RNN심화1
RNN
서로다른 time step에서 들어오는 입력 데이터를 처리할때, 매번 반복되는 동일한 rnn module을 호출한다. image-20210216103443317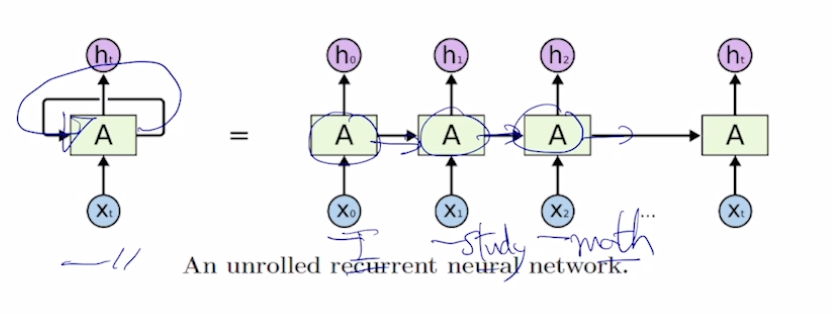

각 단어별로 품사를 예측해야 되는 경우 -> 매 time step마다 y를 output으로
어떠한 문장의 긍부정을 판별하는 경우 -> 최종 time step의 y만이 output으로
모든 time step에서 같은 parameter W를 공유한다
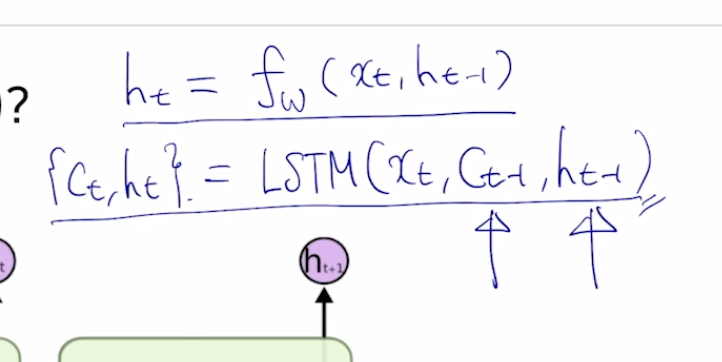
주어진 vector가 3차원의 입력벡터로 주어졌을때 ht-1은 2차원이라고 가정하자
x image-20210216111255186t와 ht-1를 같이 입력으로 받아서 fW에 넣어주면, ht가 나오게 된다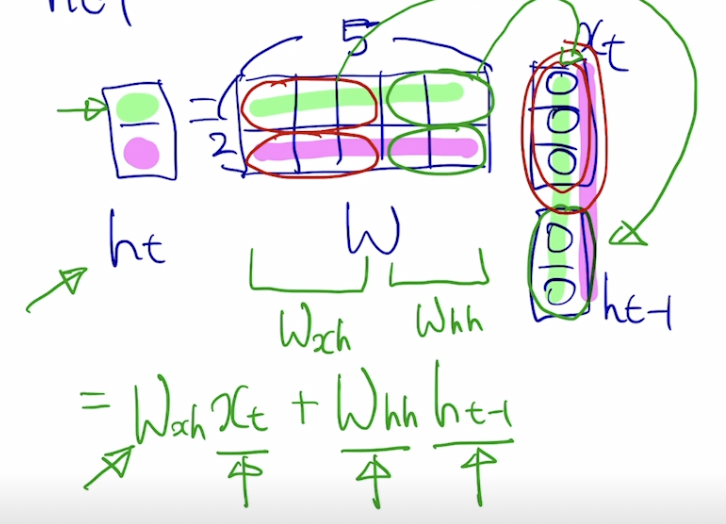
현재 timestep t에서추가적인 outputlayer를 만들고 ht에 Why를 곱해서 yt를 얻어낸다.
Types of RNN
One-to-one
입출력 모두가 sequence data인 경우에 입출력이 단 1개인
one-to-many
image captioning에서 이러한 구조를 띈다.
초기에 입력이 한번 들어가고 이후 입력으로는 0으로 채워진 tensor를 입력으로 주게된다
many-to-one
최종값을 마지막에서야 내주는
ex) I love movie에서 RNN이 처리한후 마지막의 ht를 봄으로서 긍부정을 예측하게 된다. 길이가 달라진다면 RNN CELL이 그만큼 확장이된다
many-to-many
- ex) machine translation
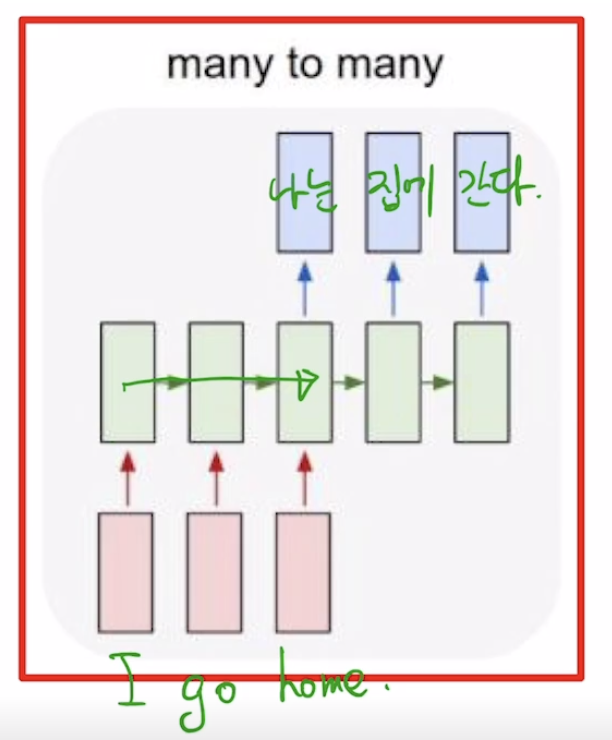
image-20210216120729609
- Ex) POS, vidio의 frame이 sequence대로 주어질때
Character-level Language Model
- Example of training sequence “hello”
- vocab = [h,e,l,o]
- 각각의 character은 one-hot-vector로 표현이 가능하다
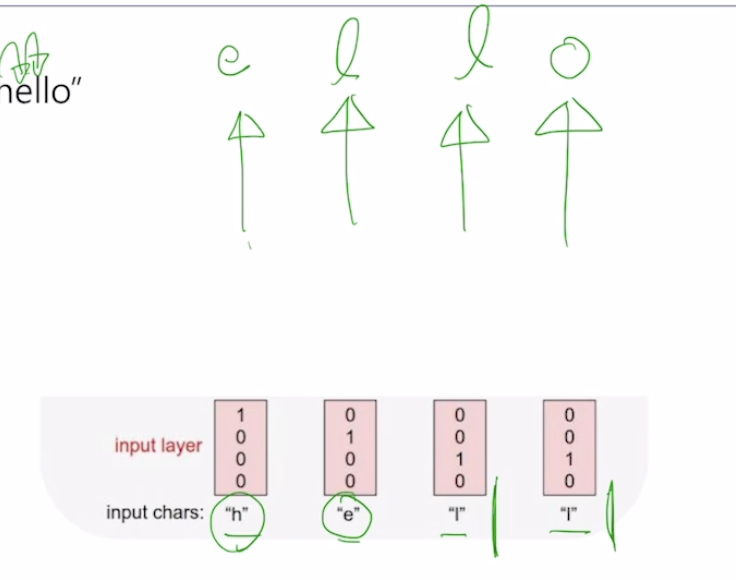
image-20210216121012818
Back propagation through time (BPTT)
Whh,Why,Wxh 와 같은 parameter들을 학습한다
sequence전체를 한번에 학습하기에는 physical적인 한계가 존재하기 때문에 군데군데 짤라서 제한된 길이의 sequenc 만으로 학습을 진행한다
매 time step마다 hidden state vector가 거의 모든 정보를 담고 있다. 그렇다면 만약에 hidden state의 차원이 3차원이라면, 우리가 원하는 정보가 그중 어느 node에 담겨져 있을까? 이걸 역추적. 첫번째 ht의 node를 고정해 놓고 이후의 변화들을 봄
정작 지금까지 배운 vanila RNN은 잘 활용하지 않는다. 이유는 만약 긴거리에 있는 정보가 매우 중요할 경우 back propagtion으로 구해지기 때문에 gradient vanishing이나 gradient explode가 일어나게 된다.

gradient값이 증폭되고있다
LSTM & GRU
Long short-term Memory
보다 효과적으로 long term dependency를 처리할수 있게끔하기 위해
ht를 단기 기억소자로 생각할 수 있으며, 이러한 단기기억을 얼마나 길게 끌고갈 것이지를 판별해주는 역할들을 가진 gate들로 이루어져 있다
전 time step에서 넘어오는 정보가 2가지의 서로다른 vector가 들어오게 된다.
위에 들어오는 vector : Ct
아래쪽에 들어오는 vecor : ht
Ct-1 이전 cell state와 이전 state의 hidden state를 입력으로 받아 현재의 cs와 ss를 내준다. Hidden state vector은 cell state vector중에 노출되는 정보를 담은, 한번 필터링 된 vector이다.
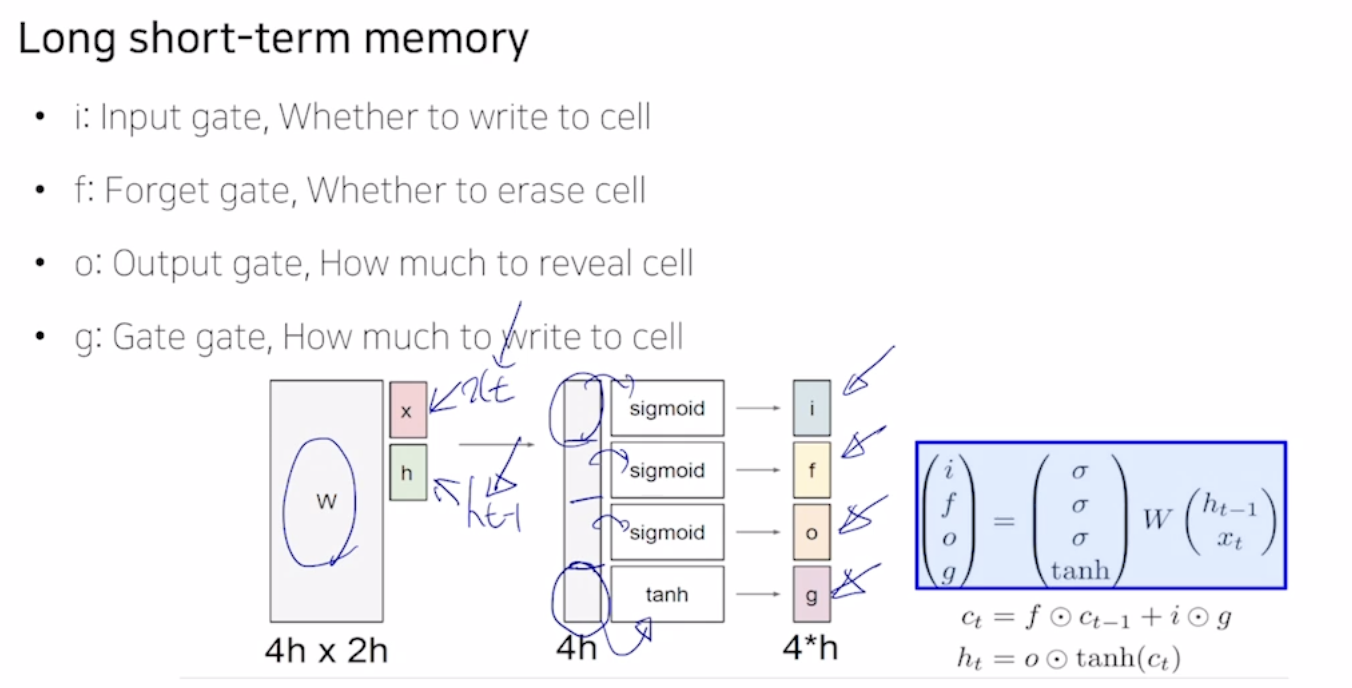
여기서 sigmoid의 결과와 곱해지면 얼마만큼 이전의 원래값을 반영할지를 결정하는 역할을 한다. 마지막 tanh를 통해 나오는 값은 현재 time step에서 LSTM에서 계산되는 유의미한 정보라고 생각할 수 있다.
Forget gate
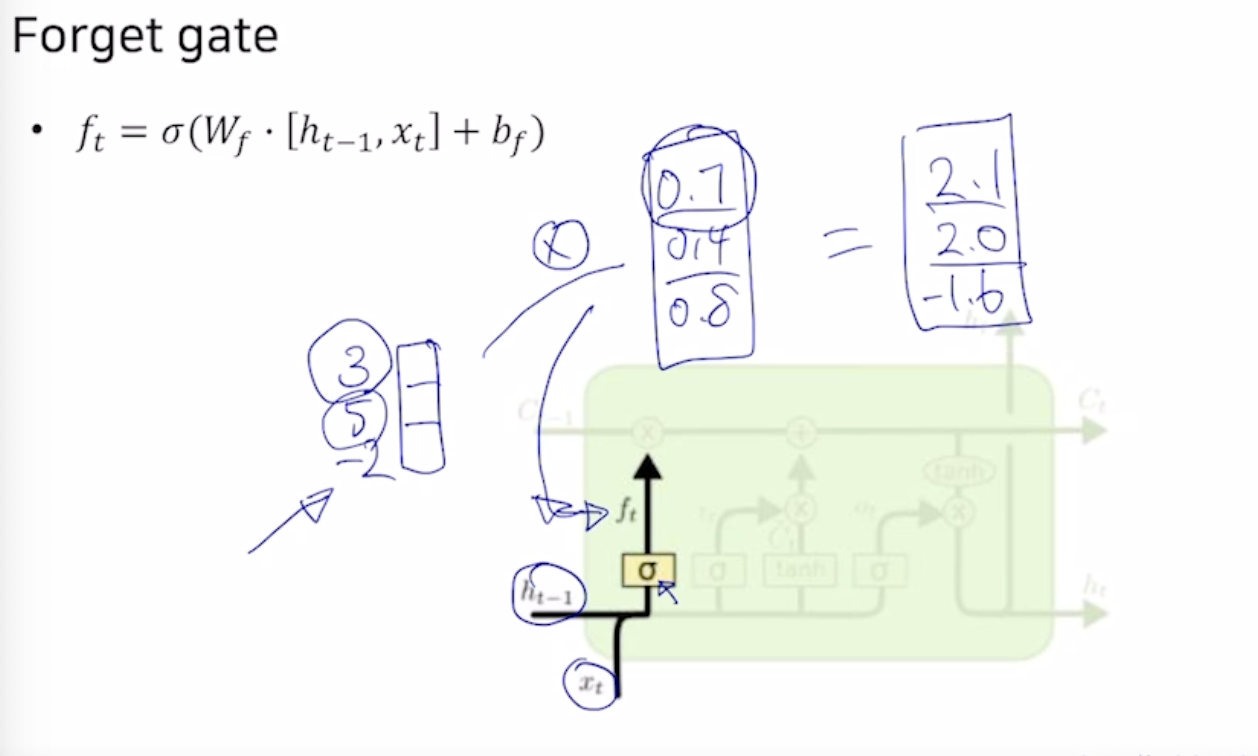
위를 보면 이전의 hidden state와 현재의 xt를 입력으로 받아 sigmoid 적용후 3차원의 vector가 나오게 되었다. 이렇게 나온 vector와 이전의 cell state의 element wise product를 해주어서 이전의 cell state를 얼마만큼 반영할지를 게산해 주었다.
- Gate gate
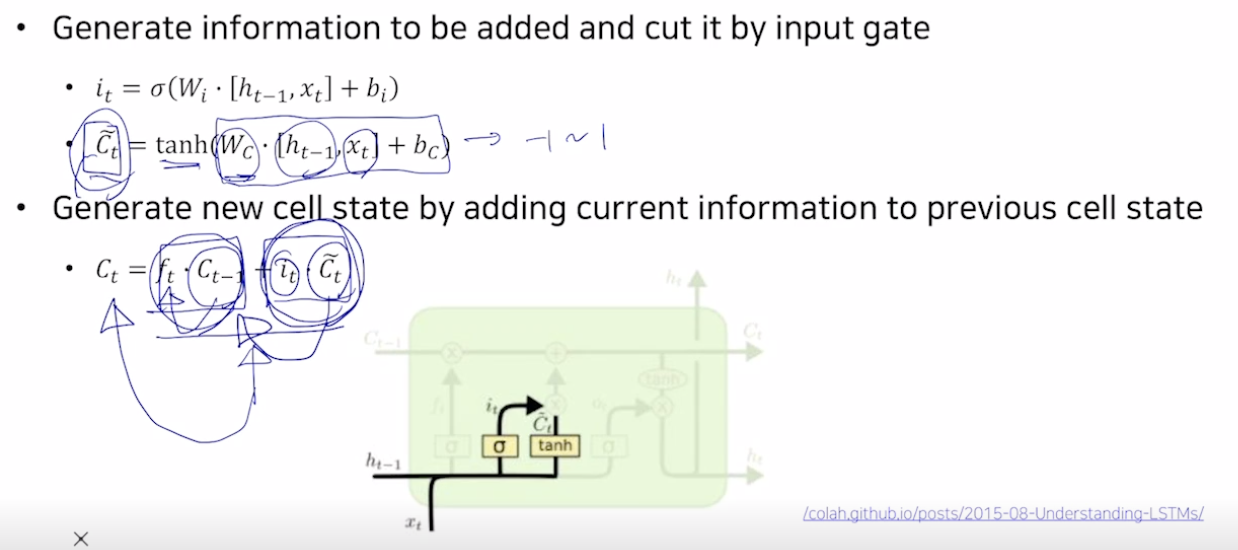
Ct에 더해주어야 하는 값을 바로 더해주지 않고 it를 곱해서 더해준다
- Output gate
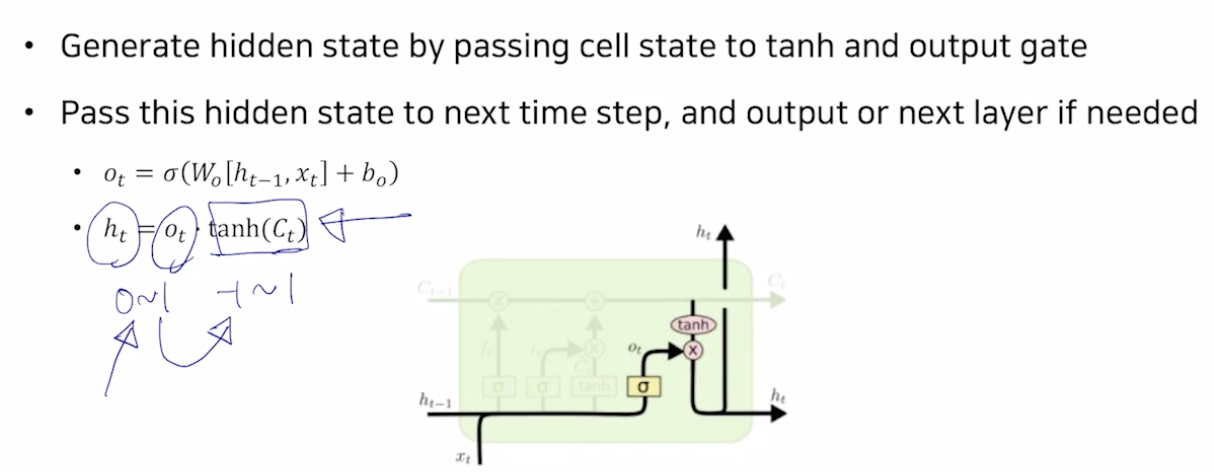
이제 cell state vector Ct로 hidden state vector ht를 만들어준다. 앞서 sigmoid를 적용한 값또한 tanh를 거친 Celll state에 곱한값에 곱해주어 적절한 비율만큼 값을 작게 만들어주어 최종적인 ht를 만들어주게 된다.
ht는 다음 rnn의 hidden state로 들어가는 동시에 현재 time step에서 예측을 수행할때 이걸 output layer에 넘겨주어 예측값을 생성해 낸다
GRU
LSTM에서 2가지 종류의 vector로 존재하던 cell state와 hidden state vector를 일원하 하여 하나의 vector만이 존재하게 한다는게 특징이다. 하지만 전체적인 동작원리는 거의 비슷
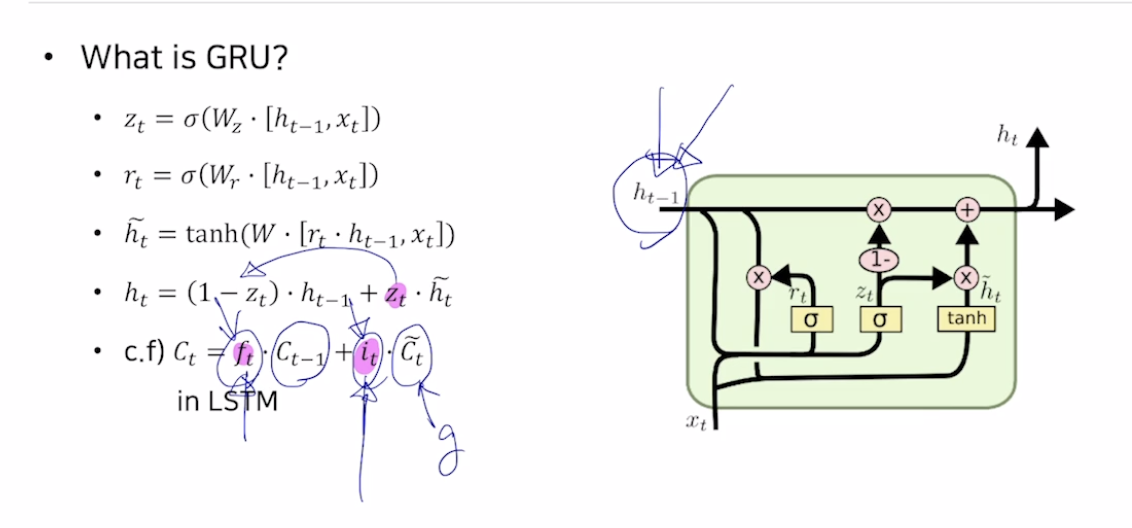
forget gate대신 1-zt를 사용, it대신 zt를 사용
input gate가 커질수록 forget gate의 값이 점차 작아지게 되어 결과적으로 이전 hidden state vector를 더 적게 반영하는 것이고, vice versa
- hidden state를 일원화 하였다
- 2개의 독립된 gate를 통하여 동작되었던 model을 하나의 gate만으로 줄여 계산량과 메모리 사용량을 줄였다.
정보를 주로담는 cell state가 update되는 과정이 행렬의 계속적인 곱의 연산이 아니라 그때그때 서로다른 gate를 거쳐가며 update되기 때문에 gradient vanishing이 사라진다. 덧셈연산은 이전의 state를 복사해주어 gradient를 유지하는 역할을 한다고 볼 수도 있다. RNN은 다양한 길이를 가질수 있는 유연한 형태의 deep learning구조.