Generative Models
Generative Models
- What I can not create, I do not understand
https://deepgenerativemodels.github.io/
Introduction
- What does it mean to learn a generative model
- generative model은 단순히 생성모델이 아니다
Suppose we have some images of dogs
We want to learn a probability distribution p(x) such that
Generation : If we sample x
new~ p(x), xnewshould look like a dog- implicit models
Density estimation :p(x) should be high if x look like a dog (어떤이미지의 확률을 계산함)
이건 마치 image classification
- explicit models
Unsupervised representation learning
특정 image가 어떤 특징을 가지고있는지를 학습
How can we represent p(x)??????
Bernoulli distribution
D = {Heads, Tails}
Specify P(X = Head) = p, P(X = Tails) = (1-p)
Categorical distribution
ex) Modeling and RGB joint distribution
- (r,g,b) ~ p(R,G,B)
- number of case = 256x256x256
- parameters = 255x255x255 개가 필요
하나의 RGB pixel만해도 parameter를 표현하려면 어마어마한 숫자의 parameter가 필요하다
Structure Through Independence
What if X1,….,Xn are independent and binary pixels
p(x1,…,xn) = p(x1)p(x2)…p(xn)
possible state : 2^n^
parameter : n개만 필요
만약 각각의 pixel이 독립적이라고 가정한다면 이렇게 parameter수가 줄어든다
근데 이건 너무 말이 안된다
따라서 Independence와 fully dependent사이의 절충안???
Conditional Independence
Three Important Rule

n개의 joint distrubution을 n개의 conditional distribution으로 바꾸고
z가 주어졌을때 x,y는 independent하다 ->이게 가정 완전 xy가 independent한게 아니라 z가 주어졌을때
y는 상관이없다 이런느낌
Conditional Independence
Using the chain rule
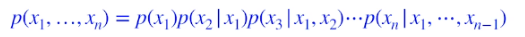
이 수식 도출에서 어떠한 수학적인 가정이 없이 chain rule만으로 구한 수식이다 따라서 fully independent와 parameter 개수는 같다
p(x1) :1개
p(x2|x1) : 2개 (one per for p(x2|x1 = 0) and p(x2|x1 = 1))
p(x3|x1,x2) : 4개
Hence 1+2+2^2^+…+2^n-1^ = 2^n^-1
i+1번쨰 pixel은 i번째 pixel에만 dependent하다 가정 : markov assumption
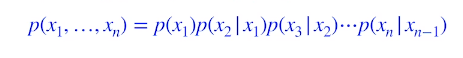

그 중간에 있는 걸 conditional independence를 잘 활용해서 중간의 parameter값을 얻어냈다
Auto-regressive Model
suppose we have 28x28 binary pixels
goal : p(x) = p(x1,x2….,x784)
how can we parametrize p(x)
use chain rule to get joint distribution
p(x
1:784) = p(x1)p(x2|x1)p(x2|x1:2)……이게 바로 auto-regressive model (i번째 pixel이 1~i-1까지 모든 history에 dependent한)
가장 중요한게 순서를 매기는 과정
이미지에 순서???? —-> 순서에 따라 성능이나 방법론이 달라질수 있다
NADE : Neural Autoregressive Density Estimator
- p(x
i|x1:i-1) =
i번째 pixel을 1~i-1에 dependent하게 만든다 —–>
dependent 하다 ? 1-i-1번째 pixel값을 입력으로 받고 network를 통과시켜서 나온 output에 sigmoid를 통과해서 확률이 나오도록하는것
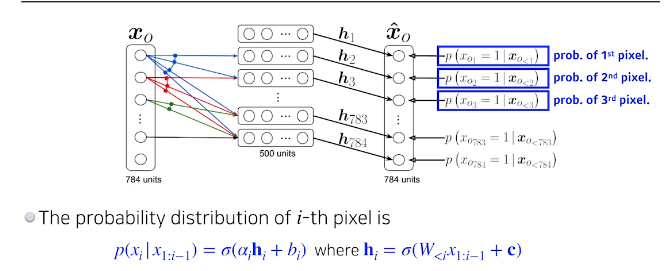
neural network의 weight의 차원값은 지속해서 늘어남이전입력들이 계속해서 늘어나기 때문에
- NADE is explicit model
- Suppose we have 784개의 binary pixel
알고있는 값들을 집어넣은뒤 계산하게 되면 확률값이 나옴
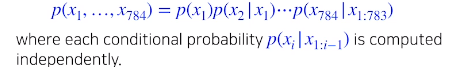
Density estimate : 확률적으로 무언가의 확률을 explit하게 계산한다
Continous한 r.v를 modeling할때는 Gaussian이 사용이 된다
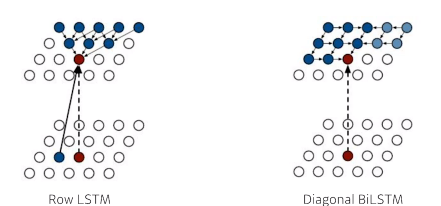
Pixel RNN
- Use RNNs to define an auto regressive model
- 이전에 봤던 NADE는 dense layer을 사용함 하지만 Pixel RNN은 RNN을 통해 generate한다
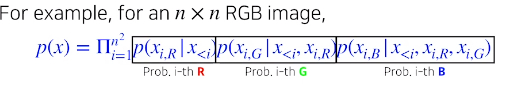
ordering의 순서에 따라
Row LSTM
Diagonal BiLTM
Latent Variable Models
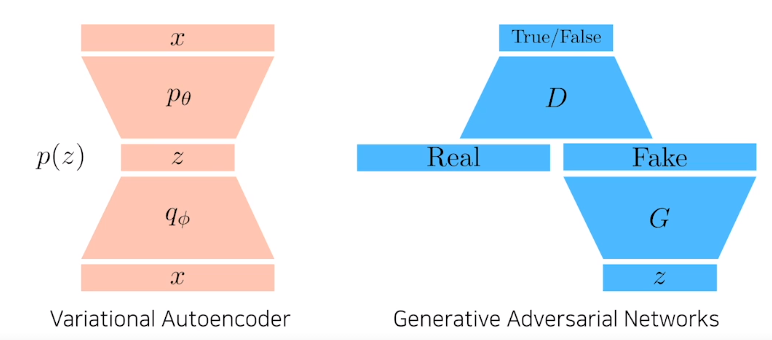
Variational Auto-encoder
Is an autoencoder generative model??
autoencoder은 input을 재정의하는 과정이지 generative model은 아니다
과연 무엇때문에 Variational Auto-Encoder은 generation 모델인가?
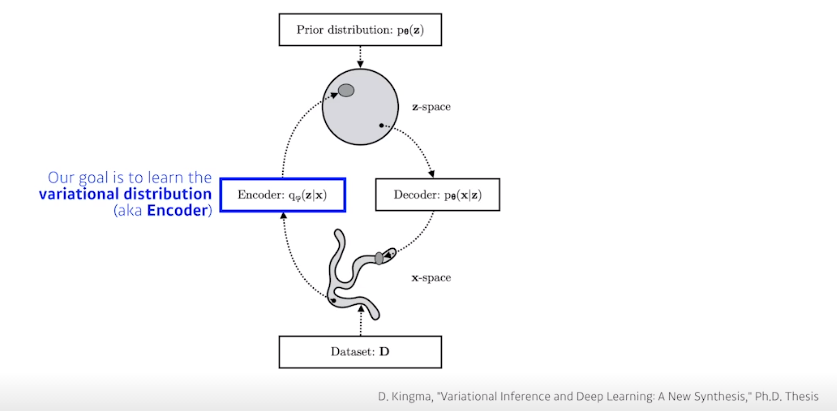
Variational inference (VI)
- The goal of VI is to optimize the variational distribution that best matches the posterior distribution
posterior distribution : observation이 주어졌을때 내가 관심있어하는 r.v의 확률분포
- posterior distribution을 계산하는건 매우 힘들기 때문에 Variational distribution을 근사한다
KL divergence를 사용해서 Variational distribution과 Posterior distribution의 차이를 줄여보겠다
How?
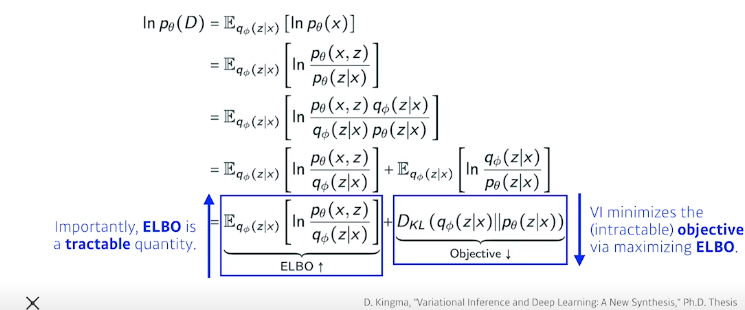
원해는 KL divergence를 줄이는게 목적이지만 이게 불가능하기 때문에 ELBO라고 불리는 term을 최대화 한다
ELBO can further be decomposed into

Reconstruction Term
x라는 입력을 latent space로 보냈다가 Decoder로 돌아오는 Reconstruction loss를 줄이는 term
Latent space에 올려놓은 점들이 이루는 분포가 Latent space의 prior distribution와 비슷하다? implicit한 model
Decoder이후의 output domain의 값들이 generation result이다
Auto encoder은 이게 아니라 generation model이 아니다
Key limitation
- Interactable model (hard to evaluate likelihood)
- reconstruction term은 상관없는데 KL divergence를 사용한 prior distribution에는 무조건 미분이 가능한 distribution (like Gaussian)을 사용해야 한다. 따라서 diverse한 latent prior distributions에는 사용을 하기에 힘들다
- In most cases, we use an isotropic Gaussian
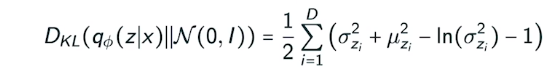
Adversarial Auto-encoder
It allows us to use any arbitrary latent distributions that we can sample
Prior fitting term을 gan을 사용하여 분포를 맞추어줌
sampling이 가능한 어떠한 분포도 맞출수있다는 장점이 있다
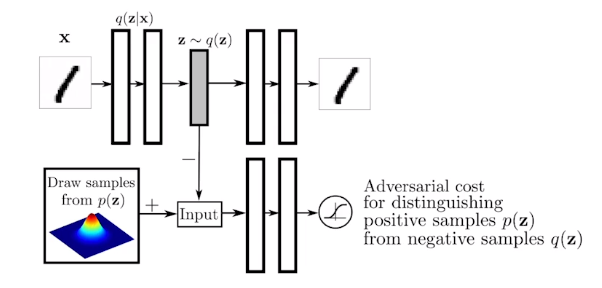
GAN
discriminator가 점차 발전해 나가면서 generator도 따라서 성능이 올라가는 상생의?
GAN vs VAE
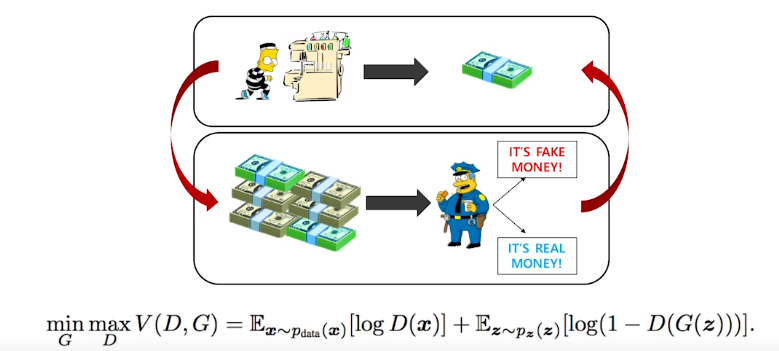
GAN의 Objective
For discriminator
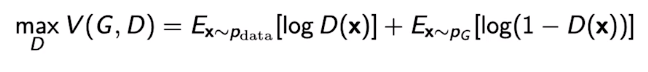
where the optimal discriminator is
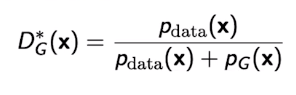
For generator

GAN의 objective는 나의 true generative distribution과 내가 학습하고자하는 generator사이의 Jenson-Shannon Divergence를 최소화 하는것이다
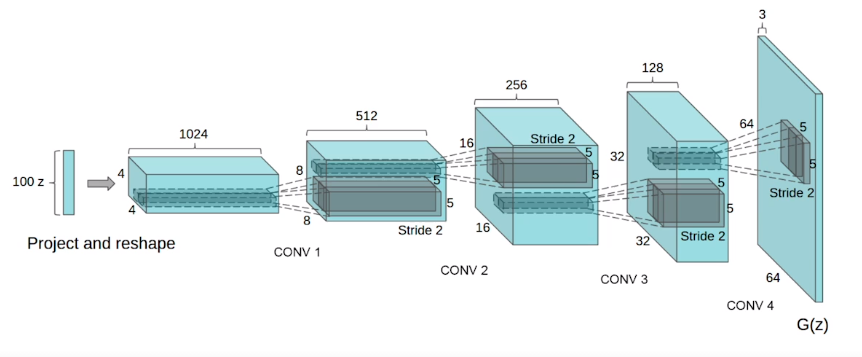
DCGAN
Info-GAN
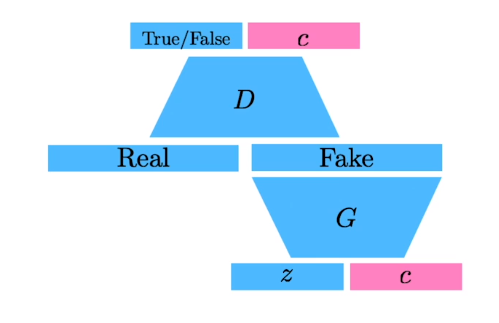
학습시에 class라는 random한 one-hot vector를 매번 집어 넣어준다
generation시에 gan이 특정모드에 집중할 수 있게끔해준다
Text2Image

텍스트로 이미지를 generate하는 연구
model이 매우 복잡하다…….
CycleGAN
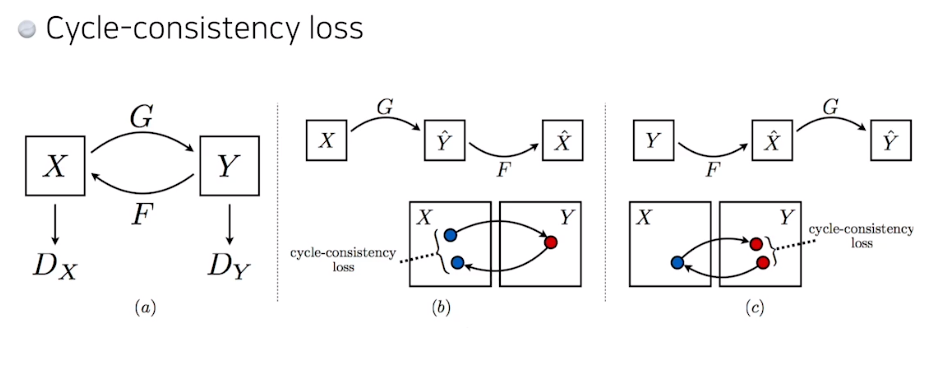
이 cycle consistency loss가 매우 중요하다
Generative Models
https://jo-member.github.io/2021/02/05/2021-02-05-Boostcamp15.1/