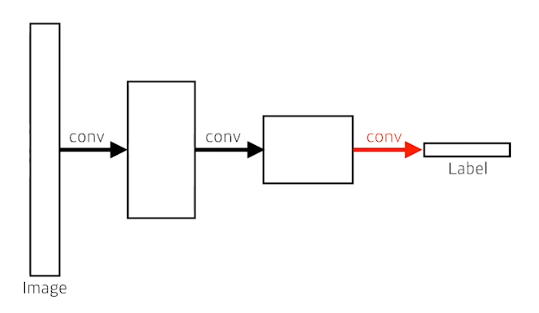
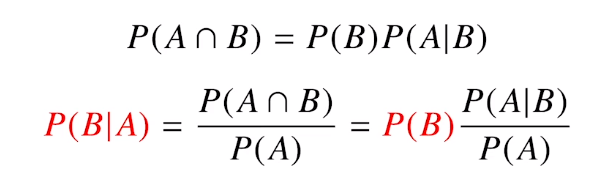RNN1
RNN
Sequence Data & Model
소리, 주가, 문자열 등의 데이터를 시퀀스 데이터로 분휴합니다
시계열 데이터는 시간순서에 따라 나열된 데이터로 시퀀스 데이터에 속한다
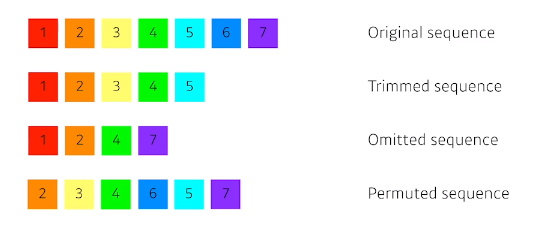
독립동등분포 가정을 잘 위해하기 때문에 순서를 바꾸거나 과거정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 된다
Markov model : first order autoregressive model
이들의 문제를 해결하기 위해 Latent autoregressive model
hidden state가 과거의 정보들을 summerize한다