Sequence to sequence with Attention
Sequence to sequence
\
Seq2Seq Model
Ex) Are you free tomorrow?
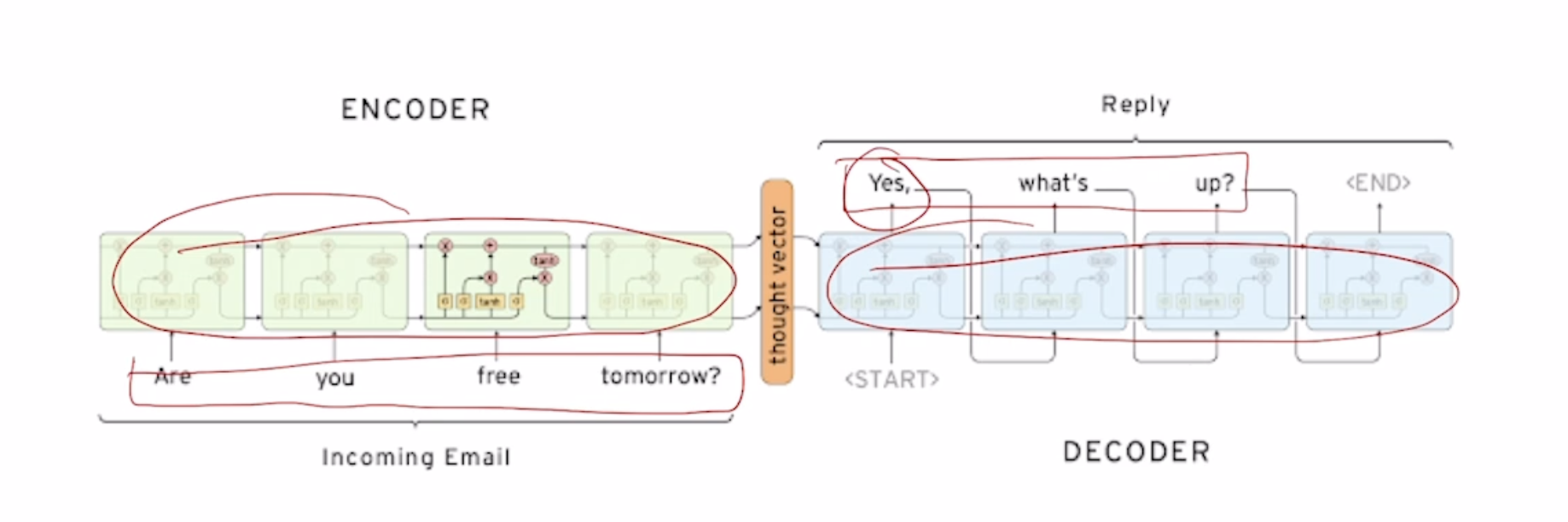
서로 paramter를 share하지 않는 2개의 별개의 RNN model을 (보통 LSTM) 쓴다. 각각의 RNN을 Decoder, Encoder로 사용한다.
Encoder의 마지막단의 output을 vertorize 시켜준후 decoder의 input에는 SOS token, hidden state에는 encoder의 output을 넣어준다.
Seq2Seq with Attention
앞에서의 RNN을 사용한 model은 hidden state vector의 dimesion이 정해져 있어서 입력문장의 길이가 길어지면 마지막 time step에 있는 hiddenstate vector에 앞서 나왔던 많은 정보들이 잘 담겨져 있지 않다.
아무리 이 LSTM에서 longterm dependency를 해결하려 해도구조상의 문제 때문에 해결하기에 매우힘들다
따라서 이러한 문제를 해결하기 위해서 seq2seq에서 Attention을 활용할 수 있다. Attention은 encoder의 각각의 hidden state vector를 전체적으로 decoder에 제공해주고 decoder에서는 그때그때 필요한 encoder의 hidden state vector를 가져가서 사용한다
decoder의 hidden state vector가 encoder의 어떤 hidden state vector를 가져올지를 결정하게 된다. 이거는 각각을 내적해보아서, 내적에 기반한 유사도를 판별하게 되고 이결과를 softmax에 통과 시켜서 확률값을 얻어내고 이를 각각의 가중치로 사용하여 이들의 가중평균으로서 나오는 하나의 encoding vector를 얻어낼수 있다!!!!!! 이러한 가중평균으로 나온 하나의 vector를 우리는 context vector라고 부른다.
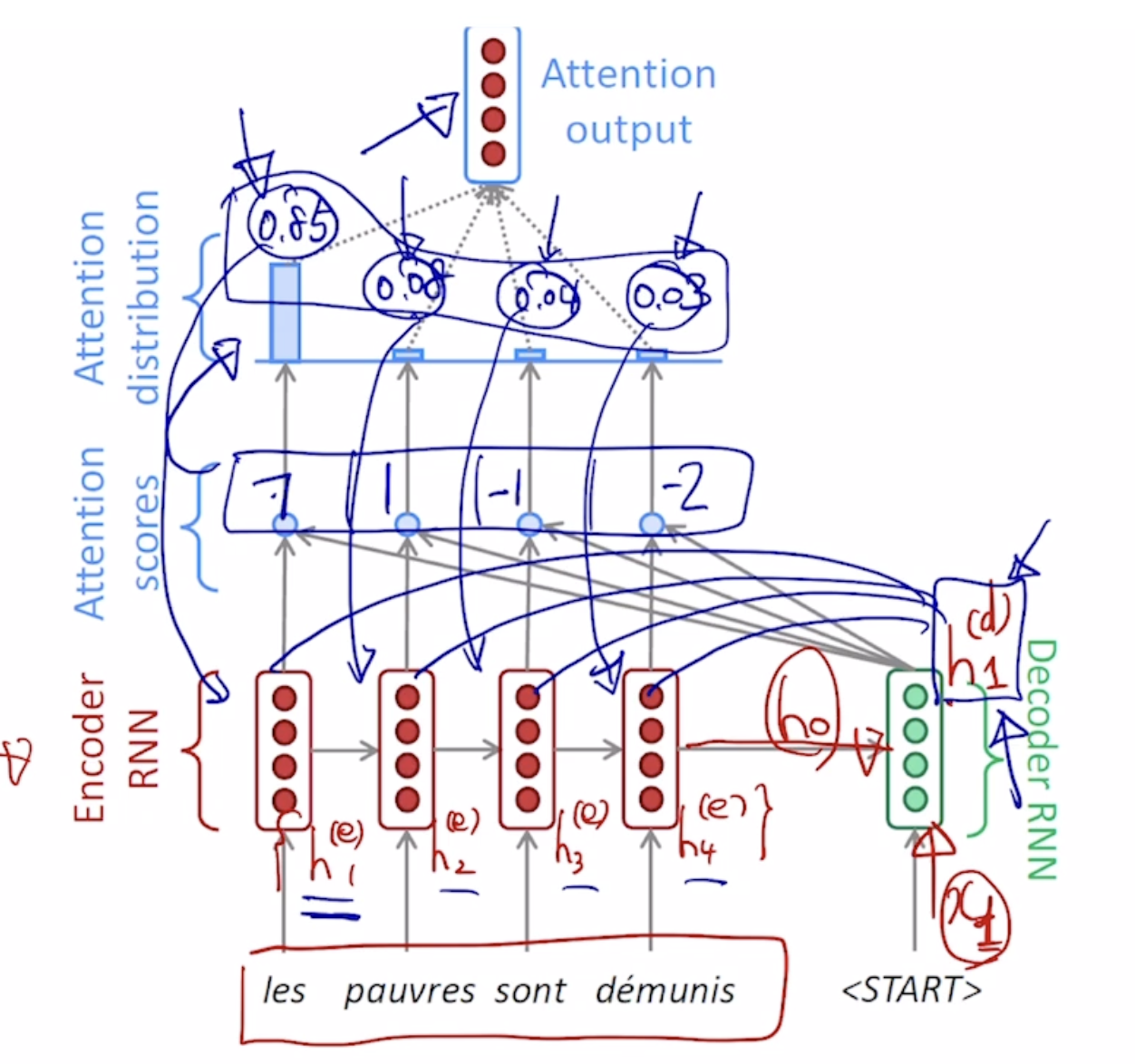
이후에 decoder hidden state vector와 context vector가 concatnate 되어 output layer의 입력으로 들어가게 되고 다음나올 단어를 예측할 수 있게 된다
이러한 과정들을 EOS가 나올때 까지 반복한다.
잘못된 단어를 전단계에서 예측을 하더라도 다음단계에는 올바른 ground truth를 넣어주기 떄문에 하나가 틀려도 이후가 망가지지 않는다. 학습이 끝난후 이 잘못된 단어를 다시 넣어준다. 또한 It’s teacher forcing.
Teacher forcing이 아닌 방식이 학습후에 우리가 실제로 사용할때와 비슷하다.
Teacher forcing때는 ground truth를 넣어주어야 하기 때문에학습속도가 빠르다
학습의 전반부에는 teacher forcing을 사용후 어느정도 학습이 되면, 이전의 output을 다시 입력으로 넣어주는 방식으로 진행한다.
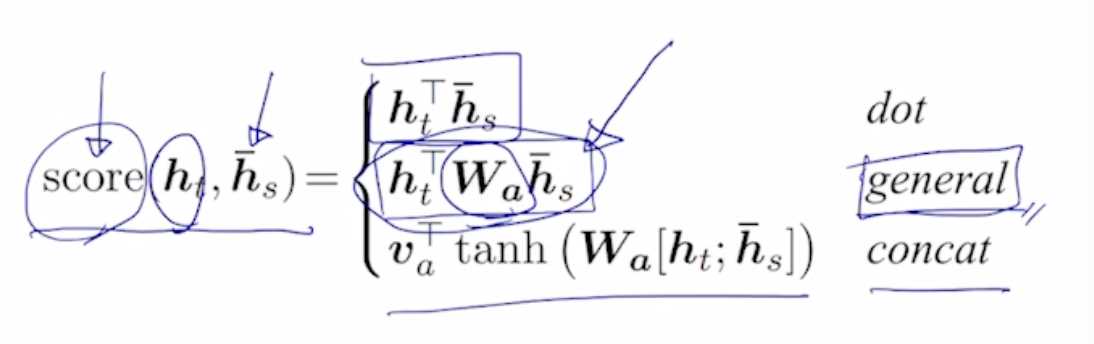
이처럼 유사도를 측정하는 과정에서 사용되는 내적은, 3가지의 종류로 계산해 낼 수 있다.
2번째인 general 방식으로 게산하는 것을 행렬으로 생각해보자.내적을 기반한 계산을 행렬의 곱으로 생각해보면,
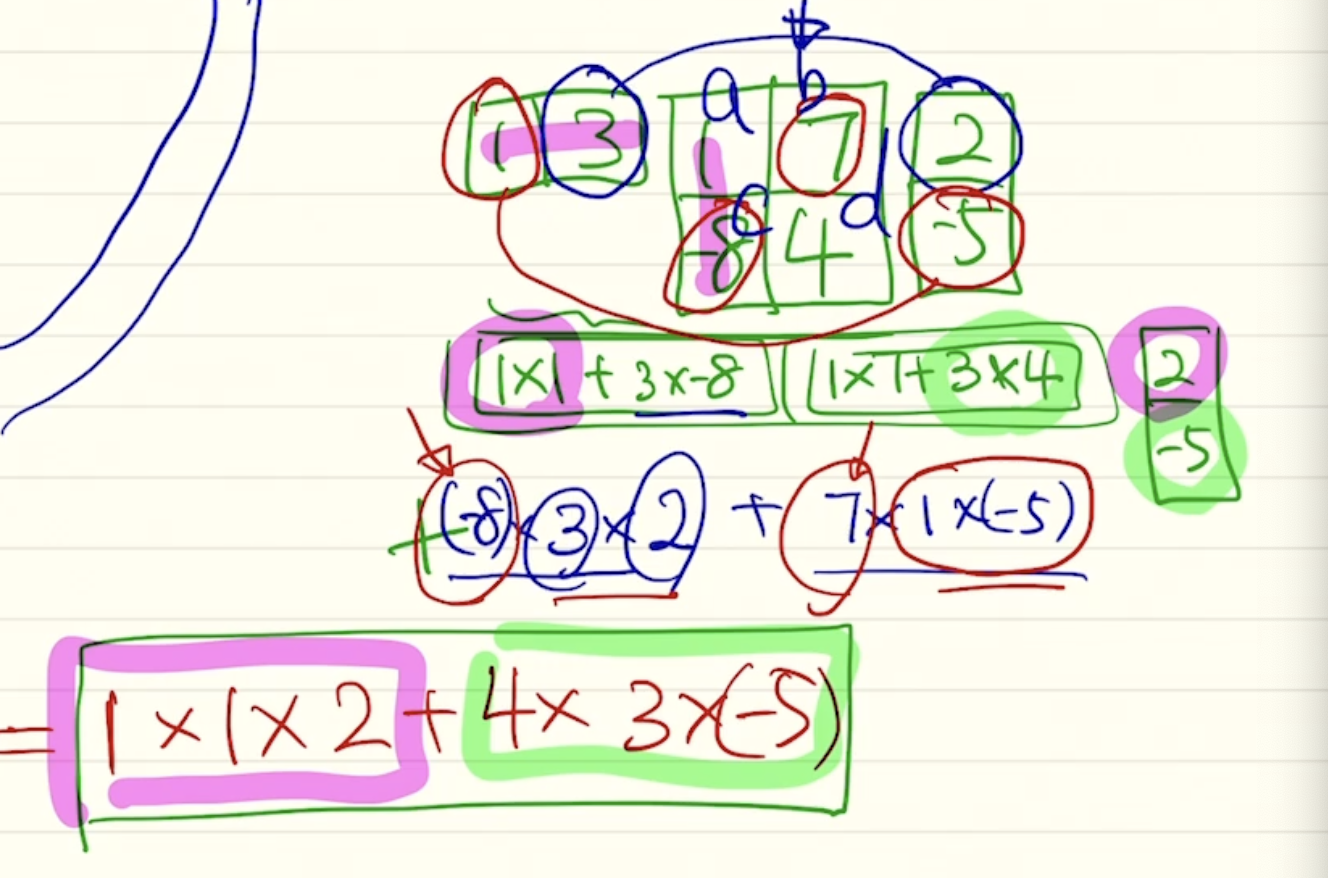
대각행렬의 성분들은 같은 차원끼리의 가중치를 나타내고, 나머지 값들은 다른 차원끼리의 곱해진 값들의 가중치를 나타낸다
이처럼 간단한 내적으로 정의된 형태의 유사도를 그가운데 학습가능한 parameter를 추가함으로서 새롭게 score를 계산했다.
이게 바로 general한 dot product이다.
다음으로 concat을 사용한 score 측정 방식을 보자
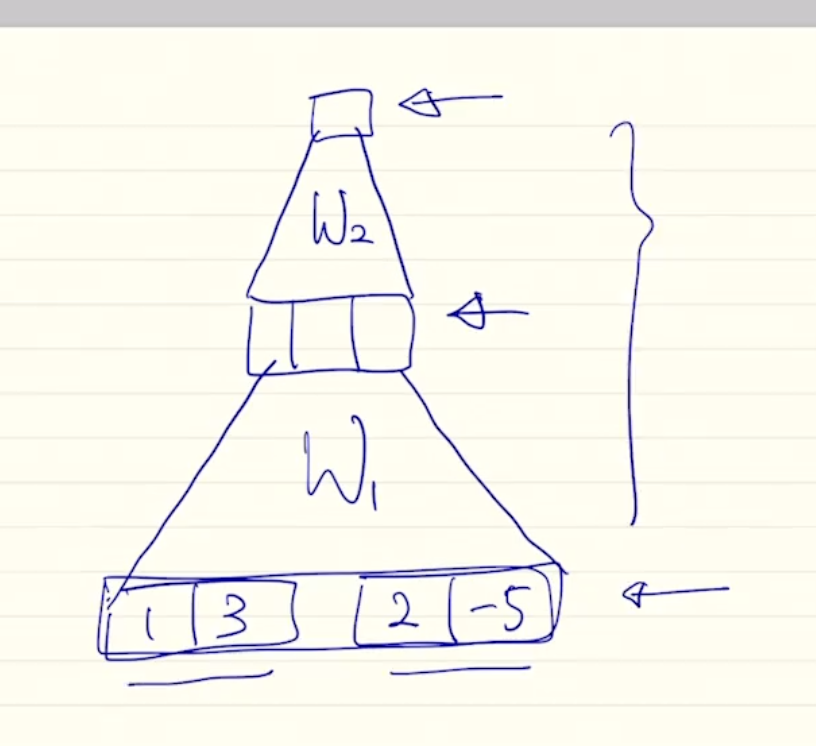
이처럼 2개의 vector를 concat시켜 MLP의 입력으로 넣어준 후 non linear activation function을 적용하여 값을 구해낸다.
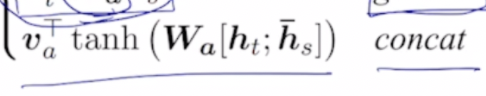
이수식을 간단하게 보면 Wa는 1번째 layer의 가중치, 그이후에 tanh를 적용한 후 v를 곱해주는데 이는 우리가 최종적으로 얻어야할 output이 scalar값이기 떄문에 v는 row의 형태를 띄어야 한다. 따라서 tranpose를 시켜준것을 확인 할 수 있다.
그렇다면 이들의 paramter은 어떠힌 방식으로 update될까?
결국은 이러한 유사도를 구하는데 필요한 parameter들또한 backpropagation을 통하여 선형변환 행렬들이 학습되게 된다.
Attention is great
Attention significantly impoves NMT performace
어떠한 한 부분에 집중할 수 있게 해주었다
It solves bottle neck problem
encoder의 마지막을 사용했어야 해서 생기는 long term dependency를 해결
Gradient vanishing의 문제를 해결하였다.
Attention provides some interpretability
우리가 transform과정에서 모델이 어떠한 부분에 집중 했는지를 확인 할 수 있다. Allignment를 NN이 스스로 배우는 현상을 보여주게 된다.
Beam search
- test과정에서 더 좋은 결과를 얻을수 있게 해주는 하나의 방법
Greedy decoding
가장 높은 확률을 가지는 단어 1개를 선택하는 방법
이렇게 되면 어떠한 단어를 잘못 생성해내었을때 다시 뒤로 돌아갈수 없어 최적의 예측값을 내지 못하게 된다
이를 해결하기 위해서 다양한 방법들이 제시된다
Exhaustive Search
첫번째 생성하는 단어가 가장큰 확률이였다고 해도 뒷부분에서 나오는 확률값 가장큰 확률값이 아닌 경우가 발생될수가 있다.
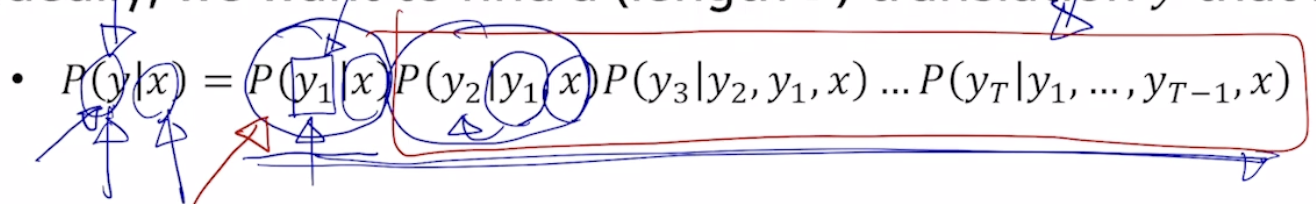
이는 결국 time step t 까지의 가능한 모든경우를 따져서 이는 곧 vocab가지수가 되고 V^t^가 가능한 모든 경우의 수이다. 이는 너무 큰 숫자이기 때문에 beam search를 쓰게된다
Beam search
매 time step마다 모든 경우의 수를 고려하는게 아니라, 우리가 정해놓은 k개의 가능하 가짓수를 고려하고 마지막까지 decoding을 진행한후 k개의 candidate중에서 가장확률값이 높은걸 선택하는 방식이다.
이를 우리는 hypothesis (가설)이라고 부른다
k는 beam size이 일반적으로 5~10으로 설정하게 된다.
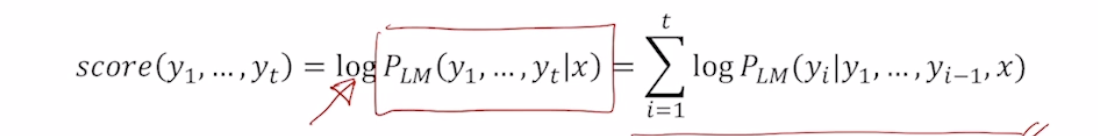
확률들의 곱셈 앞에 log를 붙이게 되면 곱들이 모두 덧셈이 된다. 여기서 log함수 단조증가이기 때문에, 큰값이 큰값을 가진다.
ex) k = 2
- k가 2이기 때문에 가장 확률값이 높은 2개의 단어를 뽑는다
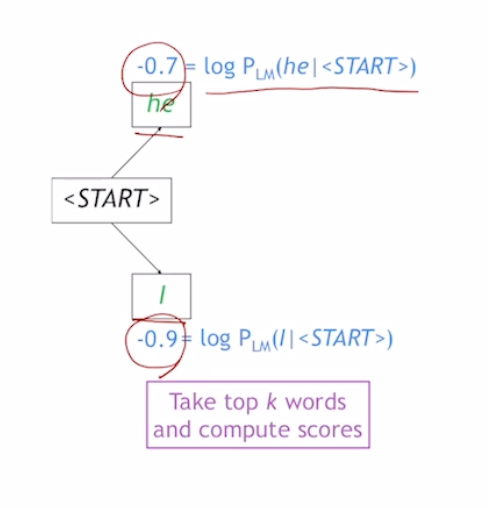
- 이중 값이 큰걸 계속해서 선택해 나감
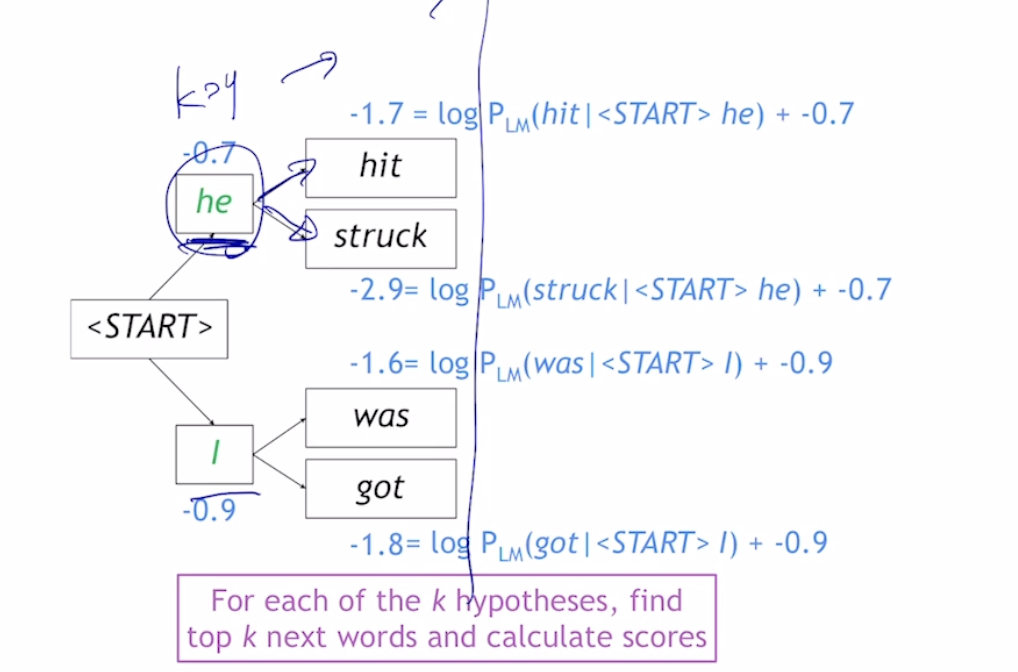
- greedy의 경우 end token이 나왔을때가 종료이지만, beam search에서는 서로다른 시점에서 end token이 생성되기 때문에, 각각이 끝날때마다 한곳에 저장해준다.
우리가정한 T라는 시간까지 수행하거나, 완료된 hypothesis가 n개가 되었을때 beam search를 중단한다.
우리가 고려하는 hypotheses의 길이가 다를때는 상대적으로 짧은 길이의 확률이 높은것이고, 길면 낮을것이다.
이를 고려해 주기 위해서는 각 joint prob을 문장의 길이로 나눔으로서 해결해줄 수 있다.
BLEU score
- 생성 model의 점수를 평가하기 위한 척도
- 고정된 위치에서 정해진 단어가 나와야 된다는 평가방식은 매우 나쁜 방식이다.
ex)
Reference : Half of my heart is in Havana ooh na na
Predicted : Half as my heart is in Obama ohh na
Precision(실제로 위치상관없이 겹치는 단어가 몇개인가) = #(correct words)/length_of_prediction = 7/9
Recall(재현률) = #(correct words)/length_of_reference = 7/10
F-measure = (precision x recall) / 0.5(precision + recall) (두 값들의 조화평균)
보다 작은 작은 값에 가깝게 구하는 방식 -> 조화평균
이렇게 구한 값들은 순서를 보장하지 않기 때문에 BLEU가 나왔다.
BiLingual Evaluation Understudy
Ngram이란걸 사용했다. 연속된 N개의 단어로 이루어진 문구를 matching하여점수로 반영하였다.
Sequence to sequence with Attention
https://jo-member.github.io/2021/02/17/2021-02-15-Boostcamp18.1/