Pstage3_Image_Segmentation_Detection
Image Segmentation
https://github.com/bcaitech1/p3-ims-obd-hansarang
Overview
문제정의 : 쓰레기가 찍힌 사진에서 쓰레기를 Segmentation
Input data : 4109장의 쓰레기 사진중, 3287장 (80%)는 train data, 나머지 812장(20%)는 private test data (512,512)의 이미지
Annotation
- train_all.json: train에 쓰일 수 있는 모든 image, annotation 정보 (image: 3272, annotation: 26400)
- train.json: train_all.json 중 4/5에 해당하는 정보 (image: 2617, annotation: 21116)
- val.json: train_all.json 중 1/5에 해당하는 정보 (image: 655, annotation: 5284)
- test.json: 예측해야할 이미지들의 정보 (image: 837)
- id: 파일 안에 annotation 고유 id, 이건 한 image 안에 여러가지의 객체가 있기 떄문에 image별로 각각의 객체의 annotation들이 있다.
- segmentation: masking 되어 있는 고유의 좌표
- bbox: 객체가 존재하는 박스의 좌표 (x_min, y_min, w, h)
- area: 객체가 존재하는 영역의 크기
- category_id: 객체가 해당하는 class의 id
- image_id: annotation이 표시된 이미지 고유 id
images
- id: 파일 안에서 image 고유 id, ex) 1
- height: 512
- width: 512
- file_name: ex) batch_01_vt/002.jpg
Output data : 11 class = {UNKNOWN, General trash, Paper, Paper pack, Metal, Glass, Plastic, Styrofoam, Plastic bag, Battery, Clothing}
평가 Metric
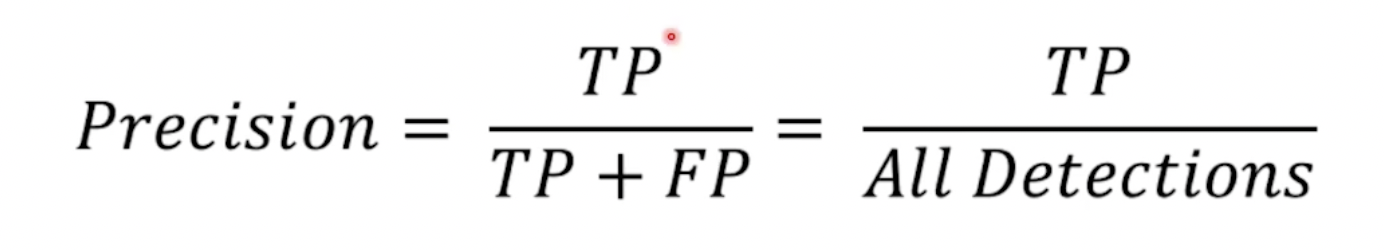
벌써 2주전의 기억이라 가물가물하지만 일렬의 과정들을 하나하나 되짚어 보며 이어나가도록 하겠습니다.
deeplab V3+, efficientnet-b5
- EDA
먼저 EDA 부터 진행하였습니다. 수업에서 제공해주신 eda들로 우리 data의 label분포를 확인할 수 있었고, 따로 이미지 data를 시각화를 해보며 이전의 stage와 마찬가지로 상당히 imbalance하다는 사실을 알게되었습니다.
이에 stage 2때도 적용하였던 focal loss와 다양한 augmentation을 사용하여 해결해야겠다는 생각이 들었습니다.
- Model
위에서 언급한것 처럼 처음부터 sota에 가까운 deeplab V3+를 선정하였고, 효율적이고 다양한 실험과정을 위해 backbone은 efficientnet b1으로진행하였습니다. 이에 작은 model에서의 parameter가 과연 큰 model에서도 똑같이 적용될까라는 의문이 들었지만, 이는 lr이나 scheduler에 해당한다고 생각이 되어, augmentation실험에서만 model의 size를 낮추었습니다.
가장처음 한 실험은 제기억에는 동일조건에서의 backbone에 따른 성능이였습니다.
다양한 크기의 Resnext와 efficientNet으로 실험을 진행하였고, 결론적으로 efficientNet-b5를 backbone으로 쓴 model이 가장 성능이 좋았습니다.
Resnext는 efficientNet에 비해 수렴속도도 빠르고 epoch당 시간도 적게 걸려, 이후의 앙상블을 위해 best model을 저장해 두었습니다.
- Augmentation
이번 task에서 쓰게된 augmentation은 아래와 같습니다
- HorizontalFlip(p=0.5)
- Rotate(p=0.5, limit=45)
- Cutout(num_holes=4, max_h_size=20, max_w_size=20),
- CLAHE(),
- RandomBrightnessContrast(p=0.5),
- Normalize(mean=mean, std=std, max_pixel_value=255.0, p=1.0)
이렇게 조합해서 썼을때 가장 성능이 좋았다는 결론을 얻었었습니다.
다양한 조합과 확률 값들을 적용하여 비교하여 진행하는 일련의 과정들은 매우 고되고 많은 시간을 필요로 하였습니다.
여기서 지금와서 생각해보면 Auto Augmentation을 적용해 보았으면 좋았을듯 싶습니다…
또한 추가적으로 horizontalflip을 이용한 tta를 적용시켜 보았지만, 성능의 하락을 야기했습니다.
- Loss & Optimizer & Scheduler
Loss는 Focal loss와 soft-crossentropy-loss를 각각 0.3,0.7의 가중치를 두어 학습하였습니다. 원래는 Focal만을 사용하였지만, stage1에서 multi loss에서 재미를 많이 봤었기 때문에, 마스터님의 의견을 듣고 scl을 추가해 주었습니다.
왜인지는 모르겠지만 soft-crossentropy-loss만을 사용하였을때 가장 성능이 좋아, 앙상블때의 다양성을 위해 multiloss로도 학습을 해두었습니다.
Optimizer또한 Adam계열의 Adamp를 사용하였고, Adam계열과 잘어울리는 Customized된 CosineAnnealingWarmRestarts의 scheduler를 사용하였습니다. 확실이 중간중간에 lr을 높혀주는게 local minimum을 잘빠져나오는 모습을 확인 할 수있었습니다. 내부에 내장된 Cosin scheduler은 gamma가 없기때문에 customized된 scheduler를 불러다 사용하였습니다. Adam에 잘맞는 cosine 계열의 scheduler를 사용한 결과, steplr을 사용한 타 팀원의 model 대비 제 model의 성능이 잘나왔음을 확인하였습니다.
wandb의 그래프를 보시면 보통 18 epoch쯤에서 최고점을 찍고 수렴하는 모습을 관찰하였습니다.
- K-fold & Pseudo Labeled data
single model의 성능의 한계에 부딛혀 0.63대를 헤어나오지 못하고있었던 2주차…
기존의 최고성능 parameter를 고정하고 Train+all과 pseudo labeled된 data를 합쳐서 2배의 data로 학습을 진행하였고 결과는 매우 성공적이였습니다. K-fold로 진행하고 싶었지만, GPU자원의 부족으로 인한 시간의 한계때문에 Train-all로 진행하여 제가 경험적으로 체득한 18 epoch에서 끊는 방식을 체택하였습니다. 결과는 매우성공적으로 single model 기준 0.6842라는 큰 성능향상을 얻어내었습니다.
다른 팀원분들도 pseudo label을 적용하여 앙상블을 하였다면 더 좋은 결과를 얻어낼 수 있었을텐데 매우 아쉽습니다.
- 앙상블
최종적으로 저의 다양한 backbone과 loss를 가지는 model들을 조합하여 soft voting을 하였습니다. 가중치는 LB상으로 가장높은 model에 0.4를 주었고 나머지에 0.2씩을 주어 총 4개의 singel model을 앙상블 하여 제출을 해봤는데, 0.6961이라는 아주 높은 점수가 나왔습니다. 이 model에 다른 팀원분들의 model hard voting 해보았지만 성능이 계속 하락하여 결국에는 저의 model만을 사용한 점수가 최종점수가 되는 아쉬운 상황이 연출되었습니다…
어느정도 팀원들간의 평균적인 점수대가 비슷해야 앙상블 했을때 좋은 점수를 낼수있었지만, psudo label을 저만 돌렸었기 때문에…
시간이 2일정도 더있었다면 다른 팀원 분들도 수도라벨로 성능을 어느정도 향상시켜 비슷한 점수대로 맞춰줄수 있었을 텐데 하는 아쉬움이 남았습니다…
Object Detection
- 평가 Metric

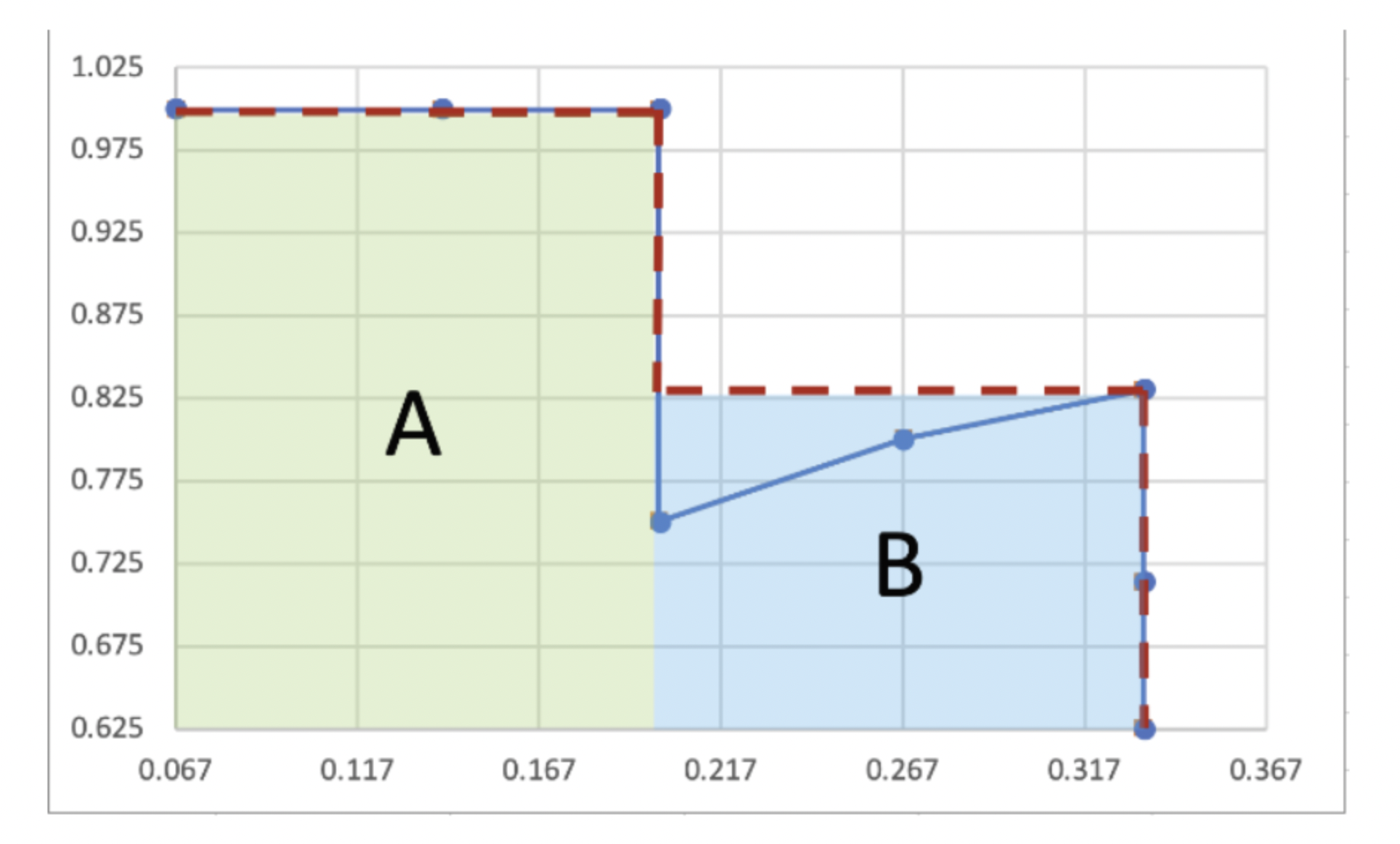
위와 같은 PB curve를 그린다. 이 때 recall과 precision은 confidence score별로 점들이 생성됩니다.
이후 (A+B)에 해당하는 영역의 넓이가 AP가 되고, 각각의 class의 AP의 평균이 저희가 구하려는 mAP입니다.
이번 object task에서는 mmdetection이라는 강력한 tool을 기반으로 실험을 진행하였습니다.
mmdetection에서는 저희가 config파일만을 수정하여 준다면 손쉽게 다양한 방법으로 다양한 model들을 실험해 볼 수있었습니다.
- Model
이번 task에서또한 sota model로 알려진 swin transformer를 backbone으로 쓰고 detector 부분은 cascade mask rcnn과 htc를 사용하였습니다.
다행이도 Swin transformer의 config파일이 git에 전부 올라와있었고, 저희의 실험환경에 맞게 조금 변경해 주면 되었습니다. 하지만 이 mmdetection이라는 툴자체에 적응을 하는데 시간이 좀 소요가 되었고, 한 3-4일 정도가 지나서야 어느정도 가닥이 잡히면서 어떻게 써야할지 감이 잡혔던것 같습니다.
backbone을 고정한 후 neck을 변경시켜서 다양한 실험을 해보았습니다.
- FPN
- PAFPN
- NAS-FPN
- BiFPN
이렇게 4가지의 선택지가 있었는데 이중 가장 오래된 FPN을 선택한 이유는 한가지 입니다. 왜냐하면 pretrained된 pth파일을 github에서 제공해주고 있는데, 이 model에서 FPN을 쓰고있기 때문입니다.
처음에는 backbone만을 pretrained된걸 가져와서 쓰다가, 전체가 trained된 model이 있는것을 발견하고 실험해보았는데 전체가 pretrained된걸 가져와서 저희 task에 fine tuning? transfer learning하는 방식이 더욱 성능이 좋았습니다.
FPN으로 trained된 전체 model을 가져다가 NAS-FPN으로 바꾸어준 model에 적용을 시켜줄시 neck쪽의 weight들에는 값이 들어가지 않게됩니다. 이것이 성능이 더 좋을 수도 있기때문에 이러한 방법도 시도해 보았지만, 바꾸지 않고 그대로 FPN을 사용하는것이 더 좋았습니다.
한가지 아쉬웠던 것은 pretrained된 Swin transformer를 backbone으로 쓰면서 swin에 대한 어느정도 전반적인 이해만을 가지고 있었을뿐, 세세한 model의 구조는 알지 못한채 작성되어진 config 파일만을 가지고 실험에만 집중할 수 밖에 없었던 상황이였습니다.
약간씩 parameter들을 수정해 주면서, 근본적인 이해없이 직관에 의해 실험을 반복하고 있는 제 자신을 발견한 후 competition에 대한 약간의 회의감이 들었습니다. 하지만 멘토님께서 library를 잘다루는 것도 하나의 능력이라고 말씀해주셔서 다시 한번 생각해 보았던것 같습니다.
- Augmentation
Augmentation에는 Flip과 Autoaugmentation, Normalize등을 적용해보았습니다.
가장 critical하게 작용했던 augementation이 바로 autoaug로, 여기서 resize와 crop size를 어떻게 주느냐에 따라 성능차이가 조금씩 발생했습니다. 이전 stage들에서의 경험으로, image task에서 high scale의 image training은 오랜 시간을 요구하지만 그만큼 성능이 잘나왔습니다. 따라서 resize의 list에는 upscale된 정사각형과 가로가 긴 직사각형, 세로가 긴 직사각형등을 고루 섞어 autoaug안에 인자로 넣어주었습니다.
이러한 변경점은 정사각형만을 넣어줬을때, low scaleing 해주었을때에 비해서 점수의 큰 향상을 야기했습니다.
- Loss Optimizer Scheduler
Loss
저희가 바꾸어 줄 수있었던 loss는 bbox loss로 3가지 정도의 선택지가 있었습니다. 그중 DIoU Loss를 채택하였을때 성능이 약간 상승했고, classification loss쪽의 cross entropy loss는 건드리지 않았습니다.
Optimizer
Optimizer은 AdamW를 사용하였고, 초기 lr값은 1e-4으로 고정시켜 주었습니다.
Scheduler
Scheduler은 model에 따라 다르게 적용시켜 주었습니다.
HTC를 이용한 model에는 cosineannealing을 cascade mask rcnn을 적용한 model에는 steplr을 사용하였습니다.
StepLR을 사용시 어떠한 epoch에서 lr값을 감소시켜줄지를 정할 수 있었는데, 평균적으로 8,11 epoch에서 map50값이 수렴하기 시작하는것을 확인하고 이쯤에서 gamma=0.1의 factor로 lr값을 감소시켜주었습니다.
- Pseudo-labeling
이전 segementation에서 pseudo labeling으로 큰 재미를 보았었기 때문에 이번 task에서는 좀 일찍 최고성능의 model로 pseudo data를 만들어 빠르게 실험해 보았습니다.
1 | import json |
위의 코드로 pseudo data를 coco형태로 바꾸어준뒤 통합된 json 파일로 train을 진행하였습니다. 그러나 threshold값을 설정해주는게 매우 애매했다.
이에 따라 성능이 너무 하락하는 현상이 발생하였고 결국 pseudo label된 data는 쓰지 못하였습니다…
segementation에서 잘먹히던 pseudo label이 detection에서는 부정확한 label값들로 학습이 어려운가 봅니다.
- WBF
마지막으로 최고 single model 기준 htc와 cascade 모두 0.5572의 점수를 얻어냈고 총 4개의 model을 앙상블한 결과 0.5824의 결과를 얻어냈습니다.
이후 모든 팀원들의 csv 파일을 WBF하여 최종적인 score 0.5884를 얻어내었습니다.
Conclusion
한가지 가장 중요하게 느낀점은 이렇게 competition을 마친이후에 관련 논문들과 kaggle notebook들을 자세히 정독하며 쓰였던 방법론들과 model들을 상세하게 공부해야 겠다는 필요성입니다.
competition 진행중에 개선해야 할 사항은 중간중간 팀원들간의 평균적인 점수대를 맞추어 놓아야 최종 앙상블 과정에서 큰 성능 향상을 이룰수 있다는 점입니다.
굉장히 열정적인 4주를 보냈습니다… 아쉬움도 남고 후련하기도 합니다…
진행했던 많은 실험 내용들을 모두 랩업레포트에 담지 못했다…. 추후에 체계적으로 정리해서 git에 올려둬야겠습니다.
Pstage3_Image_Segmentation_Detection
https://jo-member.github.io/2021/04/25/Pstage3-Image-Segmentation-Detection/