Improving Language Understanding by Generative Pre-Training
이번에는 openai에서 발표한 논문인 GPT를 review해보겠다
GPT3는 이전에 review한 transformer구조를 활용하여 Language understanding을 효과적으로 만들었다.
Abstract
자연어를 이해는 text추론, 질문에 대한 대답, 의미의 유사성 평가, 문서분류등을 포함하고 있다. 라벨링 되지 않은 text들을 매우 넘처나지만, 특정 task의 학습을 위해 labed된 text들은 매우 적기때문에 좋은 모델을 학습시키는것은 매우 힘들다. Language 모델을 unlabled된 text로 generative pretrain을 한이후 각각의 task에 맞게 fine-tunning을 하였다. 이러한 많은 unlabed text를 사용하여 학습하였다. 이전의 연구와는 달리,필요한 task에 fine-tuning하여 응용하는 것이 매우 효과적이다.
1. Introduction
Raw text를 사용하여 효과적인 NLP 학습을 하기위해서는 지도학습에 대한 의존성을 완화해야 한다. 많은 딥러닝 방법들은 labeled된 data를 사용해야 해서 한계가 존재한다. 이러한 상황에서 unlabed된 data는 시간과 노력이 필요한 annotation을 모으는 작업들을 대체할 수 있다. 만약 고려가능한 지도가 가능한 상황이라면, unsupervised 방법은 model의 성능을 증가시킬 수 있다. 이러한 방식은 pretrained된 word embedding을 사용하여 성능을 높이는것과 비슷한 이유이다.
unlabed된 data로 word-level의 정보보다 많은 정보를 활용하는것은 2가지 이유에서 매우 어렵다
- 어떠한 종류의 optimization objective가 가장 효과적으로 text를 표현할수 있을까 가 매우 unclear하다
- 우리가 원하는 특정 task에 효과적으로 적용하는 방법에 대한 의견이 일치가 되징 않았다. 현재 존재하는 방법은 model에 특정한 task-specific한 변화를 가하는 것과, 복잡한 학습방법,그리고 학습을 도와주는 몇몇 learning objective들을 넣어주는, 이러한 방법들의 combination이다
이러한 불확실성은 language processing에서의 효과적인 semi-supervised learning을 발전시키기 힘들게 만든다.
이 논문에서는 unsupervised pre-training과 supervised fine-tunning을 조합한 방법을 사용하여 semi-supervised approach를 하였다. 목적은 가장 보편적으로 학습하여 약간의 응용으로 다양한 분야에 적용시키는것이다.
2-stage로 나누어 train하였다
- 초기 parameter를 학습하기 위해 unlabeled data를 사용하여 pre-train 하였다 / with transformer
- 우리는 이 parameter들을 특정한 task에 맞는 supervised objective 학습에 사용하였다.
또한 model에서 Transformer를 사용하여 long-term dependencies를 해결하였다.
2. Related Work
Semi-supervised learning for NLP
우리의 work는 Semi-supervied learning의 범주안에있다. 이 ssl은 sequence labeling, text 분류등에 쓰이면서 큰 관심을 받고 있다. 가장 초기에는 unlabeled data를 supervised learning의 feature로 사용하여 word나 phrase level의 통계를 계산하는데 사용되었다. 최근 몇년동안 word-embedding이 얼마나 좋은지 밝혀냈다. 이러한 접근은 word-level의 정보를 특정한 high-level에 맞추어 준다. 최근에는 word-level이 아닌 phrase나 sentence level의 embedding을 사용하여 text를 다양한 target task의 vector representation을 나타내 주었다.
Unsupervised pre-training
Unsupervised pre-training은 supervised learning을 바꾸는거 보다는 좋은 initialization을 찾는게 목적이다. 각각의 연구들은 image classification과 regression task의 기술이 사용되었다. Pre-training은 정규화 과정에서 generalization성능을 올려준다.
우리의 연구는 language modeling으로 model을 pre-train한후 task에 맞게 fine-tuning해주는 것이다. Pre-training이 언어적인 정보를 잘 잡아낼수 있지만,이전연구에서 사용된 LSTM을 사용하는 것은 긴 data를 해석하지 못한다는 단점이 존재한다. 따라서 우리는 Transformer를 사용하였다.또다른 연구에서는 몇몇 보조적인 feature들을 삽입해주어 성능을 향상시켰지만, 이는 새로운 parameter의 증가를 야기한다. 우리의 GPT는 transfer과정에서 최소한의 수정만을 필요로 한다.
Auxiliary training objectives
여러 보조적인 unsupervised training은 semi-supervised learning의 대채적인 형태이다. 이전의 연구에서는 다양한 종류의 보조적인 NLP방법론(POS tagging, chunking,등등등)을 사용하였다. 최근 또다른 연구는 보조적인 language model를 추가하여 sequence labeling의 성능향상을 이야기 하였다.
3. Framework
학습과정은 2개의 stage로 나누어져 있다
- unlabeled된 큰 말뭉치를 사용하여 가장 범용적인 language model을 학습하는 stage
- 이후 labeled data를 사용한 fine-tuning stage
3.1 Unsupervised pre-training
unsupervised의 token들 = 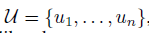 이 주어지고, 이어지는 likelihood를 maximize하기위해 보편적인 language model을 사용한다.
이 주어지고, 이어지는 likelihood를 maximize하기위해 보편적인 language model을 사용한다.
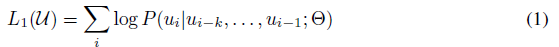
k는 context의 size이고, conditional prob P는 NN을 사용하여 modeled
이들은 모두 SGD를 사용하여 training했다.
multi-layer Transformer decoder를 사용했다.
이 model은 input context tokens에 multi-headed self-attention을 활용하였고, 이후에 position-wise feedforward layer를 적용하여 target token에대한 output distribution을 구한다.
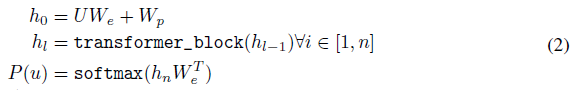
U는 token의 context vector이고, n은 layer의 숫자, We는 token embedding matrix, Wp는 position embedding matrix이다.
3.2 Supervised fine-tuning
model을 train한후, supervised target test에 맞추어서 parameter를 적용한다. labeled된 dataset C(각각은 input token의 sequence로 이루어짐 ((x^1^,…,x^m^) and label y ))
Input은 pre-trained된 model을 통과하여 최종 transformer block의 activation인 hl^m^을 얻어내고, 이후에 linear output layer에 Wy와 함께 들어간다.
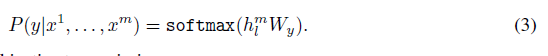
이는 이후의 objective를 maximize하게 한다.
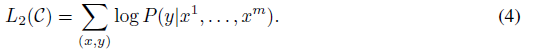
보조적인 장치로 language modeling을 사용하여 fine-tuning을 하는것은 (1) generalization성능을 높힌다 (2) 수렴속도를 높힌다. 우리는 아래의 objective를 optimize한다
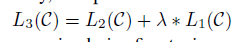
Fine-tuning중에 유일한 extra parameter은 Wy와 구분token을 위한 embedding이다.
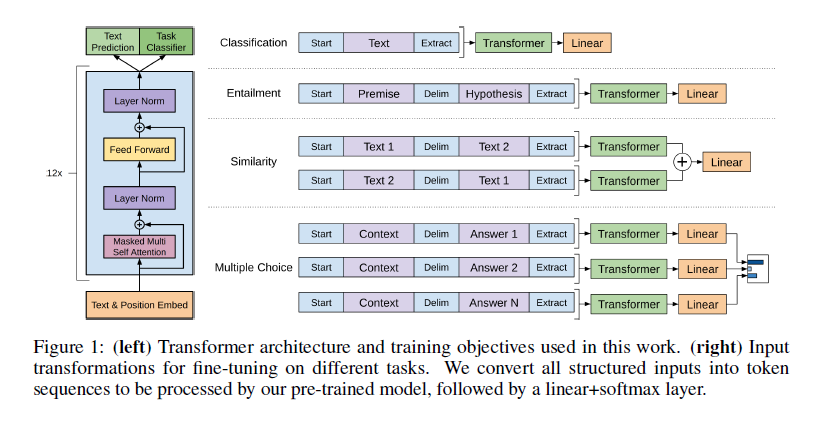
3.3 Task-specific input transformations
text classification가 같은 몇몇 분야에서, 위에서 묘사했던대로 우리의 model을 fine-tune할 수 있었다. 질의응답과, textual entailment와 같은 문제에는 input을 ordered sentence pairs, triplets of document, question, answer으로 해주었다. 우리의 pre-trained model이 연속적인 sequence에서 학습되었기 때문에, 이러한 문제들에는 약간의 맞춤 수정이 필요하다. 이전의 연구들은 transffered representation위에 특정 architecture를 삽입하는 형태로 학습해왔다. 이는 많은양의 cutomization이 필요하며 이러한 추가적인 특정 architecture에는 transfer learning을 사용하지 않았다. 대신 우리는 traveral-stple approach(input을 정렬된 sequence로 만들어)를 사용하여 우리의 pre-trained model이 학습할 수 있게 하였다. 이러한 input의 조정은 문제상황에 따라 architecture의 큰 수정을 하지 않아도 되게 한다. 모든 transformation은 randomly initialized된 start,ending token을 포함한다.
- Textual entailment(문장의 포함관계) : 전제 p와 가설 h 중간에 delimiter token $를 삽입하여 합쳐주었다.
- Similarity (문장의 유사도 평가) : 두개의 비교대상은 순서가 딱히 없다. 한마디로 동등한 level에서 비교해야 되기 때문에 모든 가능한 순서를 사용하고 transformer이후에 나오는2개의 h
l^m^ 을 합쳐준다. - Question Answering and Commonsense Reasoning (질의응답) :
3. Model Atchitecture
language model -> label이 필요가 없다
주어진 단어들을 가지고 다음단어를 예측하는
Generative model
Generative model
data가 많아 질수록 정확도가 높아진다
Discriminative model
타이타닉같은
데이터가 많지 않을때 패턴파악이 쉬워서 많이들 사용한다
한정된 data에 과적합 되기가 쉽다
sample된 data로는 왜곡된 판단을 할 수 있다
GPT는 unlabeled된 data로
Pretraining LM
finefuning
데이터만 task관련데이터로 학습 model은 그대로
Naural Language Inference -> entailment contradiction파악
질의응답
비슷한 문장 판별
주어진 문장을 그룹으로 분류하는
비지도 학습 label이 있는 data로 fine tunning한다.
기존 language model 학습 공식과 같다
transformer의 decoder로 구성
layer추가없이 pretrained LM
byte pair embedding을 사용하였다
신조어 오탈자에 약한 word embedding이 아닌
byte pair. —–> hack,able, deep, learn, ing
이런식으로 embedding을 하였다.
data가 주어졌을떄
Improving Language Understanding by Generative Pre-Training