pstage4
Pstage4_수식인식
Github Repository
팀 소개
🎸 조원
SATRN (Locality Feedforward, Shallow CNN) 구현
Augmentation (Resize & Noramlization& pixel 평균에 따른 이진화…) 제안 & 실험
Ensemble (soft voting) 구현 & 실험
teacherforcing ratio scheduling 실험
Beam search 구현
부족한 token에 대한추가 Data 생성
CSTR 논문 reading & 공유
협업
- Git의 Discussion, Pull & Request, Wiki를 활용하여 토론, 자료, 결과공유
- Wandb를 사용하여 실험공유
수식인식 Competition Overall
상세개요
수식 이미지를 latex 포맷의 텍스트로 변환하는 문제입니다. 수식은 여러 자연과학 분야에서 어려운 개념들은 간단하고 간결하게 표현하는 방법으로서 널리 사용되어 왔습니다. Latex 또한 여러 과학 분야에서 사용되는 논문 및 기술 문서 작성 포맷으로서 현재까지도 널리 사용되고 있습니다.

일반적인 OCR과 달리 분수, 시그마, 극한과 같은 표현을 인식하기 위해 multi line recognition을 특징으로 가집니다.
Dataset
Scale : 각각의 image scale은 제각각
Label : Latex 형식의 수식
Train Data
- Hand Written Data : 50000
- Printed Data : 50000
Evaluation Data
- Public : 6000
- Private : 6000
Prediction
- 241개의 token class중 하나를 생성한 뒤 이들의 sequence
평가 Metric
0.9 x “Sentence Accuracy” + 0.1 x (1-“WER”)
Sentence Accuracy
전체 추론 결과(수식) 중에서 몇 개의 수식이 정답(ground truth)과 정확히 일치하는 지
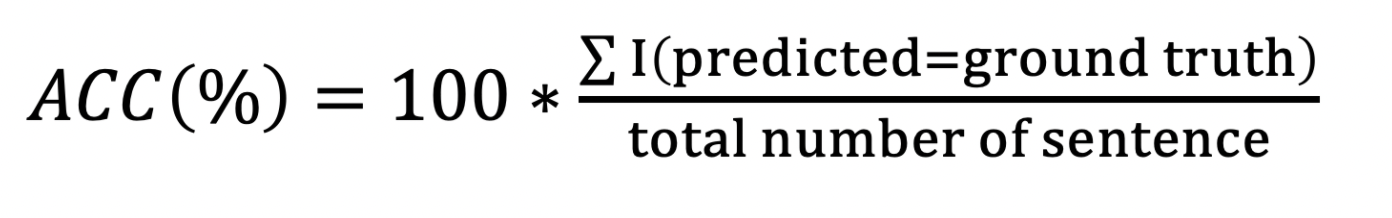
WER (Word Error Rate)
단어 단위로 삽입(insertion), 삭제(deletion), 대체(substitution)된 글자 개수를 계산
Problem & Solving
EDA
부족한 token data
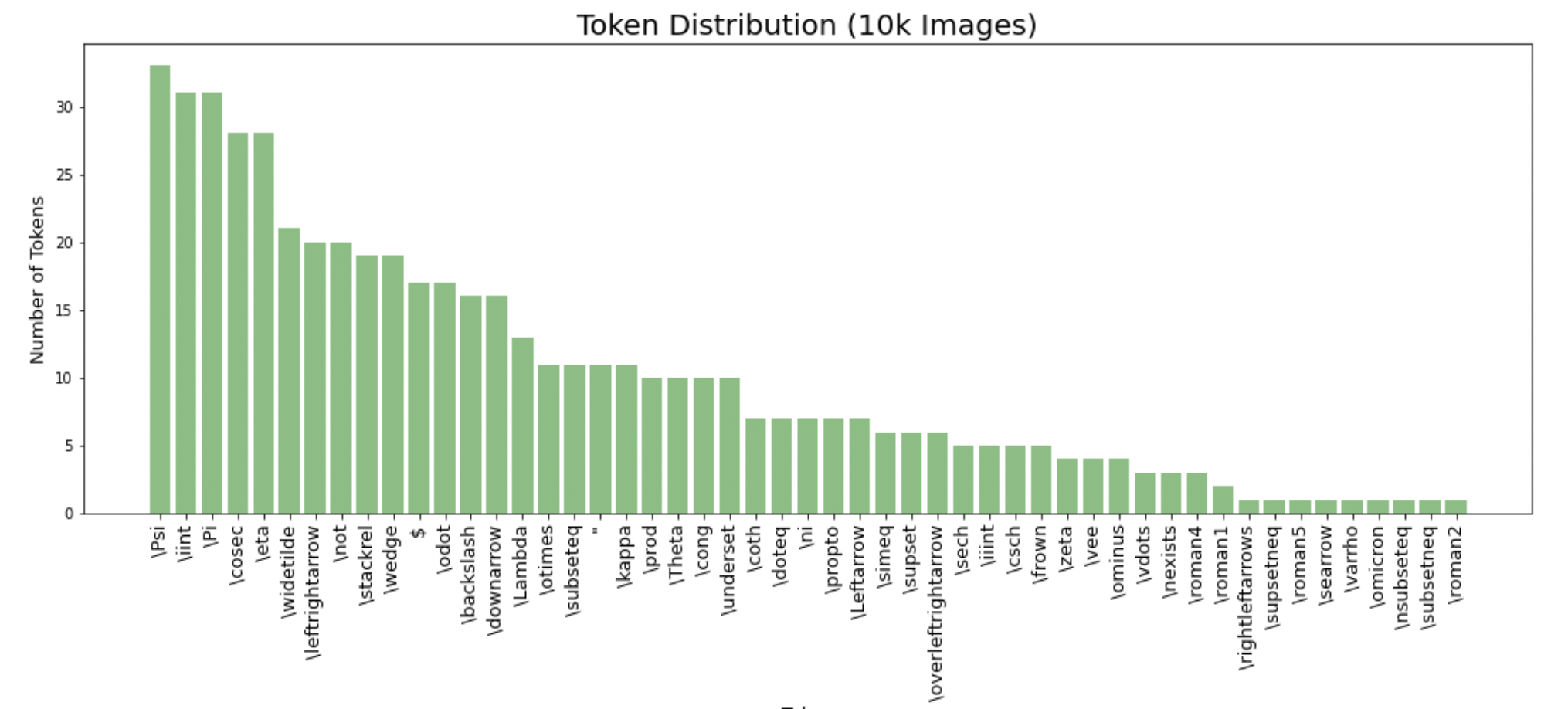
Train data에 등장하는 token들중 빈도수가 가장적은 50개를 뽑아보았다.
10회 미만으로 등장한 token들에 대한 추가적인 data가 필요하다고 판단되었다.
사이트를 활용하여 부족한 token들을 포함하는 수식을 train파일에 50개 정도의 data를 추가해주었다.
train_100003.jpg \ominus \vdots \nexists \rightleftarrows A \supsetneq B

세로형태의 수식 이미지
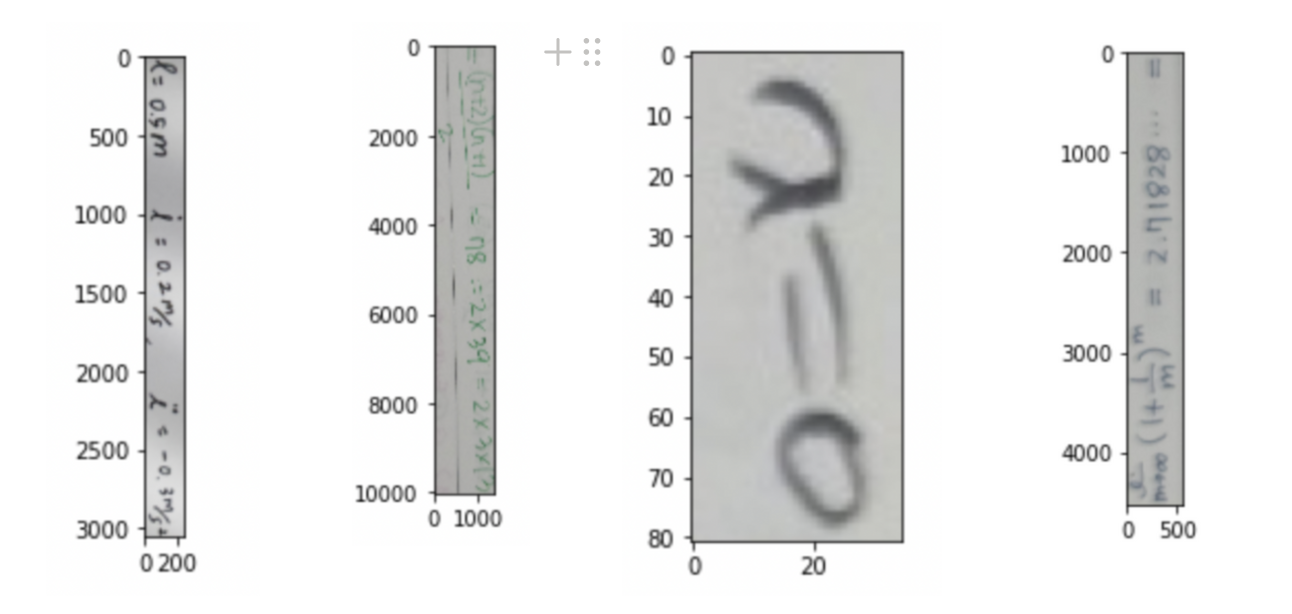
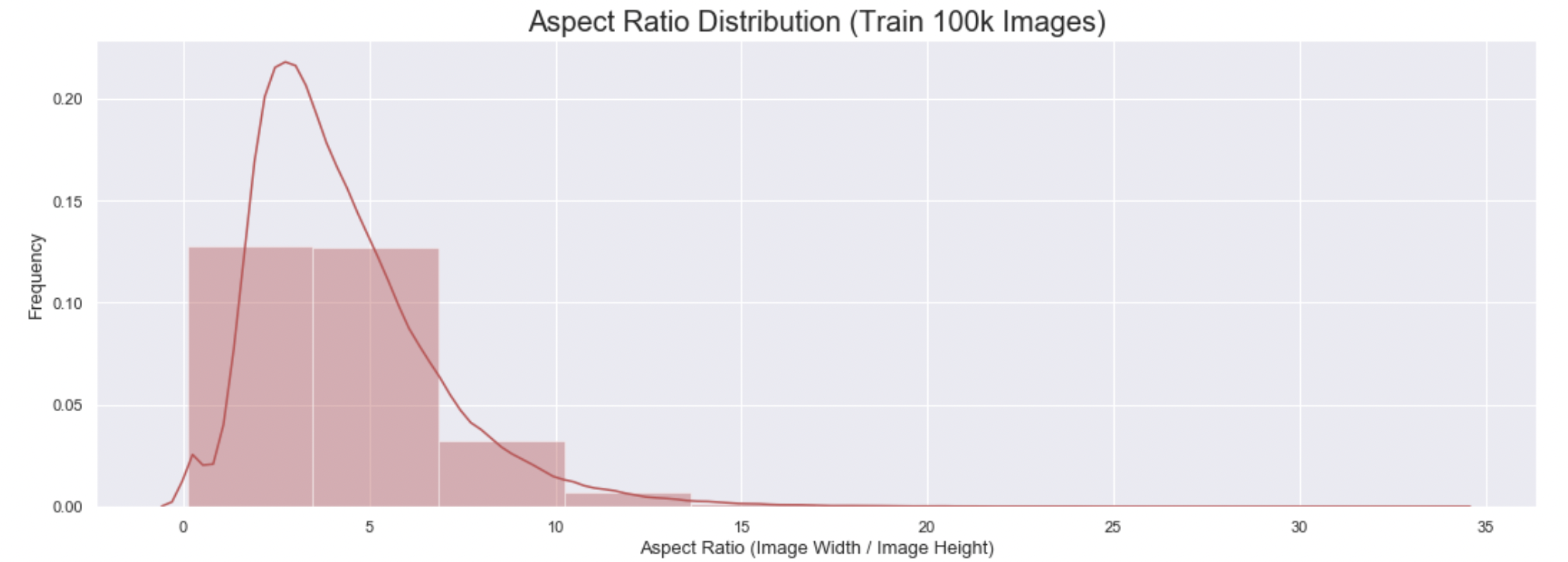
다양한 Aspect Ratio
잘못된 labeling
P = 1이 아닌
P = 으로 labeling 되어있음

선이 그어져 있거나 형광팬이 칠해져 있는 case
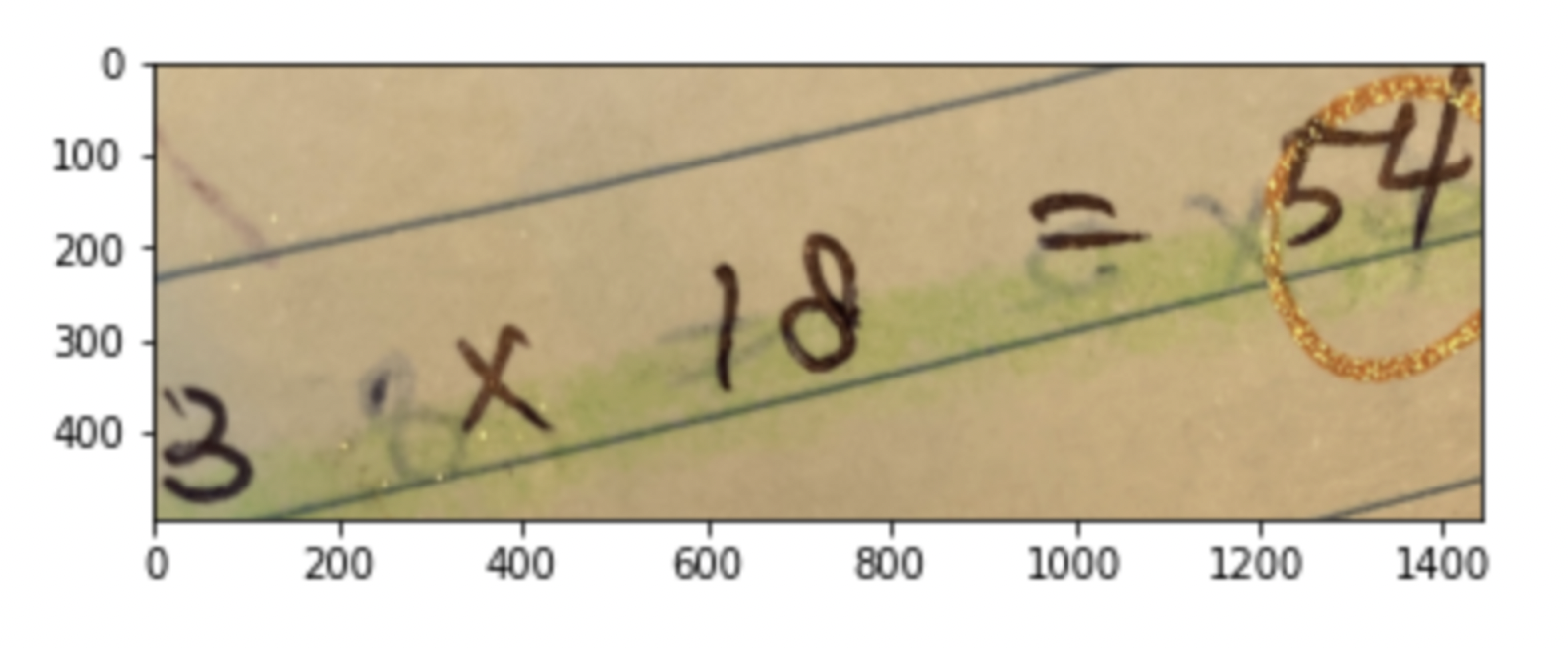
Augmentation
Resize
Rotate
OCR task에서 세로로 되어진 image들은 모두 noise로 작용
EDA에서 적당한 Aspect ratio의 threshold를 찾은 뒤, threshold 미만인 data들에 한하여 Rotate
Normalization
이미지의 각 pixel 값들을 0-1의 값으로 normalize 시켜준다
이진화 & 가로선 제거
Model (SATRN)
Locality-aware feedforward layer
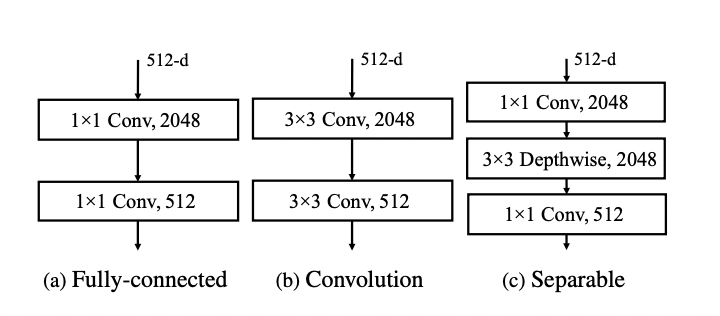
Base-line model에 구현된 Fully-connected feed forward에서 논문에서 제시하고 있는 Convolutuon feed forward로 교체
Adaptive 2D Positional Encoding
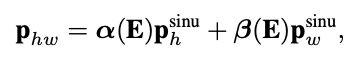
Baseline에서 구현된 일반적인 2D positional encoding에서 논문에서 제시한 학습가능한 adaptive 2D positional encoding으로 변경
Backbone
- EfficientNet
- DenseNet
- ShallowCNN
Mini SATRN for fast experiment
다양한 실험을 빠르게 진행하기 위해 SATRN의 size를 줄여서 Mini SATRN으로 다양한 실험을 진행
SATRN의 layer parameter 수정
Increase number of Decoder Layer
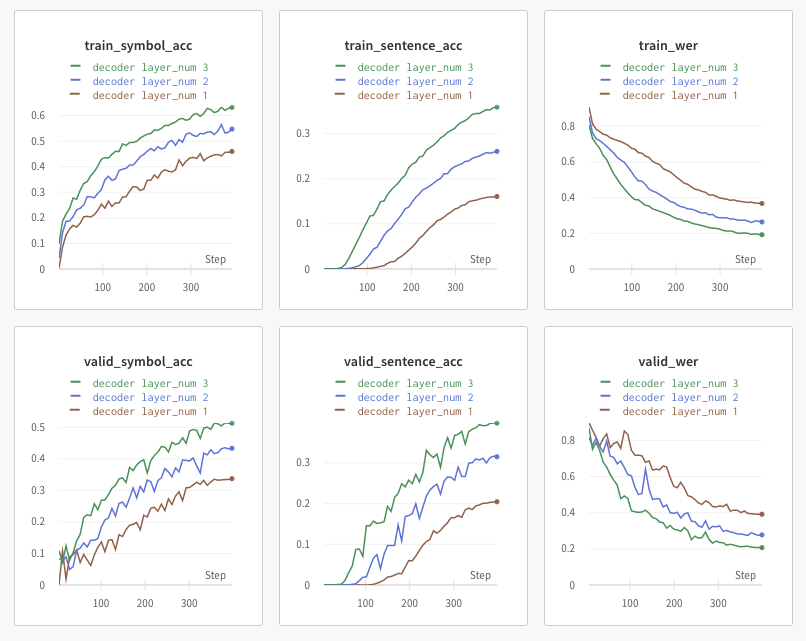
mini model 기준, Decoder layer를 추가할수록 성능이 향상
Change Activation Function
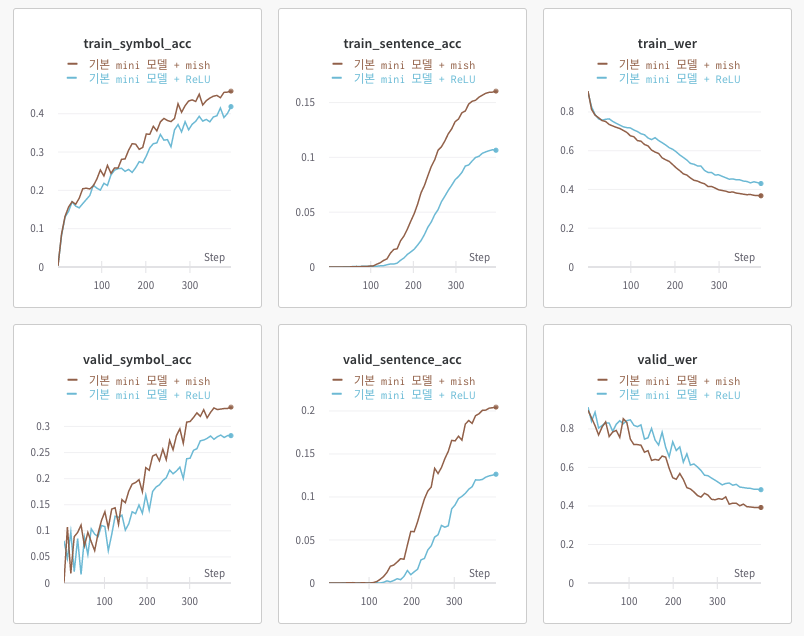
ShallowCNN의 activation function을 ReLU대신 mish를 사용
Post - Processing
Beam search
Token을 뽑을 때 argmax를 사용하여 하나의 token만을 뽑는게 아닌 각 step마다 beam size k 만큼의 token을 뽑아 최대한 적합한 sequence를 선택하려 시도함
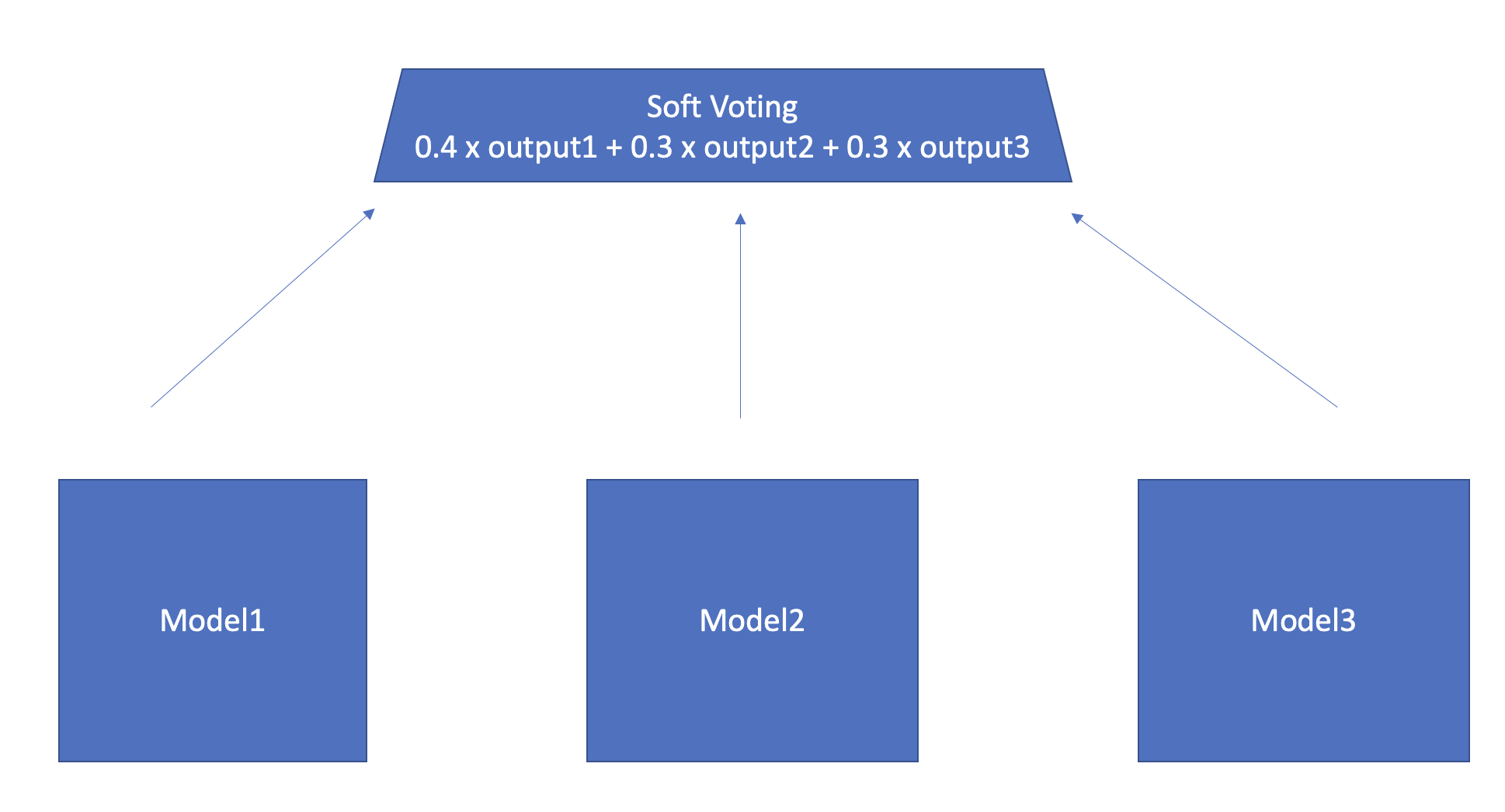
Ensemble
다양한 augementation을 거친 model들을 한번에 불러와서 soft voting을 사용하여 ensemble
Baseline에는 빠져있는 torch.nograd로 memory 절약
Use Language Model (x)
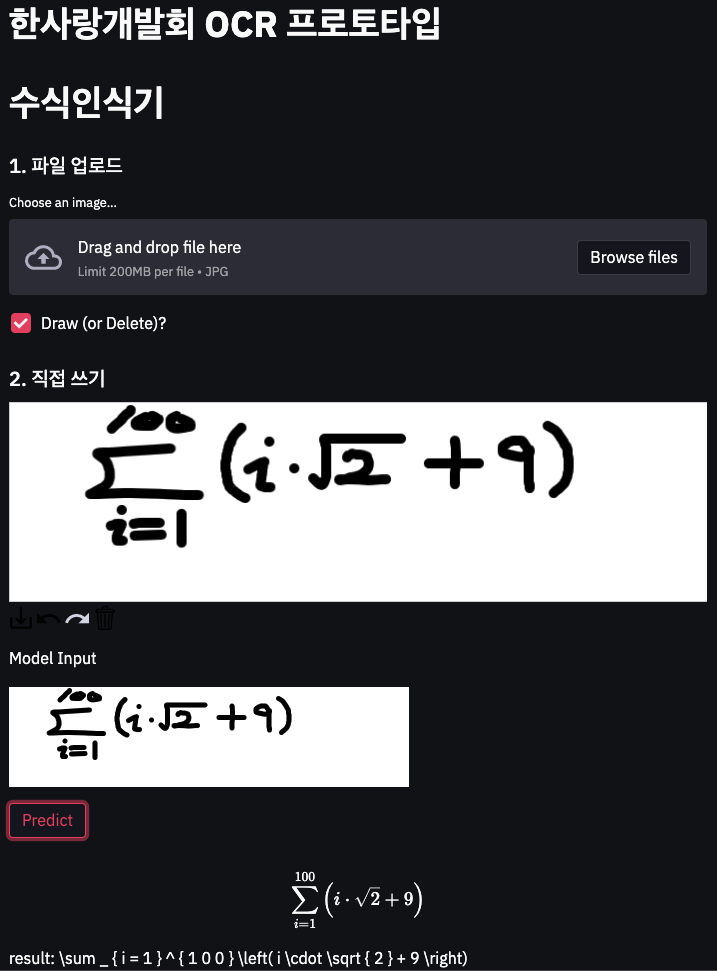
OCR Demo
데모페이지 주소 : http://35.74.99.158:8501/
Paper Review
프로젝트 진행을 위해 읽은 논문의 목록은 다음과 같음
Misspelling Correction with Pre-trained Contextual Language Model.pdf
An_Attentional_Scene_Text_Recognizer_with_Flexible_Rectification.pdf
Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks.pdf
TextBoxes_A Fast Text Detector with a Single Deep Neural Network.pdf