Pstage2_KLUE
문장내 개체관 관계 추출
뭔가 아쉬웠던 P-stage 2 KLUE가 끝이 났다.
이번 stage에서는 리더보드 순위를 올리는데에만 집중하기 보다는 다양한 task를 써보고 원리를 이해하고 결과를 토론계시판에 꼭 조금이라도 공유하는 방식으로 하기로 마음먹었었다.
Overview
문제정의 : 문장의 단어(Entity)에 대한 속성과 관계를 예측하라.
Input data : 9000개의 train data, 1000개의 test data
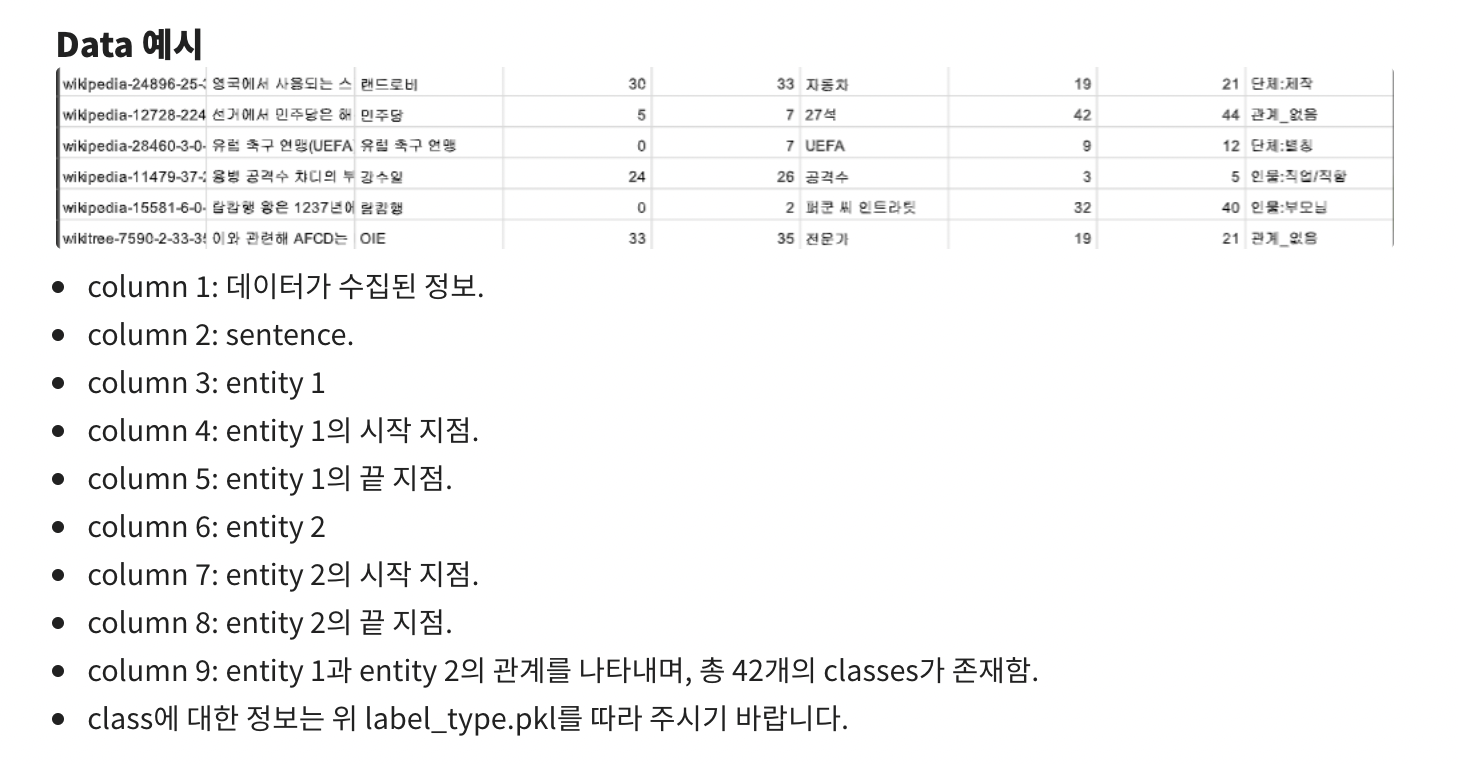
우리가 빼내야 할 column : sentence, entities, place of entities
Output
총 42개의 class를 예측
1
{'관계_없음': 0, '인물:배우자': 1, '인물:직업/직함': 2, '단체:모회사': 3, '인물:소속단체': 4, '인물:동료': 5, '단체:별칭': 6, '인물:출신성분/국적': 7, '인물:부모님': 8, '단체:본사_국가': 9, '단체:구성원': 10, '인물:기타_친족': 11, '단체:창립자': 12, '단체:주주': 13, '인물:사망_일시': 14, '단체:상위_단체': 15, '단체:본사_주(도)': 16, '단체:제작': 17, '인물:사망_원인': 18, '인물:출생_도시': 19, '단체:본사_도시': 20, '인물:자녀': 21, '인물:제작': 22, '단체:하위_단체': 23, '인물:별칭': 24, '인물:형제/자매/남매': 25, '인물:출생_국가': 26, '인물:출생_일시': 27, '단체:구성원_수': 28, '단체:자회사': 29, '인물:거주_주(도)': 30, '단체:해산일': 31, '인물:거주_도시': 32, '단체:창립일': 33, '인물:종교': 34, '인물:거주_국가': 35, '인물:용의자': 36, '인물:사망_도시': 37, '단체:정치/종교성향': 38, '인물:학교': 39, '인물:사망_국가': 40, '인물:나이': 41}
EDA
이번 자연어 task의 경우에는 데이터도 적고 image task에 비해 복잡한 eda가 필요한것 같지는 않았다.
따라서 가장 중요한 label들의 갯수만을 확인하고 빠르게 다음 단계로 넘어갔다. (토론글에도 하나 작성하긴 했지만, 거기서 작성했던 label들간의 유사성으로 class imbalnace를 해결하기 보다는 focal loss를 사용하는게 직관적으로 더 쉬워 보여서 focal loss를 사용하기로 하였다.
- label들의 분포
주피터 노트북을 통해 빠르게 data를 불러와서 label들의 분포를 확인하여 보니. label들간의 불균형이 매우 매우 심했다. 심지어 인물 : 사망국가의 label을 가지는 data는 1개 뿐 이였다. 이 1개로 과연 test data의 해당 label을 잘 맞출수 있을까? 아닐것 같다.
이러한 imbalnace문제에 효과적으로 대처하는 방법은 이전 p-stage에서도 배웠었다. 바아아아로 focal loss
focal loss에 대해서 간략하게 알아보자
1 | class FocalLoss(nn.Module): |
Focal loss는 페이스북의 Lin et al이 제안한 loss function이다
간단하게 말하면 분류 에러에 근거하여 맞춘 확률이 높은 Class는 조금의 loss를, 맞춘 확률이 낮은 Class는 Loss를 훨씬 높게 부여해주는 가중치를 주어서 class imbalance에 더욱 효율적으로 대처하는 loss funtion이라고 생각하면 된다.
loss 함수를 호출하게 되면 input tensor들에 대한 확률로 표현된 tensor를 얻은뒤 F.nll_loss를 호출한다.
F.nll_loss(((1-prob) ** self.gamma) * log_prob,target_tensor,weight=self.weight,reduction=self.reduction)
Weight 값을 우리가 가지고 있는 label 분포에 대한 1-d tensor로 넣어준다.
Ex) 우리가 가지고 있는 label들은 42개니까 42 length를 가지는 1-d tensor 값은 label의 분포에 맞게
이렇게 loss 함수를 불러다가 짜주면 끄읏
Model
모델을 굉장히 여러개 불러다가처음엔 돌려보았다. 사용해본 model 목록
- bert-base-multilingual-cased
- xlm-roberta-large
- koelectra-base-v3-discriminator
- kobert
이렇게 4개정도 실험해 보았던것 같았다. 결국 결론만 말해보자면 RoBERTa-large를 사용했다.
hevitz 님의 토론계시판 글을 보니, bert도 large를 사용하면 좋겠지만?????? 아직 Huggingface에 model이 공개된것 같지 않다.
그리고
This paper shows that pretraining multilingual language models at scale leads to significant performance gains for a wide range of cross-lingual transfer tasks.
라는 RoBERTa의 논문을 보면 이 significant performance gains 라는 문구는 이게 맞다라는 확신을 가져다 주었다. (물론 논문에서는 다들 자기가 짱이라고하긴하지)
또한 4개를 각각 적당한 hyperparameter로 돌려본 결과 평균적인 정확도가 roberta-large를 사용하면 대폭 증가함을 확인하였다.
RoBERTa는 bert와 유사하지만 BERT에 다양한 방법을 적용시켜 성능을 향상한 model이다. Model의 구조는 bert와 흡사하니 생략하겠다.
단지 hyperparameter를 최적화하고 NSP를 없애고 최대한 max_length에 맞춰서 문장을 넣어주고, masking을 더 다양한 방법으로 해주었다고 한다.
train 방법?
- loss
- optimizer
- Train-set, validation-set 나누기
이번 KLUE에서 Huggingface의 라이브러리는 질리도록 다룬것 같다. 물론 아직 모자르지만 ㅎㅎ
이전 P-stage에서는 training 과정을 우리가 다 pytorch 라이브러리를 사용하여 train 함수를 만들고 쏼라쏼라 해서 구현했었는데!!!!
이런 편리한 trainer라는게 있는 hugging face 아주 칭찬해 ^^
하지만 단순히 trainer를 사용하는것은 실력 증진에 별로 의미가 없다고 생각했다. (물론 마스터님 말씀처럼 Hugging face만 잘 사용하더라도 그만큼 장점이 있다고 한다!!!)
그래서 huggingface 홈페이지에 들어가서 trainer를 자세히 살펴보았다.
처음에 정했던 focal loss를 사용하기 위해서는 trainer class를 상속받아서 나만의 trainer class를 구현해주어야 했다. 홈페이지를 보면 관련 예제가 있어 쉽게 바꿔줄수 있었다. (현규님의 도움과 함께라면 ㅎㅎ)
1 | class FocalLossTrainer(Trainer) : |
여기서 loss_fn만 위에서 정의한 FocalLoss()를 불러다가 사용하면 끄읏! easy
Optimizer관련해서는 trainer 안에서 사용하는 AdamW를 그대로 사용하면 될거 같았고 수정해주어야 할 것은
- lr_scheduler
- lr
이정도? 인것 같다. default 로 설정된 lr_scheduler은 step에 따라 linear 하게 lr 이 감소하는 scheduler를 쓴거 같은데
저번에 사용했던 CosineAnnealingWarmRestarts 으로 바꾸어서 사용해보면 어떨까? 생각을 해보았다.
저번 stage에서 AdamP와 CosineAnnealingWarmRestarts의 조합으로 꽤나 쏠쏠한 재미를 보았기 때문에 ㅎㅎ
세세한 parameter은 seed를 고정시킨 이후 validation score를 기준으로 설정해주면 될듯 싶다.
validation 과 train은 2:8 로 나누었고 제출전에는 data모두를 사용해서 train 한 model로 inference 하였다.
자 이제 가장크게 고민을 해준 부분이다
Input 형식에 따른 성능
이번 stage에서 제공된 baseline code는 꽤나 simple하고 간결하지만 있을거는 다있다.
가장 의문점이 들었던 것은 tokenizer에 넣어주는 data 의 형식이였다.
ent01 : 이순신
ent02 : 무신
sentence : 이순신은 조선중기의 무신이다.
# RoBERTa tokenizer 기준 special token
1 | {'bos_token': '<s>', |
이러한 형식으로 들어갔다.
오피스아워에서 여쭈어 보니까, 별다른 이유 없이 간단하게 정해준 형식이라고 했다.
따라서 초코송이님께서 올려주신 ner을 entitiy사이에 넣어주는 논문글을 읽고 pororo library를 이용하여 ner을 얻어낸뒤 이를 entity양옆에 삽입하여 주었다.

이와같은 형식이다.
처음에는 저 기호들을 special token에 추가해준뒤, model에 넣어주었지만!!
혜린님의 질문과 피드백으로 논문에서는 special 토큰으로 지정하지 않고, 원래 vocab에 있는 기호들을 사용하였다고 한다……
이미 토론글에 올렸는데……… 올리기 잘했다는 생각이 들었다. 올리지 않았다면 이 문제를 평생 모르고 잘못된 지식을 가진채로 실험하였을것이다.
마스터이나 조교님들 말씀대로 일단 나대는게 좋은것 같다. 남들에게 배울점도 많고, 나대면서 스스로 좀더 찾아보고 학습하게 되는것 같다.
이러한 input 형식은 동일 seed model hyperparamter으로 약 1.5퍼 정도 leaderboard acc의 상승을 이끌어냈다.
autotokenizer로 불러온 tokenizer은 대부분의 vocab들을 포함하고 있어, unknown으로 나오는 token들이 적은것을 확인하였다.
특히 entity가 unk로 나오게되면 큰 문제임으로 이를 체크하였는데, 모두 잘 tokenize된것을 확인하였다.
optimzer은 trainer에서 사용했던걸로 동일하게 사용하였고
lr과 scheduler를 바꾸어 가며 RoBERTa에 맞는 hyperparameter를 찾기위해 노렸했다.;)
이번 stage에는 따로 하고있는 ROS 실습과 겹쳐 하고싶은게 3가지 있었는데 못해봤다ㅠㅠ
wandb로 실험 관리하기, sweep 사용해서 automl까지 해보기
input에 무작위로 masking 적용해보기
augmentation으로 data 증강해보기
하지만 이번 stage로 관심이 없었던 NLP에 대해 다시한번 생각해보게 되었다. 생각보다 재미있는 아이디어들이 많았고, 특히 오피스아워나 마스터 클래스에서 멘토님과 마스터님의 열정을 보고 굉장히 큰 영감과 자극을 받았다. 아직 한국어 관련 NLP task들이 많이 부족하다는 걸 듣고 확실히 고려해보게 되었다. Hugging face 를 많이 다루어 본점도 매우 득이되었던 stage였다.