Transformer심화
Transformer
Self-Attention
ex) I go home
I에 대한 input vector가 hidden state처럼 역할을 하여서
I와 각각의 단어에 대한 내적을 한후 이에대한 softmax를 구하여 가중평균을 구한다.
이렇게 encoding vector값을 구하게 되면 결국 자기자신과 내적한 값이 큰값을 가져, 자기 자신에 대한 특성만이 dominant하게 담길것이므로, 이를 해결해주기 위해 다른 architecture를 쓴다
각 vector들이 3가지의 역할을 하고있는 것이다. 동일한 set의 vector에서 출발했더라도 각혁할에 따라 vector가 서로다른형태로 변환할수있게해주는 linear transformation matrix가 있다.
한마디로 각각의 input이 서로다른 matrix에 적용이되어 각각이 key, quary,value가 된다는 의미이다.
I 라는 word가 서로다른 matrix에 따라 quart, key, value값이 만들어지고 쿼리는 1개이고 이 쿼리 벡터와 각각의 key vector와의 내적값을 구하고 결과를 softmax에 통과시켜 가중치를 구한후 , 이값과 value vector를 각각 곱해주어 이들의 가중평균으로 최종적인 vector를 구하다. 결국 이 vector가 feature들이 담긴 encoding vector이다.
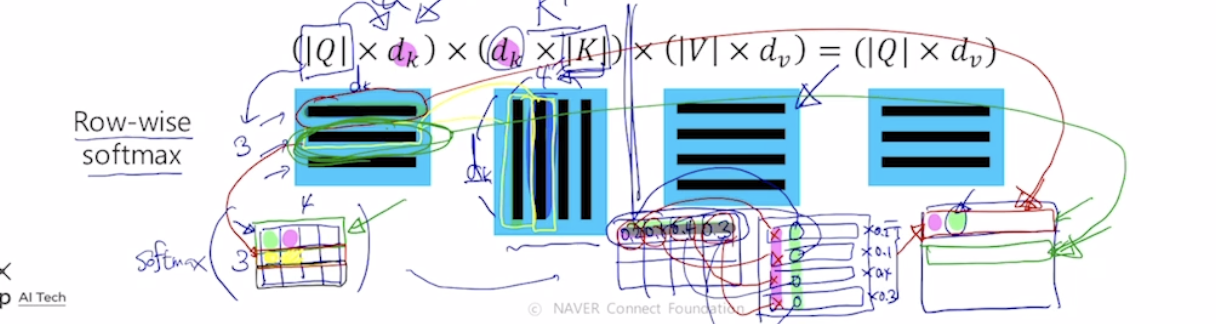
이러하게 행렬연산으로 위의 과정을 한번에 처리할 수 있다.