VQA: Visual Question Answering vs Competition Baseline
VQA task의 시초격인 논문이다.
VQA challenge의 전반적인 개요와 dataset, Base model등을 다루고 있다.

1. Introduction
- VQA란 Vision, NLP, knowledge representation을 모두 접목시킨 multi-discipline task이다

- 위와 같이 어떠한 image가 주어지고, image가 없으면 맞추기 힘든 질문들로 구성되어있다.
- Answer의 유형에 따라 open-ended questions 과 multiple-choice task로 나누어 진다.
- Open-ended question은 answer가 다양해 질 수 있지만, multiple-choice task의 경우에는 미리 정해진 answer list중 하나가 답안이여야 한다.
- 이 논문에서는 두가지의 answer유형 전부 다루고 있다. (우리의 VQA task는 multiple-choice task 만을 다루고 있기 때문에 open-ended 는생략)
2. Dataset
Image data
MS COCO dataset
- Object Detection과 image captioning에서 사용되는 dataset
- containing multiple objects and rich contextual information
- 123,287 training and validation images and 81,434 test images
Abstract Scene dataset
- The dataset contains 20 “paperdoll” human models [2] spanning genders, races, and ages with 8 different expressions.
- Paperdoll로 real한 상황을 표현함
- we create a new abstract scenes dataset containing 50K scenes
Question data
간단한 question이 아닌 복잡하고 어려운 question을 만들어내기 위해
“We have built a smart robot. It understands a lot about images. It can recognize and name all the objects, it knows where the objects are, it can recognize the scene (e.g., kitchen, beach), people’s expressions and poses, and properties of objects (e.g., color of objects, their texture). Your task is to stump this smart robot! Ask a question about this scene that this smart robot probably can not answer, but any human can easily answer while looking at the scene in the image.”
이러한 요청을 주어 question을 만들어 내도록 하였다.
Answer data
18개의 선택지를 구성
- Correct : The most common (out of ten) correct answer
- Plausible : To generate incorrect, but still plausible answers we ask three subjects to answer the questions without seeing the image
- Popular : These are the 10 most popular answers. For instance, these are “yes”, “no”, “2”, “1”, “white”, “3”, “red”, “blue”, “4”, “green” for real images
- Random : Correct answers from random questions in the dataset
3. Model

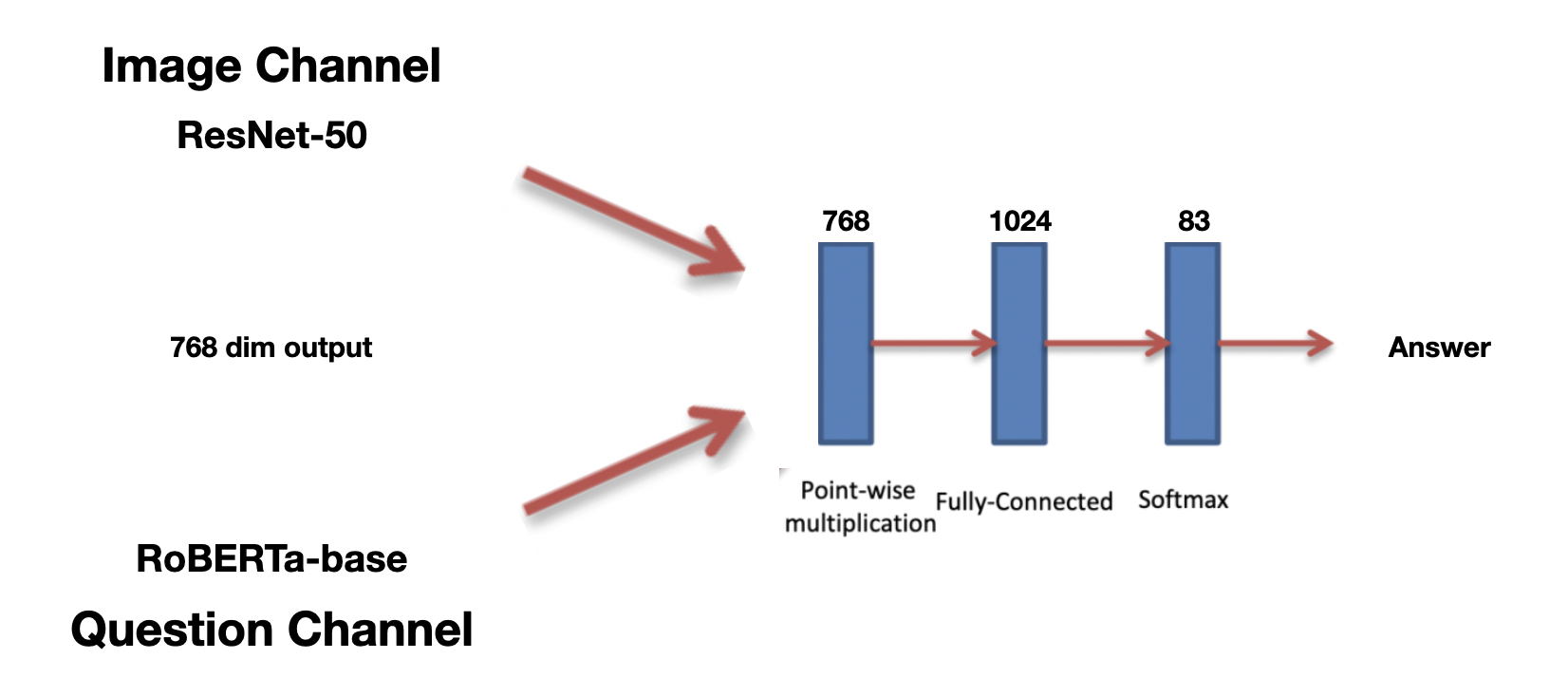
VQA를 위한 Base model과 Competition에서 제공해준 Baseline의 구조도이다.
Image channel
- Image로 부터 embedding vector를 뽑아내는 역할을 한다.
Pretrained된 VGGNet을 사용하였으면 기존 VGGNet의 마지막 Fully-Connected MLP의 layer에서 4096 dim으로 뽑아내었다.
- 인공지능 경진대회측에서 제공한 baseline에서는 pretrained된 Resnet-50을 사용하여 마지막 Fully-Connected MLP의 layer에서 768 dim으로 뽑아내고 있다. 이후 논문과 다르게 별도의 Fully-Connected layer를 통과시켜주지 않는다. 애초에 question channel과 dimension을 맞추어주었다. 마지막 target dimension은 83으로 train data의 label 개수이다.
- Image로 부터 embedding vector를 뽑아내는 역할을 한다.
Question channel
- Question으로 부터 embedding vector를 뽑아내는 역할을 한다.
Each question word is encoded with 300-dim embedding by a fully-connected layer + tanh non-linearity which is then fed to the LSTM. Cell state, hidden state dim = 512
Concate last cell state and last hidden state representations 을 하여 1024의 차원을 만들어주었다. - 인공지능 경진대회측에서 제공한 baseline에서는 huggingface를 사용하여 pretrained된 RoBERTa-base model을 통해 embedding vector를 뽑아 내었다. 뽑아낸 embedding vector의 dim이 768이라 Image channel의 last dimension또한 768로 맞춰준것이다.
- Question으로 부터 embedding vector를 뽑아내는 역할을 한다.
Multi-Layer Perceptron
이부분은 둘의 구조가 동일하다. 각 channel에서 나온 embedding vector들을 element wise multiplication해준다.
이후 layer을 추가해주어 차원을 늘려준뒤, 마지막 layer에서 target label의 개수만큼의 dimension을 뽑아낸다.
이부분에서 궁금했던점은 각 channel의 embedding vector를 합치는 방법에 따른 성능의 차이였다.
- Concat
- Element-wise Multiplication
- Element-wise Add
이와 관련된 논문을 찾아보았다.
Component Analysis for Visual Question Answering Architectures 이라는 논문에서 각 fusion 방식에 따른 성능을 실험해보았다.

위 논문의 결과에 따라 3가지 fusion 방식중 Multiplication 방식을 계속해서 고수했다.
또한 위논문에서는 BERT를 사용하여 question문장을 embedding만 하고 GRU를 사용하여 최종 vector를 뽑아내고 있다. 이러한 방식도 시도해 볼만 할것 같다.
4. Result

VQA: Visual Question Answering vs Competition Baseline