??
각각의 sub-layer의 output은 LayerNorm(x + Sublayer(x)). 모든 sublayer model과 embedding layer의 output의 차원은 dmodel = 512 이다.
Decoder : Decoder또한 N=6인 각각의 identical한 layer들이 층층이 쌓여있다. Encoder의 2개의 각 sub-layer에 Decoder은 encoder stack의 output에 대한 multi-Head attention을 수행하는 층이 추가가 되었다.
Encoder와 같이 sublayer에 residual connection을 만들어 주었다. 하위 position이 attend하는것을 방지하기 위해 self-attention-layer을 약간 수정하였다**(이게 masking). 이 masking은 i위치의 예측이 i보다 과거의 것으로만 구해지게 하기 위함이다.**
※ Masking은 NLP 문제에서 굉장히 많이 쓰인다고 한다. 알아두자
3.2 Attention
Attention function은 query와 set of key-value pair들을 output에 mapping하는 함수이다. (query,key,value,output은 모두 vector). Output은 value들의 weighted sum으로 계산하며, 이 weight는 query와 다른모든 key값들의 compatibility function으로 정해진다.
※여기서 compatibility function이란?
뒤에서 sum의 형태와 dot product로 나누어 진다. 이들의 차이점은 뒤에 기술
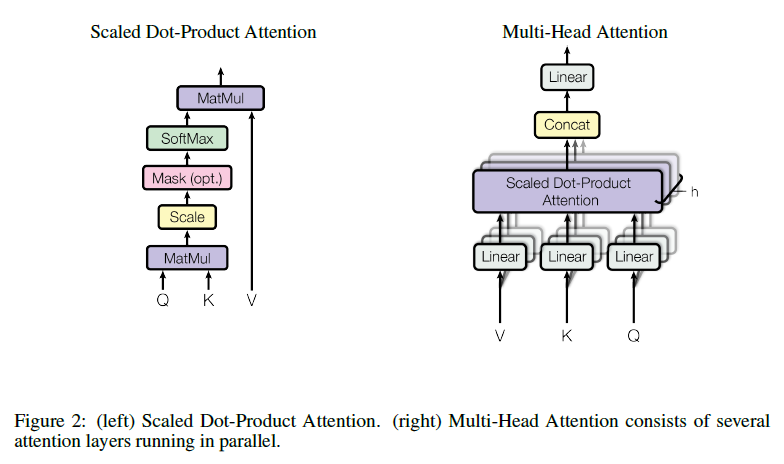
3.2.1 Scaled Dot-Product Attention
우리는 이러한 attention을 “Scaled Dot-Product Attention”이라고 부른다. Input은 dk의 차원을 가지는 keys와 queries(둘은 연산(내적)을 위해 같은 차원을 가진다)와 dv의 차원을 가지는 values로 이루어져 있다. 우리는 하나의 query 를 다은 모든 keys들과 내적하고(이 결과 값이 바로 강의에서 score) sqrt(dk)로 나누어 준다. 이후 softmax function을 적용하여 value의 weight를 얻어낸다.
※ i번째 단어에 대한 score vector 계산시 i의 쿼리 vector와 다른모든 key vectors 사이의 내적 (Matmul)
위의 과정들을 queries들을 Q matrix, keys and values를 각각 K and V라고 한다면 아래의 식으로 표현가능
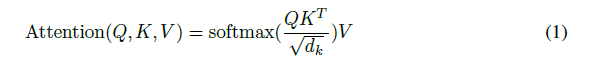
가장 많이쓰는 attention function의 함수는 additive attention과 위와 같은 dot-product attention이다. 우리는 dot-product attention을 썼다.
Additive attention은 하나의 hidden layer와 feed forward network를 사용하여compatibility function을 계산한다. 이두가지는 복잡도 측면에서 비슷하지만, dot-product attention이 더빠르고 공간 절약적이다.(이유는 행렬의 계산으로 표현가능)
작은 값을 가지는 dk에서의 두 mechanism은 유사하겠지만, 큰 dk로 나누어 주지 않으면 additive attention이 dot-product의 성능을 넘는다. 큰 dk는 dot -product는 큰값을 가지게 되고, 이는 softmax function이 매우 작은 gradient를 가지게 한다. 이러한 영향을 줄이기 위해 sqrt(dk)로 나누어 주었다. (scale)
3.2.2 Multi-Head Attention
dmodel(max sequence)의 차원을 가지는 keys,values,queries으로 이루어진 single attention을 수행하는것이 아니라, 우리는 queries, keys, values들에 각각 h번 dk,dk,dv를 곱하여 project한값이 더욱 좋은것을 알아내었다.
이러한 projection을 거치면 attention function을 병렬적으로 수행 할 수있으며, dv의 차원을 가지는 output을 얻어낼 수 있다. 이 output은 다시 하나로 concatnated되어 projected된다.

Multi-Head Attention은 서로다른 위치에서의 서로다른 subspace의 표현을 jointly attend 하게 한다.
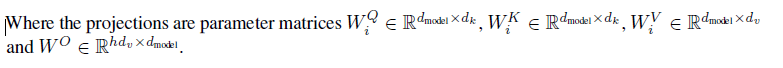
우리는 h = 8개의 parallel attention layer을 사용하였고,dk,dv,dmodel/h = 64
각각의 head에서 차원을 줄임으로서 전체적인 계싼비용이 single head attention과 비슷하게 만들었다???????
※ 한마디로 이제 dmodel의 차원을 h만큼 parrel layer에 나누어서 넣었으니 결국 single head attention과 비슷하다는 이야기인가??
3.2.3 Applications of Attention in our Model
Transformer은 multi-head attention을 3가지 다른 방식으로 사용하고 있다
“Encoder - Decoder attention” layer에서 queries는 이전의 decoder layer에서 오고, encoder의 output에서 오는 key와 value들을 저장한다. 이것은 input sequence의 모든 position들을 모든 position의 decoder가 attend 하게 해준다.
한마디로 decoder을 쿼리만 들고있어도 된다.
Self attention layer를 포함하는 encoder. Self attention layer에서는 이전 encoder의 layer의 결과에서부터 나온 위치와 같은 위치에서 모든 key, values, and queries가 나온다. encoder속의 각각의 위치들은 이전 encoder의 이전 layer의 모든 위치에 집중한다. (모든 현재 layer의 위치가 이전 layer의 모든 position 정보들을 가진다? 이런느낌?)
비슷하게 decoder의 self attention layer또한 모든 decoder안의 모든(자기자신까지) position에 집중한다.Auto regressive 특성을 보존시키기 위해 왼쪽의 정보들이 decoder로 flow in 하는걸 막아주어야 한다. 우리는 이러한 걸 scaled dot product attention안의 softmax의 output 값에masking out함으로서 해결한다
이걸 다시한번 생각해 보아야 겠다
Auto regressive한 특성이란 이전의 정보들 만으로 현재값을 도출해내는 특성
그니까 결국은 위에(1)식에서 softmax의 결과값에 미래의 정보들은 모두 masking 해준다는것이다.
그니까 결국엔
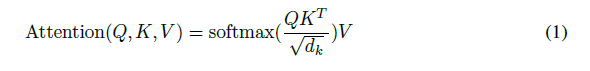
이식에서 미래의 정보들까지 K와 Q의 내적결과가 다담고 있으니까 미래의 정보는 마스킹 해준다.
3.3 Position-wise Feed Forward Networks
encoder와 decoder안의 각 layer에는 fully connected feed forward network를 가져야 한다. 이 fully connected feed forward network는 각각의 위치에 독립적으로 따로 적용된다
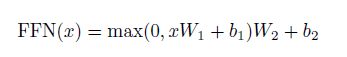
위식을 보면 2개의 linear transformation과 ReLU activation을 그사이에 사용하였다.
Linear transformation을 각각의 position에 같은 걸 적용해야 한다. 그리고 layer과 layer사이에는 다른 parameter를 적용해야 한다. 또다른 방법은 1의 kernel size를 가지는 2개의 convoltion을 사용하는 것이다.
※ 그니까 하나의 layer에는 같은 weight를 적용하고 다른 layer사이에는 다른 weight를 적용한다는 뜻???
dmodel = 512
inner-layer’s dimension dff = 2048
3.4 Embedding and Softmax
여타 다른 번역 모델과 같이 여기서도 학습된 embadding을 사용했다.
Decode되어 나온결과도 학습된 linear transformation과 softmax함수를 사용하여 다음 token의 확률을 계산하였다.
embedding layer들에는 같은 weight와 presoftmax linear transformation을 사용, weight의 결과에 sqrt(dmodel)을 사용했다.
3.5 Positional Encoding
우리의 model은 recurrence도 없고 convolution도 없어서 각각의 model이 sequence의 순서를 사용하게 하여면 position 정보를 삽입해 주어야 한다.
따라서
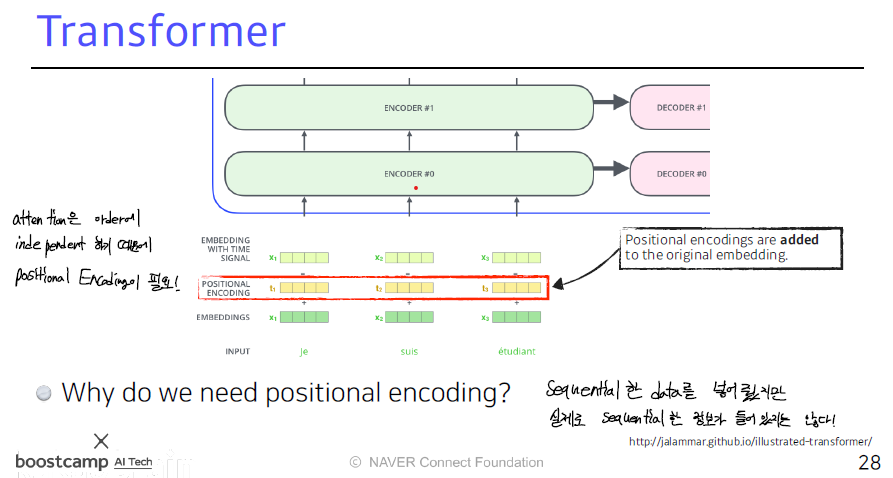
이와 같이 각각 embedding된 vector에 positional encoding된 vector를 더해준다
이 연구에서는 cos과 sin 함수를 사용했다
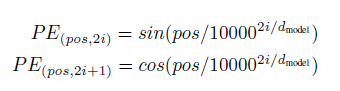
pos 는 position i는 차원
각각의 위치가 sinusodial하게 encoding 되도혹 하였다. 주기가 조올라 길어서 다른위친데 주기성 때문에 같은 값을 가지는 경우는 드물다
4. Why Self-Attention
이 부분에서는 self attention layer를 RNN과 CNN에 더욱 자세히 비교한다.
앞에서 설명한거에 대한 보충설명
한 layer에서 계산 복잡도에서의 이득
병렬화 될 수 있는계산의 총량
길이가 기이이일어졌을때 얼마나 network에 영향을 미치는지
길이가 졸라리 길어졌을때 dependencies는 매우 중요하다. 이에 가장 중요하게 미치는 영향중 하나가 signal하나가 network를 순회하는 길이이다?? 이게 짧아질수록 긴 길이에 대한 상호적인 관계가 더 잘 학습된다. 따라서 각 model마다 model에서 input과 output 사이의 거리? 뭐하이튼 그 얼마나 model이 compact한가

위 table을 보면 computational한 성능을 높이기 위해 self attention 모델은 해당하는 output 위치의 오직 size r 만큼의 input sequence 주위를 고려하도록 제한되어있다.
이거에 대한 연구는 추후에 발표하겠다고 적혀있다. 그럼 이미 나와있겠지?
하이튼 위에꺼 비교해보면 모든 측면에서 self attention이 와따
5. Training
1. Training data and batching
WMT 2014를 사용하여 train함
그리고 문장은 target vocab와 37000개를 공유하는 byte-pair encoding이라는 방식을 사용했음
각 traning batch는 25000개의 source token과 25000개의 target token을 포함하는 문장의 set으로 정해주었다.
2. Optimizer
Adam을 썼고, lr을 단계적으로 변화시켰다.아래와 같은 수식으로
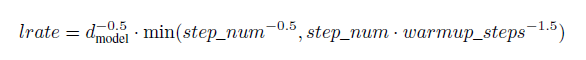
3. Regularization
Residual Dropout
더해지고 normalized 되기전에 각각의 sublayer의 output에 dropout을 적용하였다
그리고 또 embedding된 vector와 position의 합이후에도 적용하였다
P
drop은 0.1Label Smoothing???
이런걸 적용했다고 하느네 이게 약간 예측불가능한걸 더해줘서 model이 더 새로운것을 배우게끔하는 거라하는데 걍 간단하게 나와있다
6. Results
BLEU score 잘나왔다 어쩌구 저쩌구 하다가
base model에서는 5개의 checkpoint를 만들어서 그것의 평균을 낸 하나의 model을 썼고, 각 check point는 10분마다 한번씩 interval을 주었다.
이게 내가 조교님한테 질문했던 부분과 좀 연관성이 있다. 이렇게 중간중간에 model을 기록하고 평균을 내는 방식도 있구나
그리고 이 beam search를 사용하였다고 한다
이건 이전의 논문들을 읽을때도 자주 사용했던 기법이다
간단하게 설명하면 가장 확률이 높은 K개을 선택하며 진행하는 것이다
greedy방법보다 효율적이고 score가 잘나온다고 들었다
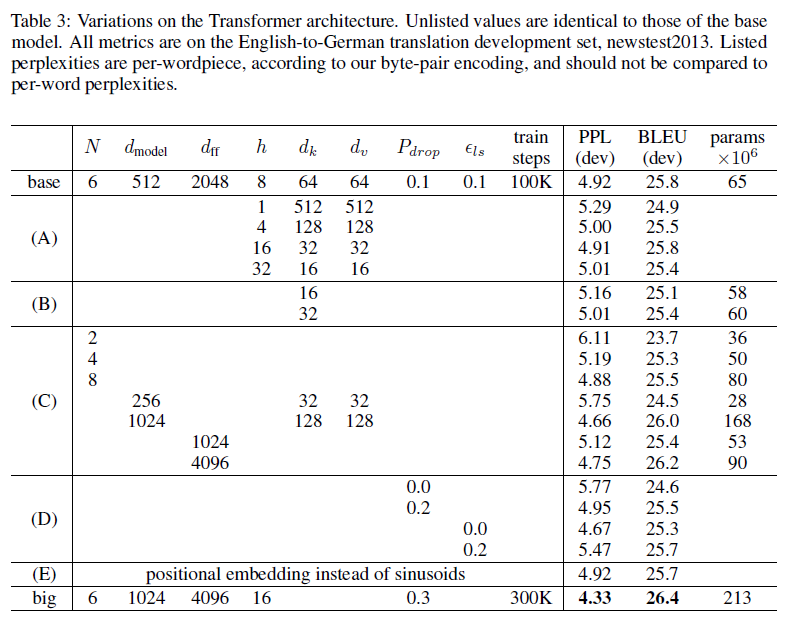
6.2 Model Variations
아래 table의 (A)를 보면 attention의 head의 개수와 key,value의 dimension을 변화시켜주었다. 너무 많은 head를 사용해도 안되고 하나만 사용해도 안됨
이건 너무 당연한거다 뭐든지 적당한게 좋다
6.3 English Constituency Parsing
이 Transformer를 활용한 model은 통역에서 나아가서 영어 구문을 분석해주는 방법으로 발전시켜나가야 한다.
이건 별로 중요하지 않은것 같다
해보니까 RNN보다 좋은 성능을 나타내었다 끝
7. Conclusion
결론
기존과 다르게 attention에만 기반을 둔 multi-headed self attention을 사용한 이 transformer은 다른 RNN이나 CNN보다 성능이 빠르며 이 Transfomer를 더욱큰 input과 output을 가지는 image나 비디오 오디오 등에적용시키는 것을 기대하고 있다.
Transformer 짱짱맨
그리고 조교님께서 관심 있으신 Neuroscience와 Attention사이의 관련
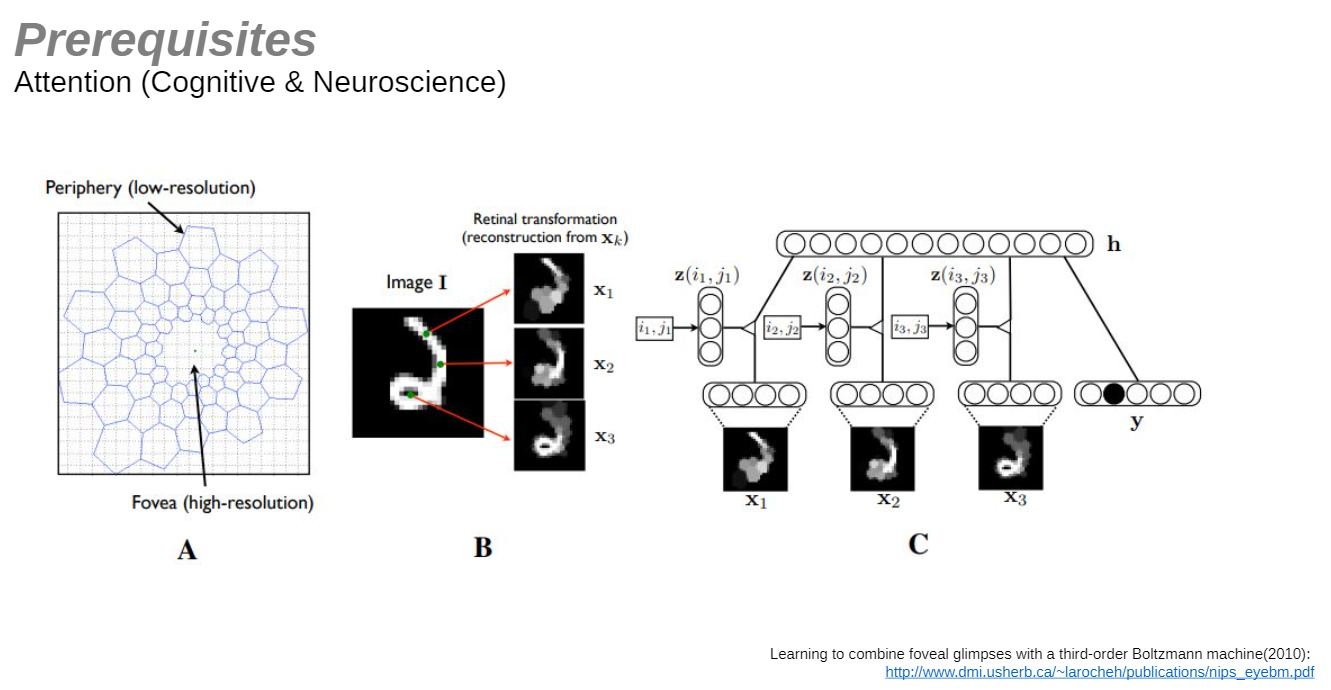
보면 우리 인간의 황반에서도 이 attention의 개념을 적용해서 사물을 인지하고 있으니, 잘되는게 어찌보면 당연하다
출처 : https://arxiv.org/pdf/1706.03762.pdf
그리고 naver boostcamp
Attention Is All You Need
https://jo-member.github.io/2021/02/05/2021-02-05-Attention/