Computer Vision application
Computer Vision application
Fully Convolutional Network
- 기존의 CNN 구조 :
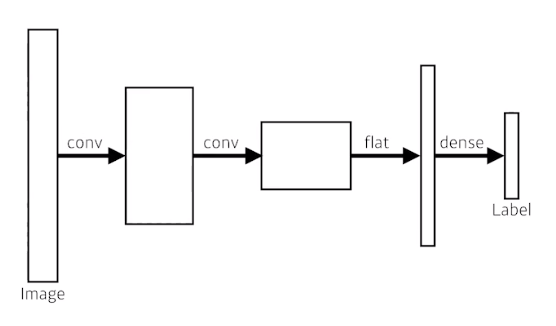
- Fully Convolutional Network :
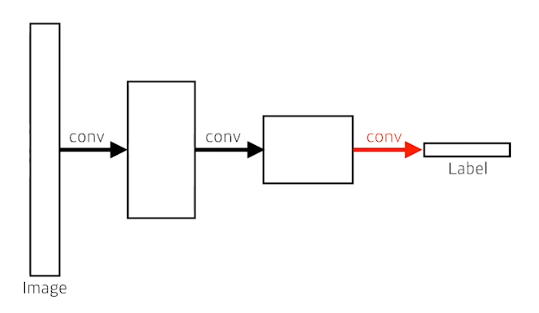
Dense layer를 없앴다. - > convolutionize
결국 input과 output은 같다
parameter도 같다
flat을 해서 dense layer를 거치나, convolution을 거치나 같다
ex) 4x4x16 이 였다면 이걸 256개의 vector로 flatten 시킨다
FCN을 보면 4x4x16에 똑같은 크기를 가진 kernel을 적용한다
parameter
4x4x16x10 = 2560
4x4x16x10 = 2560
같다

이런짓이 convolutionization
왜 이런걸 할까????
image segmentation 관점에서 생각을 해보자
Fully convolutional network가 가지는 가자은 특징은 바로 input dimension, 특히나 input dimension의 spacial dimension이다
Transforming fully connected layer into convolutional layers enables a classification to output a hitmap
output이 커지게 되면 이거에 비례해서 뒷단의 spacial dimension이 커지게 됨
Because of convolution이 가지는 shared parameter의 성질 때문에
원래는 출력의 hitmap은 input보다 크기가 줄어들기는 하다
그렇지만 hitmap이라는 가능성이 생겼구나!!!
그래서 어떠한 inputsize에도 돌아가지만 이러한 작아진 output을 다시 input size만큼 늘리는 방법
- Deconvolution(convolution transpose)
간단하게 생각하면 convolution 연산으로 줄어든 결과를 convolution의 역연산으로 다시 늘려주는
근데 convolution의 역연산이 존재하나? 불가능하다
근데 그냥 간단하게 이렇게 생각하는게 편하다
deconvolution은 결국 convolution이후에 결과에 padding을 많이 줘서 여기에 같은 size에 kernel을 적용하는것이다
Dectection
R-CNN
- takes and input image
- extract around 2000 region proposal (using selective search)
- computes features for each proposal (size는 모두 똑같이 맞추어 준다, use AlexNet)
- classifies with linear SVMs
SPPNet
- RCNN의 문제 : 2000개를 뽑으면 2000개를 전부 CNN에 돌려야 되기 때문에 시간이 졸라 많이 걸린다
- 따라서 일단 image 안에서 bounding box를 뽑고 image 전체를 CNN에 돌리고, 해당하는 위치의 tensor만을 활용하자
Fast R-CNN
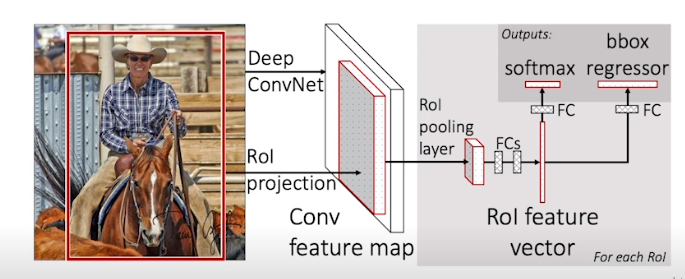
selective search로 bounding box를 얻고 전체 이미지를 CNN에 통과 그리고 ROI pooling layer를 통해 각각의 region에 대해서 feature를 뽑는다
그리고 마지막에 Fully connected layer을 통해 bounding box를 어떻게 움직이면좋은지, label이 뭔지를 알아낸다
Faster R-CNN
Bounding box를 뽑아내는 Region proposal도 학습을 하자!
selective search를 하지말고 이것도 학습을 하자는 의미
이 network를 region proposal Network가 추가됨
Region proposal Network
- 이미지의 특정영역이 bounding box로서 의미가 있는지 없는지만 찾아주는 Network
- 여기서 필요한게 Anchor box
- 미리 정해놓은 Bounding box의 크기 : anchor box
어떤 크기의 물체가 있을것 같다?
해당하는 영역의 이미지에 물체가 들어있을지 안들어있을지가
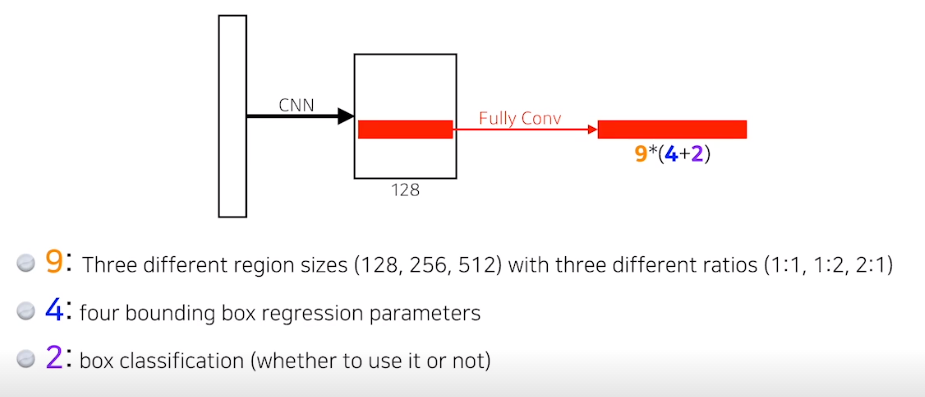
해당하는 영역에 물체가있을지에 대한 정보를 알고있다
9개의 region size중에 1개를 골라서
얼마나 bounding box를 늘이거나 줄일지 , xy에 off set을 줘야 해서 4개의 parameter
해당 box가 쓸만한지 아닌지
9x(4+2) = 54만큼의 channel이 나오는
YOLO
faster R-CNN보다 훨씬 빠름
Region에 해당하는 sub tensor을 분류하는게 아니라 그냥 image를 때려 넣으면 딱 나오기 떄문에 빠름
- no exclusive bounding box sampling (region proposal)
YOLO에 대해서는 추가로 정리해서 따로 posting 하겠다
Computer Vision application
https://jo-member.github.io/2021/02/03/2021-02-03-Boostcamp13.2/