Image Classification
K Nearest Neighbors (k-NN)
기존의 data가 가지고있는 label을 활용해서 새로운 data의 label을 분류하는 문제가 된다. 이렇게 된다면 미리 유사도를 정의해야 한다. 그리고 system 복잡도가 너무 높다. 따라서 data를 NN의 parameter에 녹여넣는 것이다.
Yann Lecun의 CNN 개발 : 우편번호인식에 혁신을 이루어냄
Using better activation function
annotation data의 효율적인 학습 기법
data 부족문제의 완화 : 대표적인 방법들
- Data augmentation
- Leveraging pre-trained information
- Leveraging unlabeled dataset for training
Data augmentation
Data를 통한 pattern의 분석
Dataset is almost biased != real data
결국 우리가 사용하는 data들은 사람이 bias해서 찍은 사진들이 대부분이기 때문에 우리가 얻어놓은 training data까지 모두 표현하지 못하는 data들이다.
ex) crop, rotate, Brightness, …
Affine transformation
변환전후에 선으로 유지가 되고, 길이의 비율과 평행관계가 유지가 되지만 각도가 달라지는.
기본적인 틀을 맞춘 attine transofrmation
mixing both images and labels
RandAugment
random하게 augmentation 방법을 수행후 잘나온것을 가져다 쓰자. 어떤걸 적용할까, 어떤 강도로 augmentation을 할까?
이걸 policy리고 한다. Random sampling시
dataset을 만들어야 하는데 이러한 data를 모을때 label이 필요하기 떄문에 이러한 data를 단기간에 수집하기가 쉽지가 않다.
Transfer learning
기존에 학습시킨 model에 조금 바꿔서 적용. 한데이터set에서 배운 지식을 다른 task에 적용
한 dataset에 적용된 경우에 다른곳에도 적용할 수 있지 않을까?
Freeze 기존의 CNN layer’s parameter
적은 data로 부터
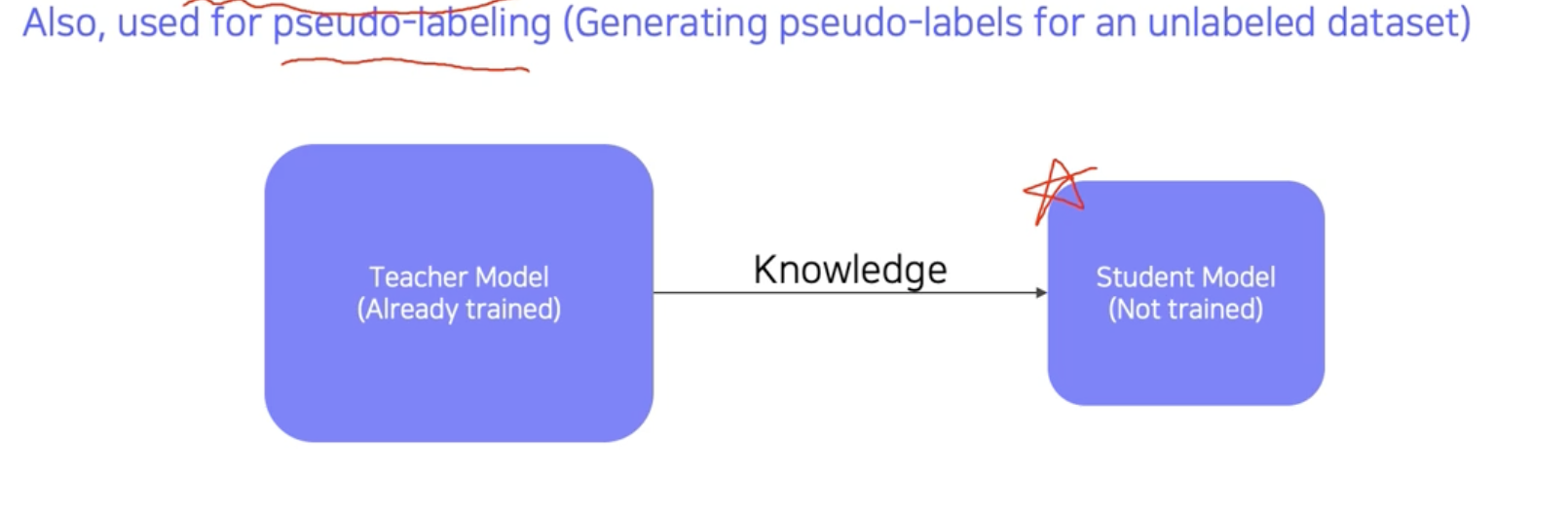
Pseudo-labeling이 좀 신기하다.
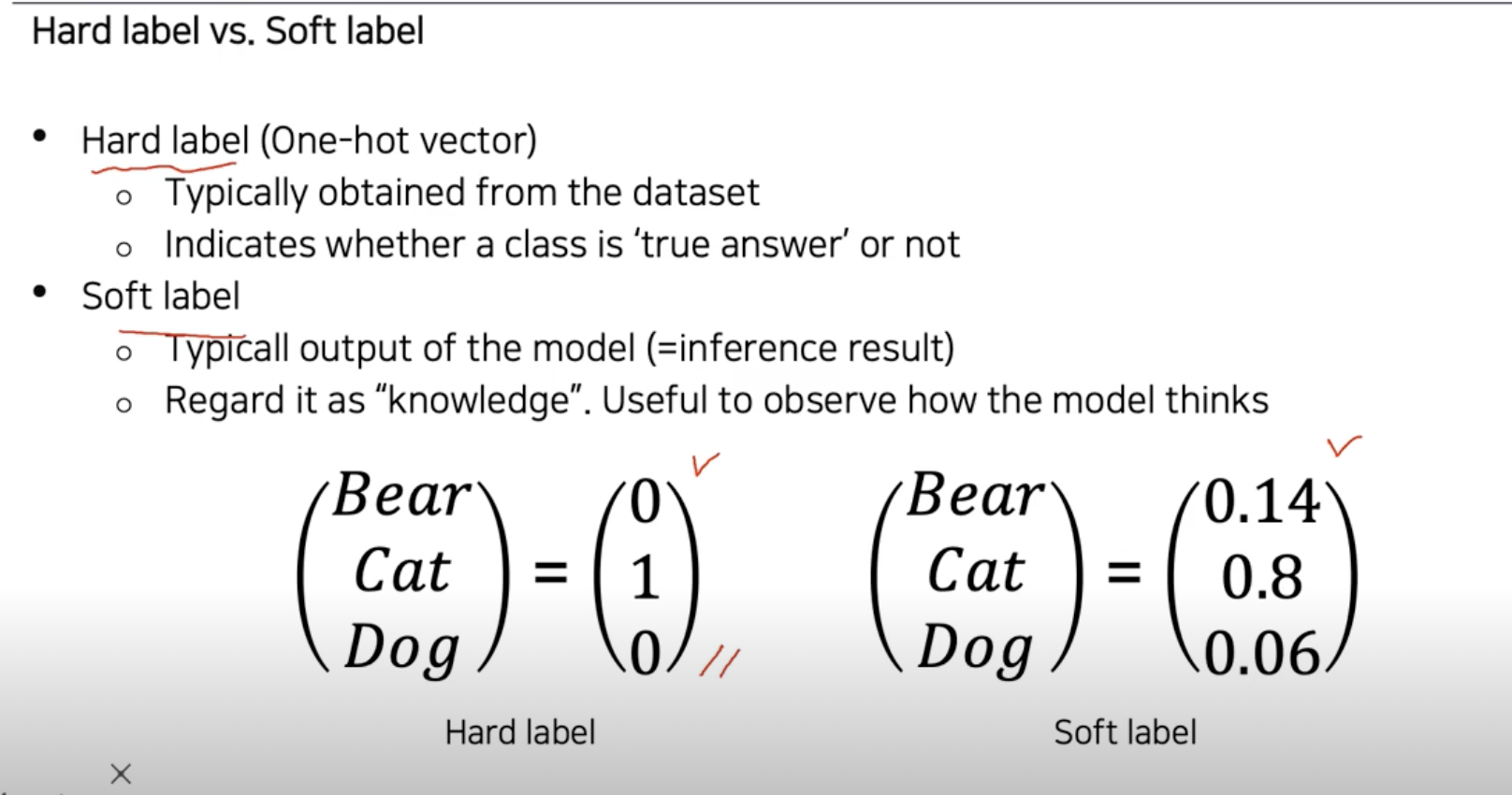
Knowledge distillation
더 깊은 network -> 더 높은 성능
깊게 쌓을수록 gradient explosion이나 vanishing gradient가 발생하였다, 계산복잡도가 올라가서 속도의 저하, overfitting문제가 아니라 degradation problem이라는게 밝혀졌다.
네트워크를 깊게 쌓기위한 network
- GoogLeNet
하나의 layer에서 다양한 크기의 cnn filter를 사용하서 여러측면으로 image를 관찰하겠다. 한층에 이렇게 여러 filter를 사용하게 되면 계산복잡도가 올라가고, parameter숫자가 늘어나기 때문에, 1x1 filter를 추가해 주었다. 1x1 layer as bottle neck architecture
- 공간크기는 변하지 않고, channel 수만 변화시켜준다.
Overall architecture
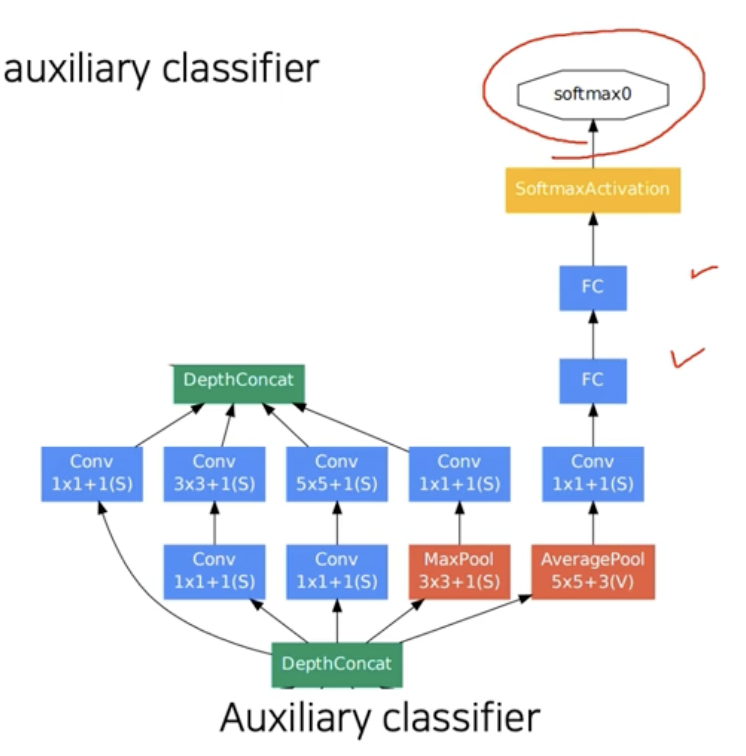
- inception module을 깊게 쌓아서 전체 network 형성
- Auxiliary classifiers : gradient vanising 문제를 해결하기 위해 추가해준 classifiers. 중간중간에 gradient를 꼽자주는 역할을 한다.
- loss가 중간에서 부터 흘러들어가기 때문에 멀리있는 단까지 gradient 전달이 가능하다.
Auxiliary classifier
ResNet
아직도 큰 영향력을 발휘하고 있는 network이다.
최초로 100개 이상의 layer를 쌓았다. 최초로 인간 level의 성능을 뛰어넘었다.
이러한 성과로 cvpr best paper를 받았다. 기존연구자들의 layer를 깊게 쌓는데 문제점
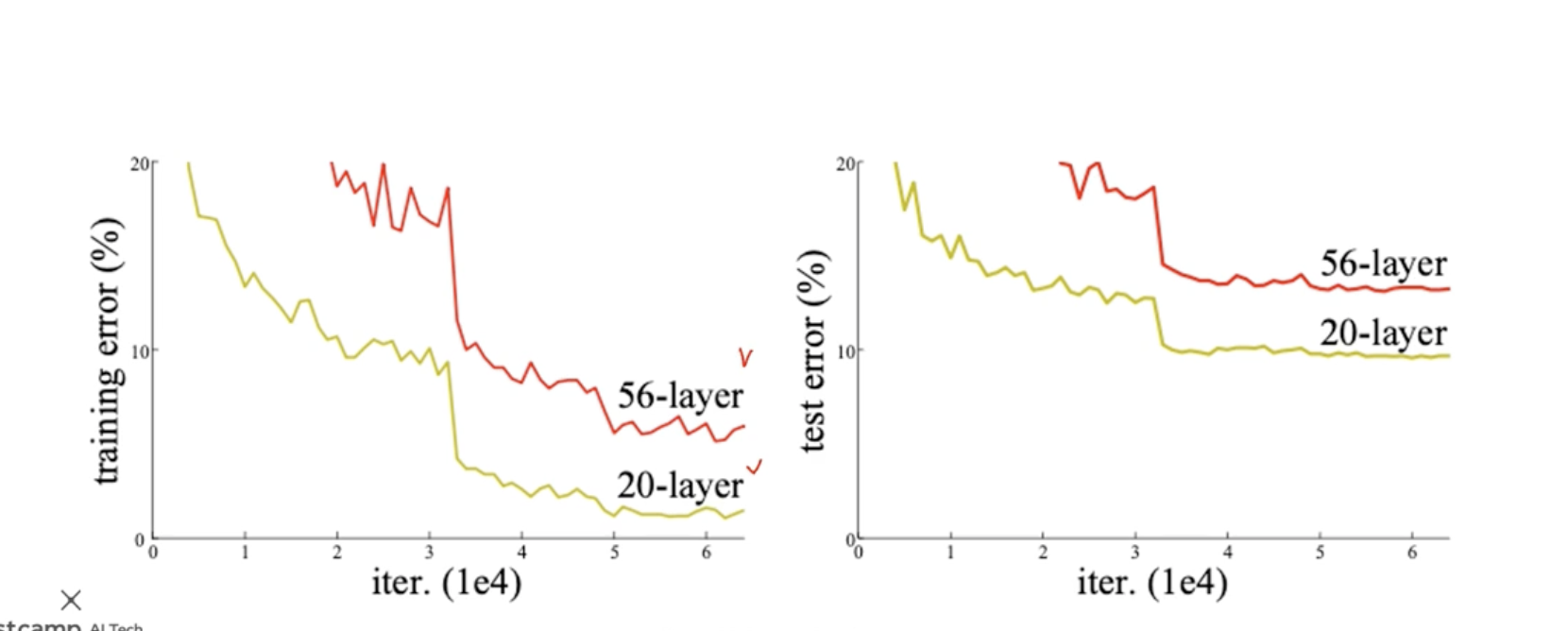
원래는 model parameter가 많으면 error가 줄어들 것이라고 생각했는데, 56 layer의 error가 더 크다는 결과가 나왔기 때문에, over fitting때문이 아니라는 결론이 나옴.
대신에 최적화 문제에 대해서 56 layer이 최적화 되지 않은 결과이다.
Í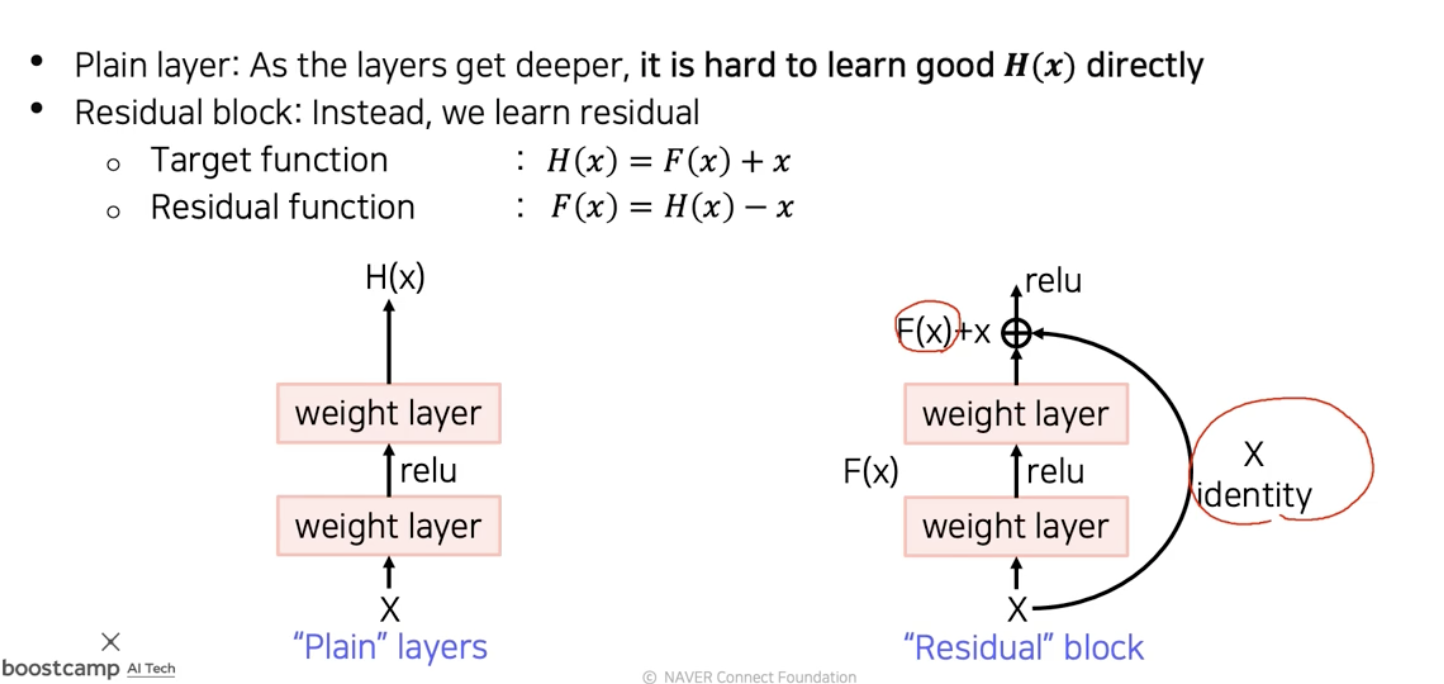
이렇게 만들어 버리면 학습의 부담감이 덜어지고 분할정복이 가능한 문제가 되지 않았는가?
이를 해결해 주기 위해ㅐ
shortcut connection을 통해 back prop과정에서 길이 하나가 더생기는 것이다.gradient. vanishing 문제가 해결이 되었다. 왜성능이 잘나올까?
residual connection을 하나 추가할때마다 2배씩 path가 늘어난다. 다양한 경로를 통해서 굉장히 복잡한 mapping의 학습이 가능했다.
initialization으로 He initialization을 사용했다. Reason ? -> initialize를 작게 해주어야 이후에 더해줄때 균형이 맞는다.
3x3 conv layer로 모두 이루어져 있다.
Only a single FC layer at final output
DenseNet
channel 축으로 concatnate한다. 훨씬이전의 layer에 대한 정보들도 모두 이어준다. 상위 layer에서도 모든 하위 layer의 특징을 참조할 수 있도록 해주었다.
더하기 두 신호를 합쳐버린다
concatnate chanel은 늘어나지만 feature를 더욱 잘 보존
fix된 3x3 만큼의 weight paramter가 이미 존재를 하고 2d offset을 위한 branch가 따로 존재 한다. 각각의 weight들을 벌려준다?
Semantic segmentation
픽셀단위로 분류해보자
영상속의 mask를 생성하게 되는데 같은 class이지만 서로다른 물체를 구분하지는 않는다.
영상속에 자동차가 여러대 있어도다 같은 class (색) 으로 구분한다.
영상내의 장면 content를 이해하는데 사용하는 필수적인 기술이다. object들이 구분되는 특징을 이해를 하여
Fully Convolutional Networks
입력에서 부터 끝까지 NN으로 구성한다.
입력으로 임의의 해상도 출력도 입력에 맞춘 해상도, 중간의 layer들도 모두 미분가능한 layer들이다.
각위치다 channel축으로 flattening이후 각각의 vector를 쌓아서 각 위치마다 vector가 하나씩 나오게 된다.
Upsampling
receptive field가 작기 때문에 upsampling을 통해서 강제로 resolution을 맞추어준다.
일단은 작게 만들어서 receptive field를 최대한 키운다음에 upsampling한다.
- Transpose Convolution
결과를 이렇게 그냥 더해도 되는건가?
cnn과 stride 사이즈를 조절해서 겹치는부분이 없게끔 조절해주어야 한다. (overlap problem)
- Upsampling Convolution
학습가능한 upsampling을 학습가능한 하나의 layer로 만들어주었다.
해상도가 낮아지지만 semantic하고 Holistic
중간층의 map을 upsampling한 이후에
높은 layer에 있는 feature map을 upsampling을 통해 해상도를 올리고 이에 맞춰서 중간층의 map들또한 upsampling한다. 이들을 concatnate하여서 각픽셀마다 class의 score를 뱉어주게 된다.
최대한 많은 layer들을 합친것이 큰 도움이 된다.
FCN은 end to end로 손으로 만든게 아니라 모두 NN이라 병렬처리도 가능하고 성능도 좋으며, low high feature모두 잘 포함한다.
U-Net
built upon fully convolutional networks
with skip connections
channel size가 줄고 해상도가 느는 expanding path
fusion - concatnation을 사용한다.
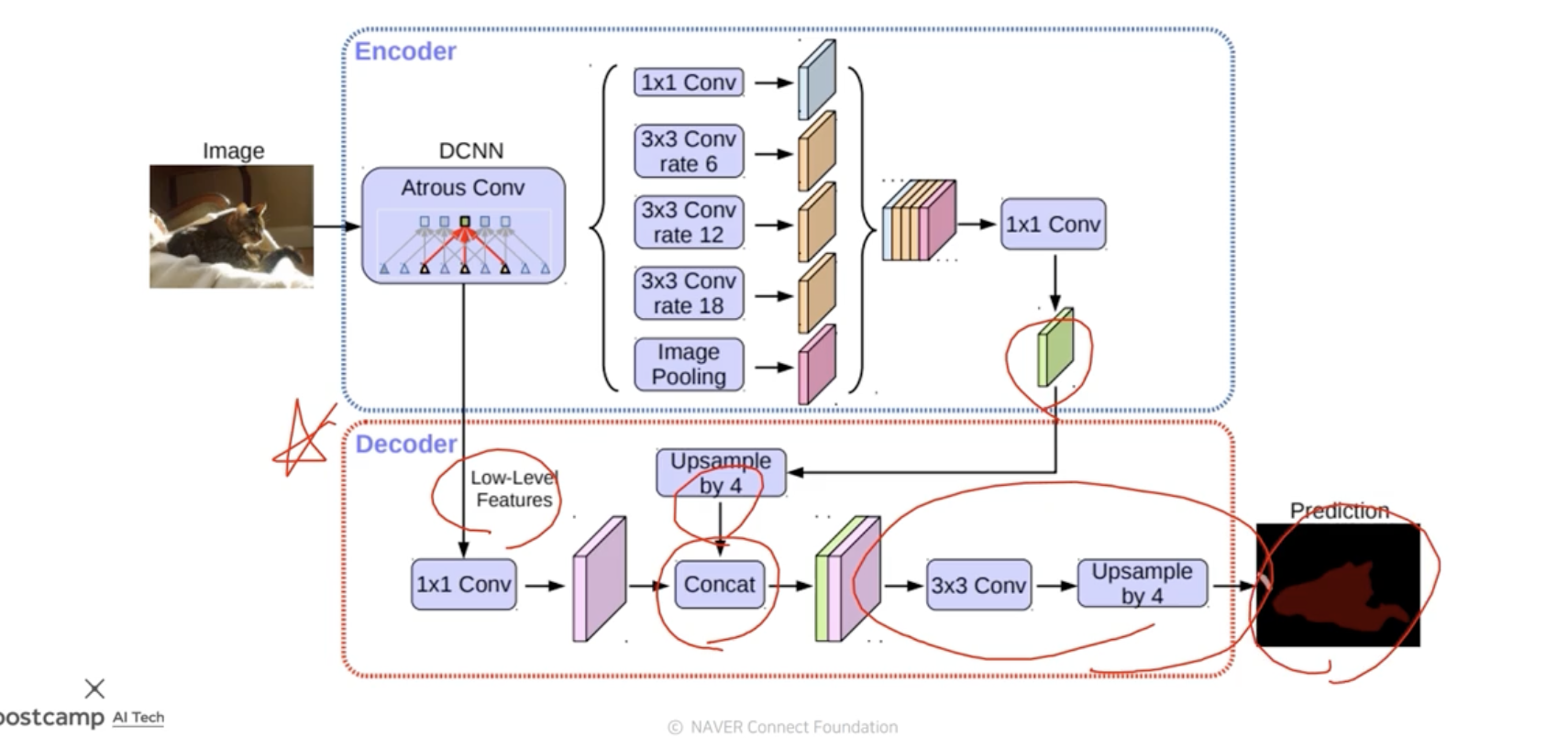
DeepLab
pixel과 pixel사이의 관계를 이어준후 pixel간의 거리를 모델링하였다.
확산의 반복으로 물체의 경계에 잘맞는 segmetation을
- Dilated convolution
- parameter수는 늘어나지만
depthwise convolution
channel별로 conv연산을 해서 값을 각각 뽑은후, 각 channel별로 pointwise convolution을 통하여 하나로 합쳐준다.
Instance segmentation으로 빠르게 발전을 하고있다.
Instance segmantation : 같은 사람이여도 같은색이 아닌 따로따로 segmentation이 가능한 기능
panoptic segmentation
Instance segmentation을 포함하는 기술
객체들을 구분하는 기술 : object detection
scene understanding을 위한 기술
bounding ob와 classification을 동시에 추정하는 기술이다.
해당하는 box의 물체의 category까지 추정한다.
2개의 좌표로 bounging box를 결정한다. 나머지는 class에대한 probability를 결정해 준다. Bounding box localization
selective search
oversegmentation 이후 비슷한 색깔끼리 합쳐준다.
Two-stage detector
- R-CNN
기존의 image classification을 활용
selective serch 로 region proposal을 구하고
적절한 크기로 warping을 해서 CNN (pretrained)에 넣어준후 category를 구해준다.
마지막 classifier은 SVM을 썼다.
단점 : model 하나하나마다 모두 cnn을 돌려야하고 selective search를 사용해서 학습을 통한 성능향상에 제한이있다.
- Fast R-CNN
recycle a pre-computed feature for multiple object detection
영상전체에 대한 feature을 추출후 이를 재활용
- CNN에서 Convolutional feature map을 뽑아주고(warping x)
- ROI pooling layer로 feature map으로 부터 ROI feature를 뽑아낸다
- feature pooling이후 class와 bbox regression을 사용한다.
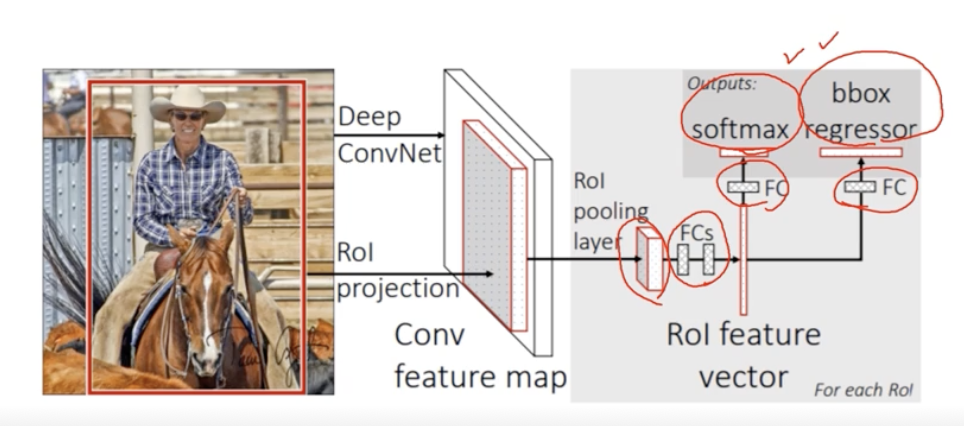
여전히 roi를 찾기 위해 selective search를 쓰고있다
- Faster R-CNN
최초의 endtoend object detection
IoU = Area overlap/Area of Union, 높을수록 두영역이 많이 겹친다
- Anchor boxes- 9개의 actor box를 사용하였다. 미리 정해놓은 bbox의 크기
Selective search를 대체하는 RPN을 제안하였다.
그럴듯한 bbox만 남기기 위해 non maximum suppression을 사용하였다.
Single stage detector
정확도 보다 속도를 선택한 것이다
image를 gird로 나누어서 4개의 좌표와 confidence score를 예측한다.
각각의 task보다 Instance segmentation과 Panoptic segmentation
Instance Segmentation
Instance segmentation = Sementic segmentation + distuguishing instances
Mask R-CNN
RPN
기존의 ROI 풀링은 정수좌표만 지원을 했었는데, interpolation을 위해서 소수점 pixel level을 지원하였다.
Panoptic Segmentation
UPSNet
FPN구조로 고해상도 feature를 뽑은 이후 Semantic Head 와 Instance Head로 나누어 predict를 하게 된다.
Landmark localization
Facial landmark localizaiton
Human pose estimation
다양한 data를 사용한 학습
Multi-model learning
Challenges
- 각각의 감각의 데이터가 모두 다른 representation을 띈다
- Feature space에 대하여 balance가 맞지 않는다.
- 여러 modelity를 사용할 경우 특정 model에 bias될수 있다.
대표적인 구조
- Matching
- Translating
- Referencing
Visual data & Text
Joint embedding
- Image tagging
태그 -> 이미지, 이미지 -> 태그
각 feature들은 차원을 맞춰주고 이둘의 Joint embedding을 만들어준다.
같은 space에 이미지와 text를 embedding해주고 matching되는 image와 text 끼리 거리가 가까워 지게끔 학습을 진행한다.
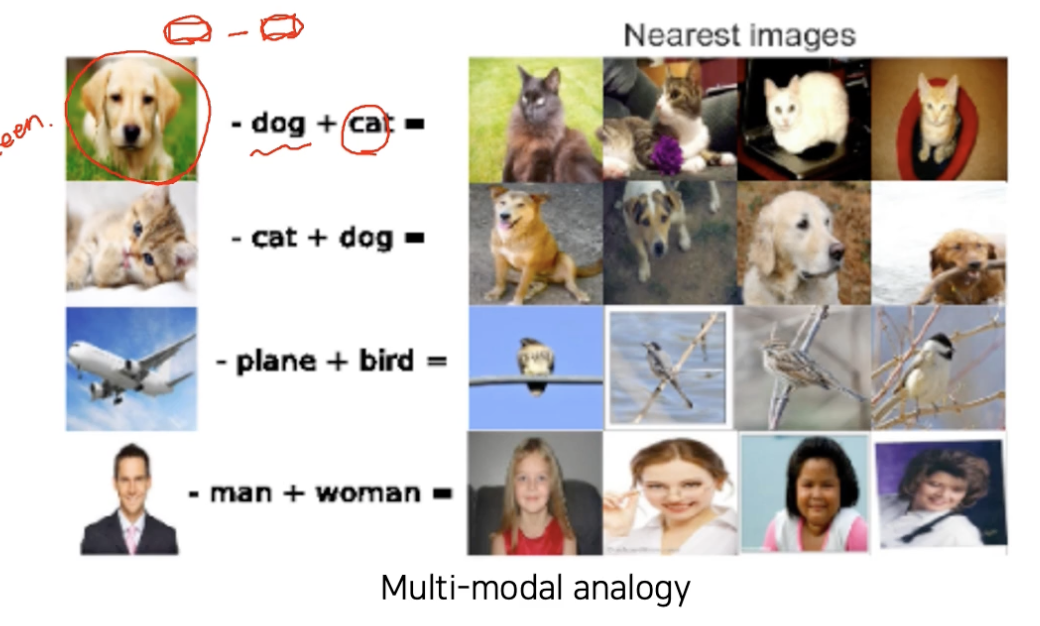
Metric Learning

창 - 프로세스 (현재 진행중)
탭 - 쓰레드 (그냥 띄워진 창)
- 쓰레드마다 갖는 메모리 공간 / 프로세스가 공유하는 메모리 공간이 있다.
- 프로세스가 늘어나면 쓰레드 공유 공간이 늘어나게 된다.
process: 코어수에 따라 병렬처리 가능
thread: 프로세스 위에 올라가있는 task보통 1개의 process로 concurrent로 처리하는 것 보다, max core의 5070%정도로 process를 나눠서 처리해주는 게 훨씬 좋은 성능을 낸다.
—- ps. 파이썬은 멀티프로세싱 >> 멀티쓰레딩
search keyword: multi threading/processing, python global interpreter lock(GIL)
mini task) [멀티 프로세싱/쓰레딩] 으로 10만까지의 소수 찾고 성능 비교 후 github에 올리기 (~3.15 월)
—- point —-
피어세션 뿐만 아니라, 앞으로 공부방향에 있어 수업 내용 외적으로 전체적인 그림을 그리며 공부를 이어나갈 것! (cs, ml pipeline 등…)
Q) ml 엔지니어라면, 검색을 했을 때 가장 좋은 결과를 내기 위해서는 어떻게 해야 할까요?
A) 어떤 것이랑 어떤 것을 연결시킬 건지…등등 잘 생각해보자! ^_^
Image Classification
https://jo-member.github.io/2021/03/08/2021-03-08-Boostcamp31.1/