Sequence to sequence with Attention
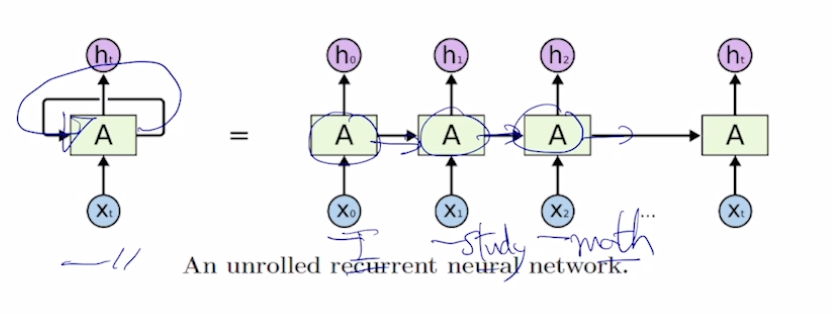
Sequence to sequence
\
Seq2Seq Model
Ex) Are you free tomorrow?
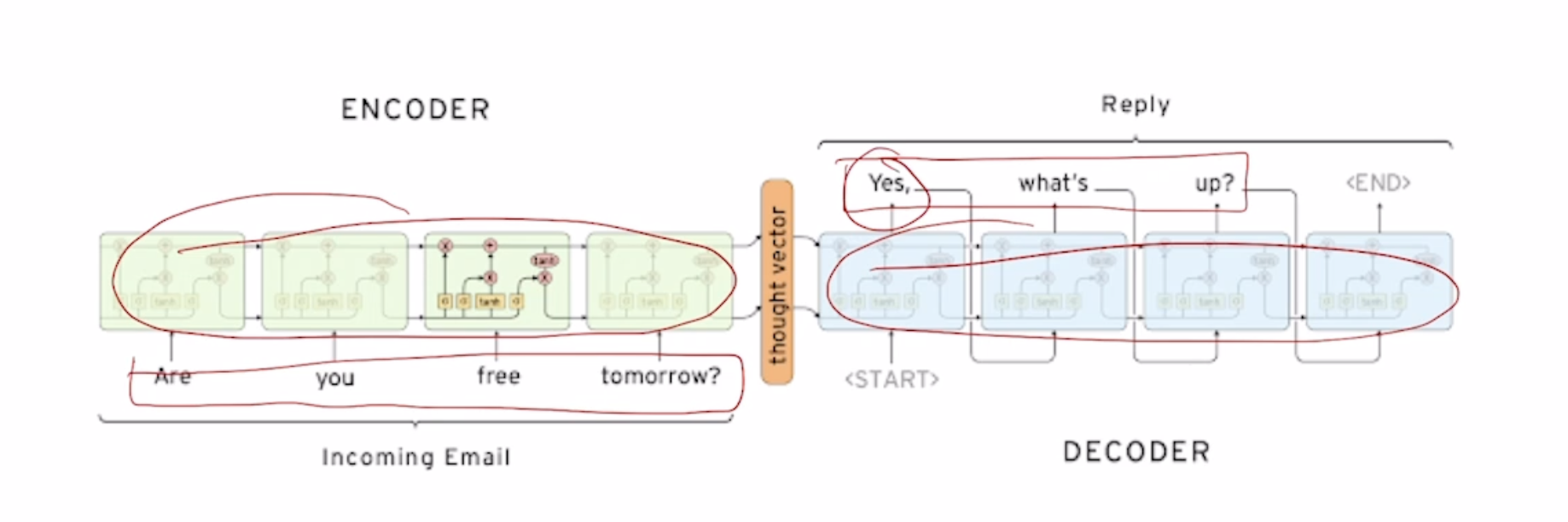
서로 paramter를 share하지 않는 2개의 별개의 RNN model을 (보통 LSTM) 쓴다. 각각의 RNN을 Decoder, Encoder로 사용한다.
Encoder의 마지막단의 output을 vertorize 시켜준후 decoder의 input에는 SOS token, hidden state에는 encoder의 output을 넣어준다.