Transformer심화
Transformer
Self-Attention
ex) I go home
I에 대한 input vector가 hidden state처럼 역할을 하여서
I와 각각의 단어에 대한 내적을 한후 이에대한 softmax를 구하여 가중평균을 구한다.
이렇게 encoding vector값을 구하게 되면 결국 자기자신과 내적한 값이 큰값을 가져, 자기 자신에 대한 특성만이 dominant하게 담길것이므로, 이를 해결해주기 위해 다른 architecture를 쓴다
각 vector들이 3가지의 역할을 하고있는 것이다. 동일한 set의 vector에서 출발했더라도 각혁할에 따라 vector가 서로다른형태로 변환할수있게해주는 linear transformation matrix가 있다.
한마디로 각각의 input이 서로다른 matrix에 적용이되어 각각이 key, quary,value가 된다는 의미이다.
I 라는 word가 서로다른 matrix에 따라 quart, key, value값이 만들어지고 쿼리는 1개이고 이 쿼리 벡터와 각각의 key vector와의 내적값을 구하고 결과를 softmax에 통과시켜 가중치를 구한후 , 이값과 value vector를 각각 곱해주어 이들의 가중평균으로 최종적인 vector를 구하다. 결국 이 vector가 feature들이 담긴 encoding vector이다.
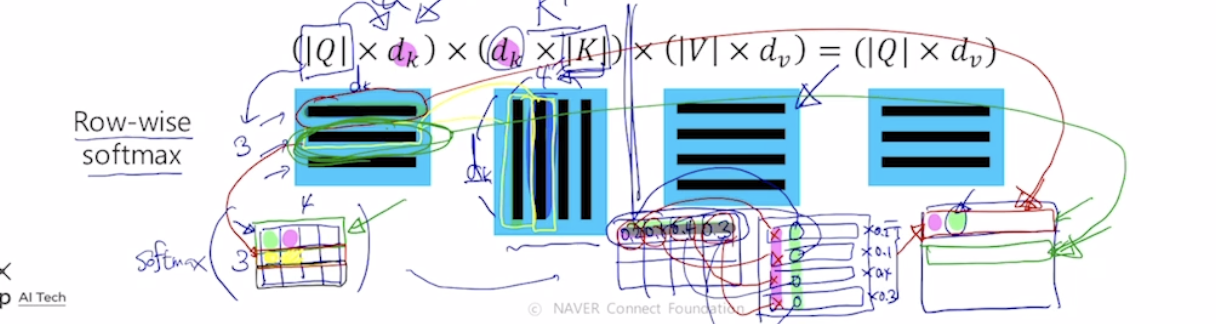
이러하게 행렬연산으로 위의 과정을 한번에 처리할 수 있다.
Multi-head Attention
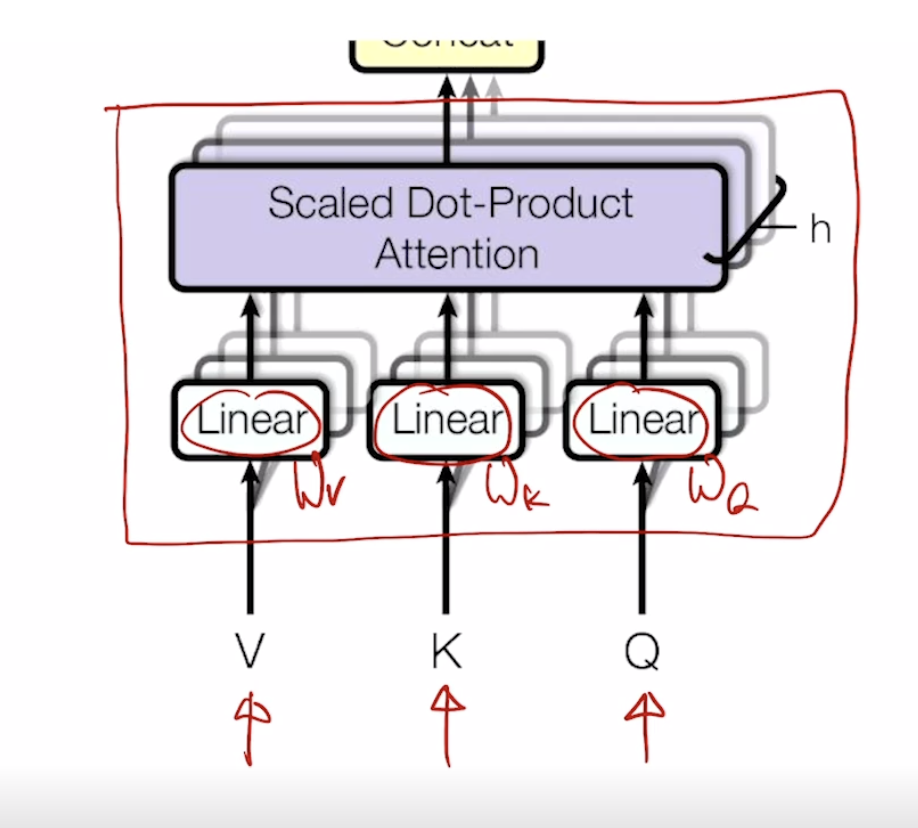
쿼리,key,value를 만들때 여러 set의 matrix를 적용하여 여러 attention을 수행한다. 이러한 서로다른 선형변환 matrix를 head라고 부른다. 동일한 sequence에서 특정한 quary에 대해서 여러측면으로 정보를 뽑아야하는 경우가 있다.

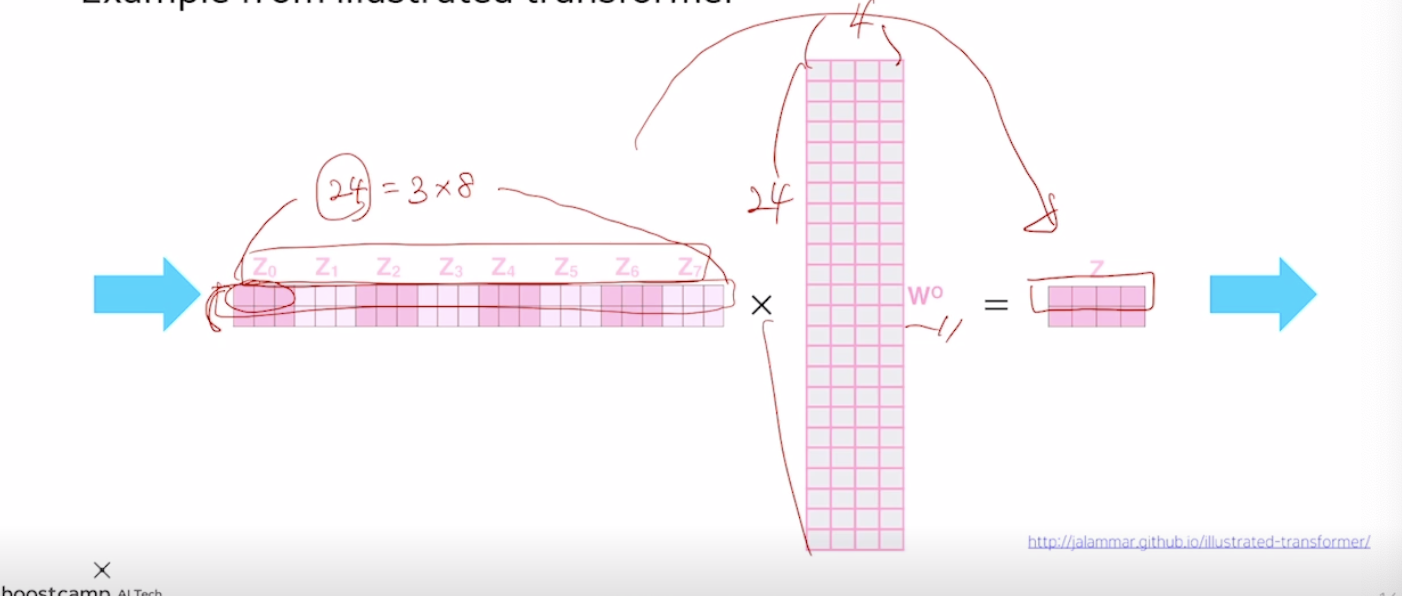
이후 하나의 선형변환 layer를 추가하여 우리가 원하는 shape의 output을 얻어낸다. 왜 이러한 shape으로 변환해야할까? for residual connection
Residual connection을 사용했다. 이는 CV에서 널리쓰이던 Resnet에서 사용한 residue개념을 활용하여, attention 결과의 encoded vector와 원래 입력 vector를 더한다. 이러한 과정을 통해 gradient vanishing과 학습의 속도를 해결하였다.
Layer Normalization
주어진 sample에 대해서 그값들의 평균을 0 분산을 1로 만들어준후 우리가 원하는 평균과 분산을 만들어주는 선형변환으로 이루어져있다.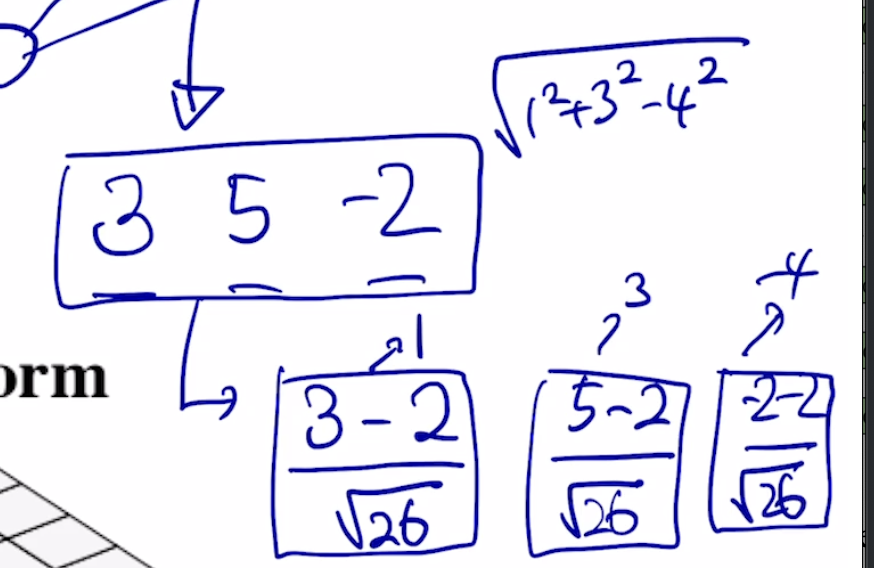
표준화된 평균과 분산으로 만들어줌. 이후 affine transformation (ex : y = 2x+3)을 수행할 경우 평균은 3 분산은 4가 된다. 여기서의 2와 3은 NN이 optimize해야하는 paramter가 된다. 위의 transformer에도 이런식으로 적용이된다
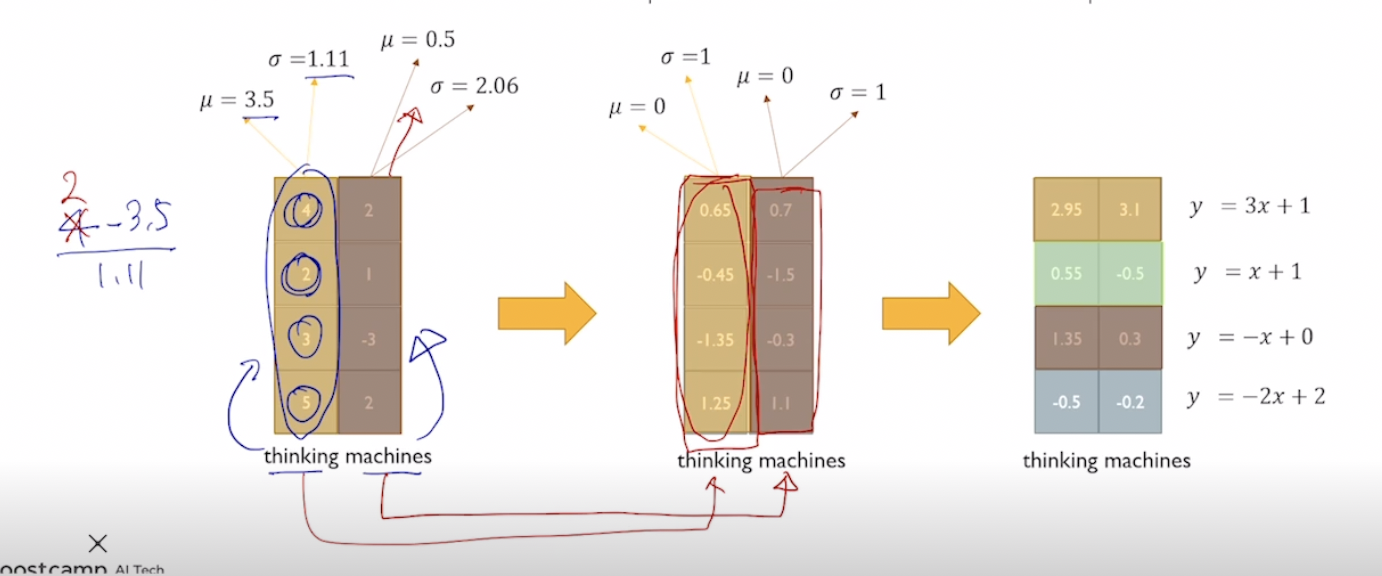
affine transformation은 이제 parameter이라 학습하는? 왜성능이 올라갈까?
Transformer에서의 self attention은 순서의 정보를 담고있지 않기 때문에 추가적인 작업이 필요하다. 이 작업을 transformer은 postition encoding에 sinusodial function을 적용하였다.
Optimizer은 graident descent가 아닌 Adam을 사용하였다. Learning rate을 고정한 값을 사용하지 않고 학습중에 lr을 변경시켜주었다.
Decoder
Masked Multi-Head Attention의 결과가가 얻어졌다면 이를 다시 multi-head attention에 넣어준다. 그데 이제 quary에만 이게 사용되고 encoding단의 encoded vector가 이제 key와 value값에 들어가게 된다. 이제 target language의 vocab size에 맞는 vector를 생성하는 linear transformation을 걸어준다. 그곳에 soft max를 취해서 다음 word를 찾아낸다. 이제 ground truth와의 softmax loss를 구해서 backpropagation으로 학습해 나간다.
Masked Self Attention
전체 sequence에 대한 정보를 허용하게 되면 첫번째 time step에서 SOS만이 주어졌는데 나는이라는 단어를 예측해야 하는데 나는이라는 값과 sos사이의 행렬곱값이 있기 때문에 이상황에는 이를 masking해주어야 한다.
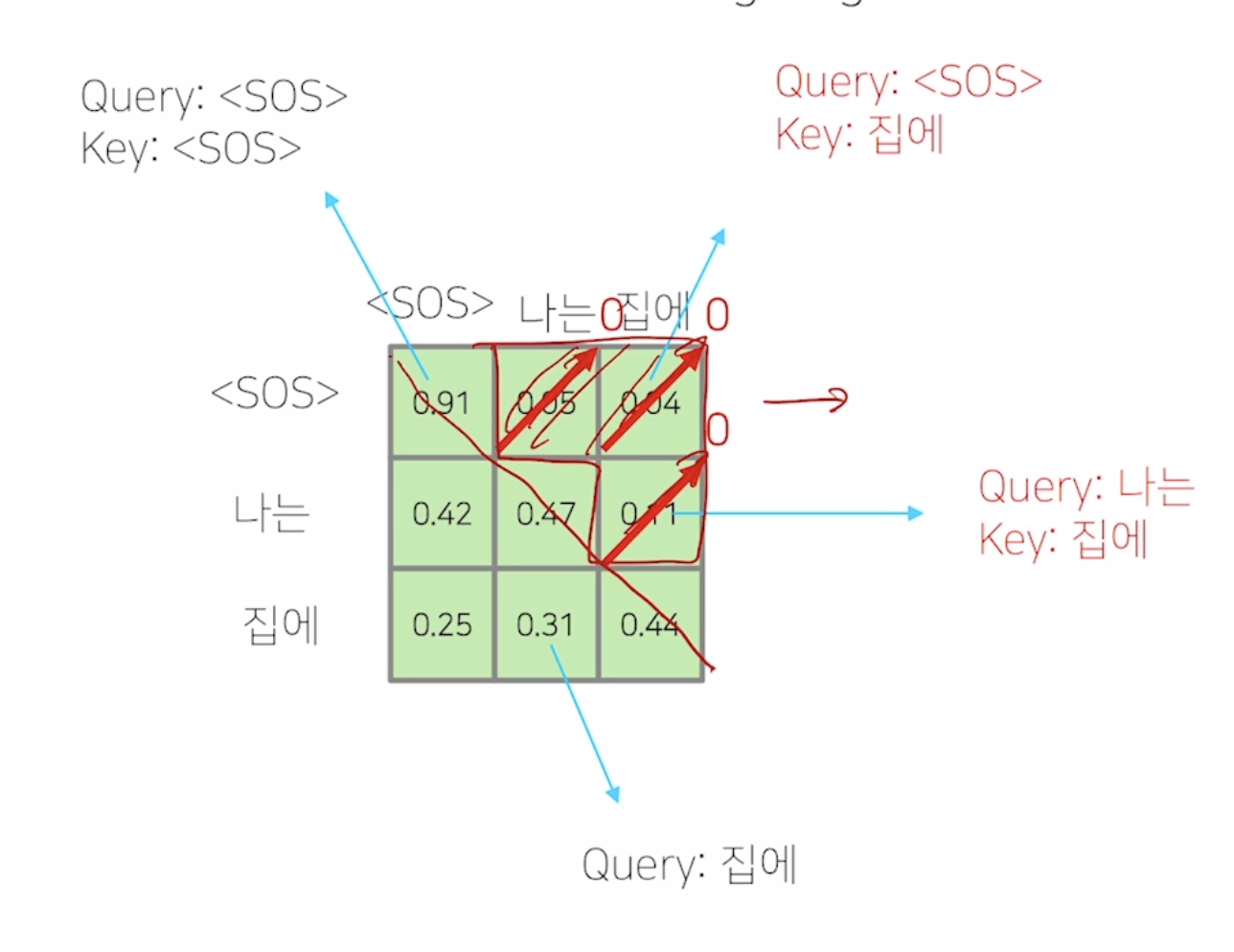
이렇게 masking해준후 normalize를 해주게 된다. 가중평균의 합이 1이 되도록