Optimization
1. Optimization
- 용어들의 명확한 정리가 필요
Concept of Optimization
- Generalization
- Under fitting vs Over fitting
- Cross Validation
- Bias-varience tradeoff
- Bootstraping
- Bagging and Boosting
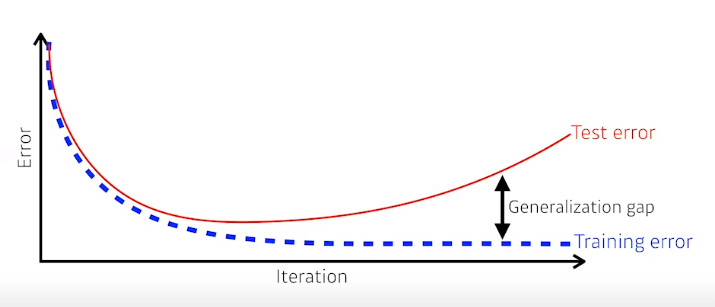
Generalization
일반화 성능을 높힌다?
일반화란 : Training error각 0 이라고 해서 Test error가 0인것은 아니기 때문에
좋은 generalization : network의 Test data 성능이 학습데이터와 비슷하게 나온다
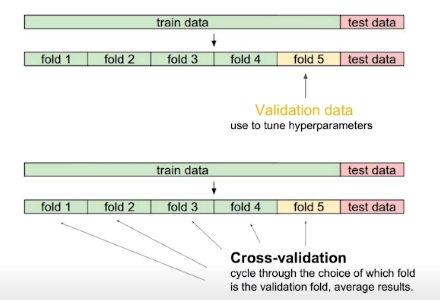
Cross validation
Training data에서 validation data를 나누어서 training된 모델이 validation data 기준으로 얼마나 잘 동작하는지를 판단
나누는 기준??????
학습데이터가 적으면 안된다
따라서 Cross validation을 씀
학습데이터를 K개씩으로 나누어 하나씩 바꾸어가며 validation data로 설정하고 training과 validation을 반복진행
Test data는 저얼대 model 학습에 사용되어서는 안된다!!
Bias-varience tradeoff
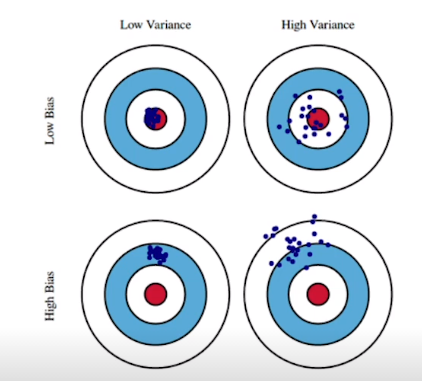
학습데이터에 noise가 껴있을때 Cost를 minimizing하는것은 3개로 decomposed 될수있다
- bias
- varience
- noise
bias와 varience는 trade off관계에 있다

Bootstrapping
Any test or matric that uses random sampling with replacement
학습 data가 100개가 있으면 80개씩 random으로 뽑아서 모델을 여러개를 만들어서 하나의 입력에 대한 consensus를 보고 모델을 수정하는법
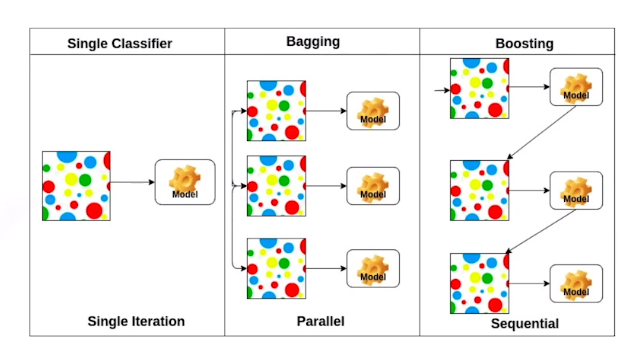
Bagging & Boosting
Bagging (Bootstrapping aggregating)
- Muitiple models are being trained with bootstrapping
- 학습 data가 100개가 있으면 80개씩 random으로 뽑아서(bootstrapping) 모델을 여러개를 만들어서 하나의 입력에 대한 consensus를 보고 모델을 수정하는법
Boosting
간단하게 모델을 만들어 testing후 안좋은 부분을 고쳐나가며 여러개의 model을 만든다
이들을 독립적인 모델이 아닌 이 모델들을 Sequential하게 합쳐서 하나의 strong learner를 만든다
Gradient Descent Method
- Stocastic (한번에 1개의 sample을 사용하여 gradient update)
- Mini batch (한번에 적당히 작은 batch size개수의 samples를 사용하여 update) S
- Batch (모든 data를 다 써서 gradient를 update)
Batch gradient descent를 사용할 경우 step 한번에 모든 data에 대한 loss function을 계산해야 하므로 계산량이 터진다
이를 방지하기 위해 쓰는 것이 SGD (stocastic gradient descent), mini batch
Batch보다 다소 부정확 할수는 있지만 빠른 계산속도로 인한 빠른 수렴속도
BATCH SIZE MATTERS!!!
Large batch size converge to sharp minimizers
Small batch size converge to flat minimizers —> High Generalize performance
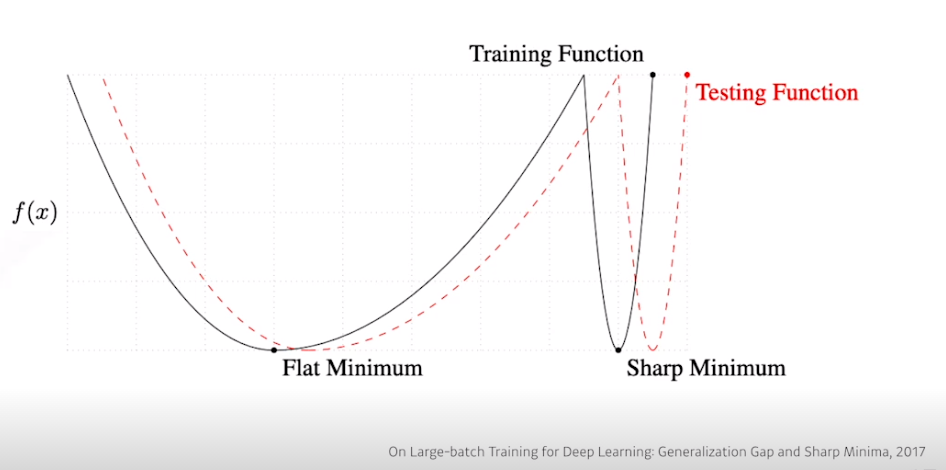
위의 그래프는 model의 training data와 testing data에 대한 loss function이다.
큰 batch size를 써서 sharp minimum 값을 가지게 된다면, 우리가 원했던 training fuction의 minimum에서의 testing function에서의 testing function의 값을 보면 최소점이 아닌 꽤나 큰값을 가진다. 이는 모델이 Generalize성능이 떨어진다는 이야기로 귀결된다. 하지만 작은 batch size를 써서 function들이 Flat Minumum값을 가지게 된다면, 꽤나 Generalize 성능이 좋다.
위의 논문 읽어보면 좋다고 추천해 주심
Automatic Differentiation
- SGD
- Momentum
- Adagrad
- RMSprop
- Adam
- …
Momentum
1번 gradient가 한쪽으로 흐르게 되면 이전의 gradient정보를 사용하여 이어가는 방향 ? 이런느낌
SGD와 달리 parameter업데이트시 gradient를 바로 사용하여 업데이트 하는게 아니라 a라는 term을 만들어 이전의 gradient 값을 반영해주는 term을 추가해 주었다.
- a
t+1<= Bat+ gt - W
t+1<= Wt- $\eta$at+1 - B가 momentum, a
t+1가 accumulation, a는 momentum을 포함하고 있어서 한번 흘러가기 시작한 gradient를 유지시켜줌
momentum을 사용하면 SGD에서 local minimum에 빠졌던 문제를 해결할수도 있다. Momentum으로 기존의 local minimum을 빠져나와 더 좋은 minimum으로 갈수도 있다는 것이다.
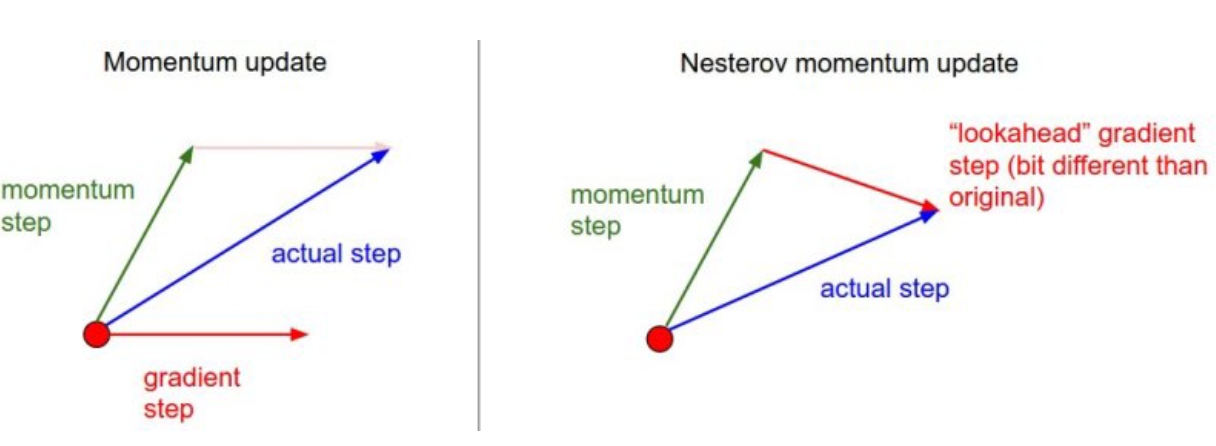
NAG (Nesterov Accelerated Gradient)
- a
t+1<= Bat+ $\nabla$ L(Wt- $\eta$Bat+1) - W
t+1<= Wt- $\eta$at+1 - $\nabla$ L(W
t- $\eta$Bat+1) : a라고 불리우는 현재정보에서 그방향으로 한번가보고 (lookahead) 이를 포함해서 update - momentum은 관성 : 따라서 값이 local minimum에 수렴하지 못하는 현상이 일어날 수도 있음 (관성을 가져서)
- NAG를 쓰면 convergance ratio가 좋다
Adagrad
adapts the learning rate
parameter가 변해왔는지 안변해왔는지를 보고 parameter를 업데이트
Sum of gradient squares -> G
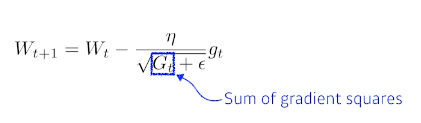
G가 결국 계속커지기 때문에 W가 업데이트가 안되고 학습이 멈추는 현상이 발생
따라서 G의 문제를 해결하는게 뒤의 optimizer인 Adadelta
Adadelta
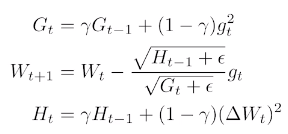
엄청난 양의 memory가 필요
이를 해결하기 위해 감마, 1-감마 : exponential moving average(EMA)
There is no learning rate in Adadelta!!
RMSprop
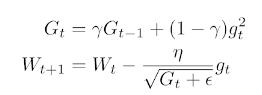
Adam
adaptive moment estimation

2. Regulization
- For good generalization
- 학습을 방해하는게 요점
- Overfitting 방지 이런거
종류
- Early Stopping
- Parameter norm penalty
- Data augmentation
- Noise robustness
- Dropout
- Batch Normalization
Early stopping
- 중간에 학습을 멈추어 validation data를 만드는
Parameter norm penalty
weight가 작을수록 좋다? -> function space내에서 부드러운 함수일수록 generalization performance가 높을것이다
Data augmentation
- 데이터의 개수를 늘리기 위해 label preserving data augmentation같은걸 사용
- label이 변환되지 않는 선에서 data를 변환
Label smoothing

이러한 방법으로 dataset을 확장시켜 model을 training 해보면 성능향상이 뚜렸하다
Batch Normalization
내가 적용하고자 하는 statistics를 정규화
각각의 layer가 1000개의 parameter라면 각각의 parameter가 정규화되게 하는것
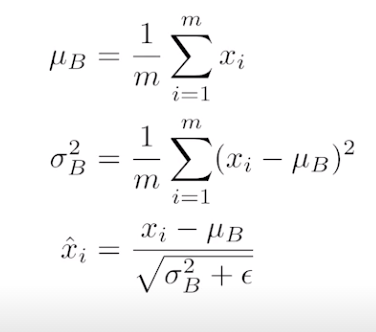
Internal feature shift를 줄인다???? -> 논란이 많다
그럼에도 활용하면 일반적으로 성능이 많이 향상된다
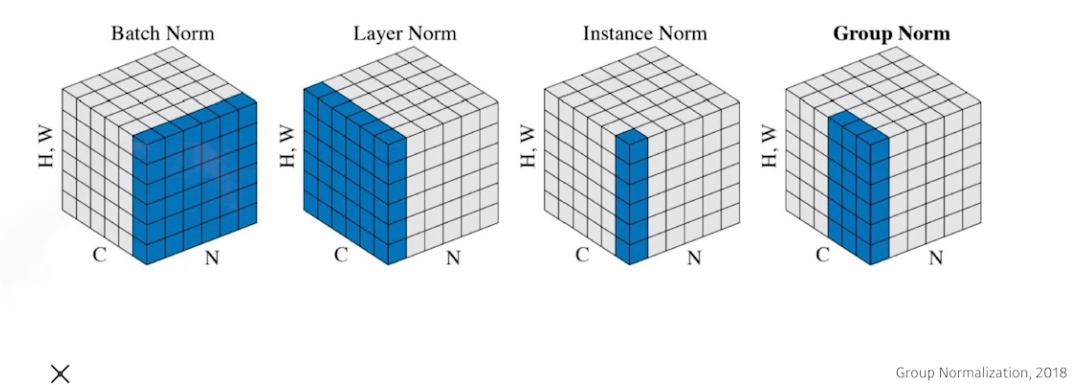
하나하나를 활용하여 Normalize를 하면서 좋은 성능이 나는걸 선택 ㅋㅋ
Further Question
- Regression Task, Classification Task, Probabilistic Task의 Loss 함수(or 클래스)는 Pytorch에서 어떻게 구현이 되어있을까요?
- 올바르게(?) cross-validation을 하기 위해서는 어떻 방법들이 존재할까요?
- Time series의 경우 일반적인 k-fold cv를 사용해도 될까요?
- TimeseriesCV
Further Question 1
Pytorch 내부에서의 Loss function 구현
- Regression Task의 Loss function
torch.nn.L1Loss(size_average=None, reduce=None, reduction: str = ‘mean’)
Measures the mean absolute error (MAE) between each element in the input x and target y .
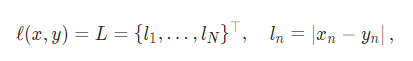
내부적으로 L1Loss가 어찌 구현되어 있나 확인해 보자
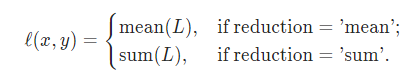
내부적으로 reduction을 mean으로 설정시 우리가 알고있는 sum을 n으로 나눈 값을 loss로 사용(기본값 : mean)
reduction을 sum으로 설정시 n으로 나누는게 사라진 그저 차이의 norm의 sum값
torch.nn.MSELoss(size_average=None, reduce=None, reduction: str = ‘mean’)
Measures the mean squared error (squared L2 norm) between each element in the input xx and target yy .
위의 L1 loss와 다른점은 차이의 제곱
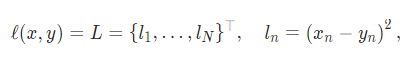
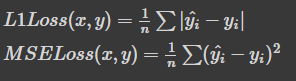
- Classification Task의 Loss function
torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = ‘mean’)
내가 이 loss function을 사용했을때는 분류문제중, 2개의 label 사이에서 classification을 할때는 BCELoss를 사용하고 NN의 출력단에 sigmoid함수를 적용해주었다.
nn.BCEWithLogitsLoss하지만 이 함수를 사용시 sigmoid가 내부적으로 포함되어있다
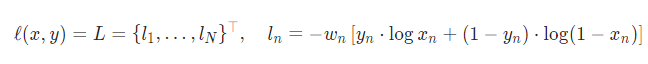
loss function을 보면
torch.nn.CrossEntropyLoss(weight: Optional[torch.Tensor] = None, size_average=None, ignore_index: int = -100, reduce=None, reduction: str = ‘mean’)
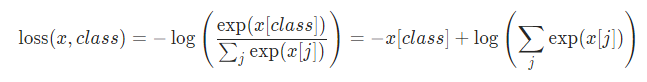
- Probabilistic Task의 Loss function
torch.nn.NLLLoss(weight: Optional[torch.Tensor] = None, size_average=None, ignore_index: int = -100, reduce=None, reduction: str = ‘mean’)
The negative log likelihood loss. It is useful to train a classification problem with C classes.
Further Question 2
올바르게(?) cross-validation을 하기 위해서는 어떤 방법들이 존재할까요?
일정한 k개로 data를 나누어 그중에 하나를 validation data로 사용하는 -> k-fold cv
validation
hyper paramter : 우리가 정하는 값 ex) lr, network 깊이, loss function 종류, 등등
cross validation으로 최적의 hyper parameter를 찾고 이걸 고정한 상태에서 전체 training data를 사용해서 학습을 시킨다
모형의 파라미터 추정에는 트레이닝셋을 사용하고, 하이퍼파라미터 설정에는 밸리데이션 셋을 사용합니다
Further Question 3
Time series의 경우 일반적인 k-fold cv를 사용해도 될까요?
시간의 정보를 가진 data를 기존의 k-fold cv를 사용하여 섞어 버린다면 , 과거와 미래가 뒤섞여 안된다
for time series data we utilize hold-out cross-validation where a subset of the data (split temporally) is reserved for validating the model performance.
이는 결국 training data set -> validation data set -> test data set 이 시간순으로 배열되야 한다는 뜻이다
- Time dependency
현재의 시점에서 미래의 data를 예측하는 모델을 맞추는 데 사용 된 이벤트 이후에 시간순으로 발생하는 이벤트에 대한 모든 데이터를 보류해야합니다.
따라서 교차적으로 data를 바꾸어주는 K-fold 대신 hold-out cross-validation을 사용해야 한다
이는 결국 training data set -> validation data set -> test data set 이 시간순으로 배열되야 한다는 뜻이다
- Arbitrary Choice of Test Set
만약 우리가 임의적으로 정한 test set에서 poor한 결과를 내었다면, 이는 전체적인 data에 대한 poor한결과가 아닌 그 특정한 독립적인 test set에의 poor한 결과이다
따라서 우리는 Nested Cross-Validation을 사용한다
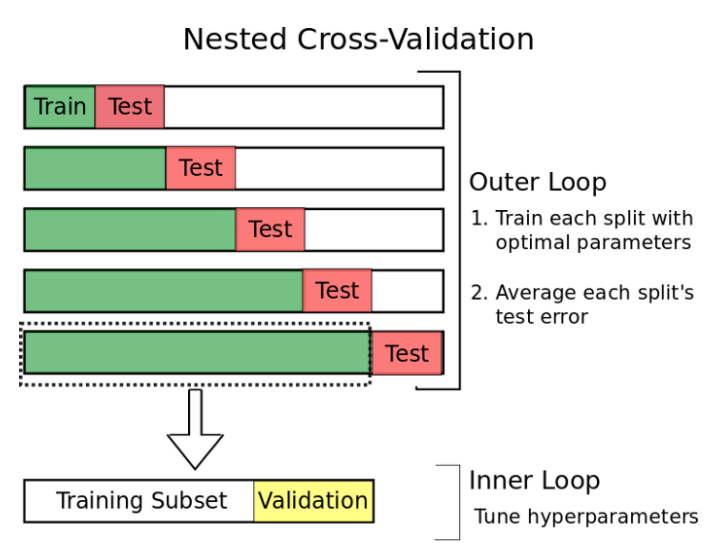
그림을 보면서 Nested cv를 알아보자
Nested CV에는 오류 추정을 위한 외부 loop와 hyperparameter추정을 위한 Inner loop가 있다
내부루프는 train data set을 나누는 걸로 앞서 설명한일반적인 CV구조이다
이제 data set를 여러 train과 test set으로 나누는 외부루프가 추가되었고 각 분할된 오류의 평균을 구한다
Nested CV for Time series data
- Predict second half
데이터의 전반부 (일시적으로 분할)는 훈련 세트에 할당되고 후반부는 테스트 세트가 된다
validation data의 크기는 달라질수 있지만, 순서는 data의 시간 순서는 항상 test data set이 train보다 뒤에있어야 한다
이게 앞선 1의 time dependency를 해소시킨 것이다

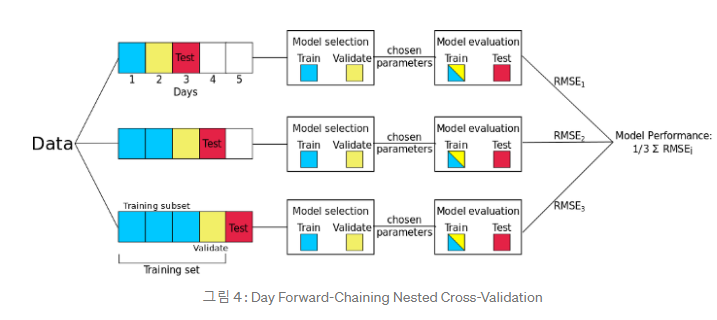
- Day Forward-Chaining
predict second half의 단점은 hold-out dataset(앞서 말한 연대순)을 임의로 선택하게 되면 time dependency는 해결되었지만 Arbitrary Choice of Test Set을 해결하지 못하게 된다
따라서 앞서 말한 Nested CV와 같이 많은 train과 test data set을 만들어 이들의 오류값을 구해 평균을 내어준다
예를 들면 1일을 test set으로 간주하고 나머지를 train set으로 해주는 것이다