RNN심화1
RNN
서로다른 time step에서 들어오는 입력 데이터를 처리할때, 매번 반복되는 동일한 rnn module을 호출한다.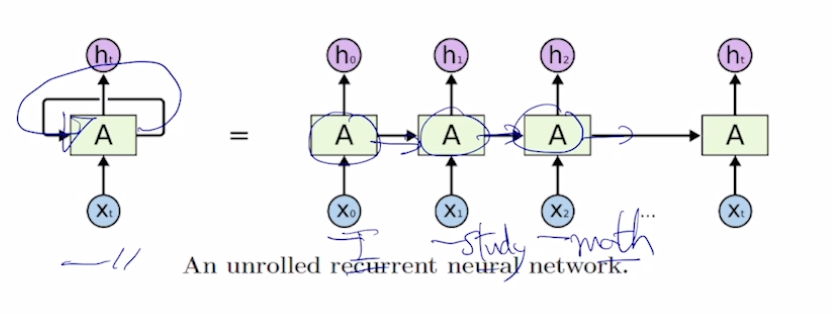

각 단어별로 품사를 예측해야 되는 경우 -> 매 time step마다 y를 output으로
어떠한 문장의 긍부정을 판별하는 경우 -> 최종 time step의 y만이 output으로
모든 time step에서 같은 parameter W를 공유한다
서로다른 time step에서 들어오는 입력 데이터를 처리할때, 매번 반복되는 동일한 rnn module을 호출한다.
각 단어별로 품사를 예측해야 되는 경우 -> 매 time step마다 y를 output으로
어떠한 문장의 긍부정을 판별하는 경우 -> 최종 time step의 y만이 output으로
모든 time step에서 같은 parameter W를 공유한다
이번에는 openai에서 발표한 논문인 GPT를 review해보겠다
GPT3는 이전에 review한 transformer구조를 활용하여 Language understanding을 효과적으로 만들었다.
자연어를 이해는 text추론, 질문에 대한 대답, 의미의 유사성 평가, 문서분류등을 포함하고 있다. 라벨링 되지 않은 text들을 매우 넘처나지만, 특정 task의 학습을 위해 labed된 text들은 매우 적기때문에 좋은 모델을 학습시키는것은 매우 힘들다. Language 모델을 unlabled된 text로 generative pretrain을 한이후 각각의 task에 맞게 fine-tunning을 하였다. 이러한 많은 unlabed text를 사용하여 학습하였다. 이전의 연구와는 달리,필요한 task에 fine-tuning하여 응용하는 것이 매우 효과적이다.
https://deepgenerativemodels.github.io/
Suppose we have some images of dogs
We want to learn a probability distribution p(x) such that
Generation : If we sample xnew ~ p(x), xnew should look like a dog
Density estimation :p(x) should be high if x look like a dog (어떤이미지의 확률을 계산함)
이건 마치 image classification
Unsupervised representation learning
특정 image가 어떤 특징을 가지고있는지를 학습
Seuence transduction model들은 현재 복잡한 recurrent한 구조 (RNN) 이나 encoder decoder를 포함한 CNN이 주를 이룬다. 가장 좋은성능을 내는 model또한 attention mechanism을 이용하여 encoder와 decoder를 연결하는 형태이다.
이 논문에서는 새로운 방법인 Transformer를 제안
이는 오로지 attention mechanism만을 사용!
이는 RNN이나 CNN보다 더 병렬화가 가능하고 train하는데 적은 시간이 걸린다!
WMT 2014 English to-German data를 사용하여 BLEU라는 score에서 28.4점을 얻었다.(여러 논문을 읽다보면 자주 등장하는 이 BLUE score은 정리해 놓은게 있는데 추후에 posting )
이는 앙상블을 포함한 이전의 가장 좋은 성능보다 2BLUE가 높다.
소리, 주가, 문자열 등의 데이터를 시퀀스 데이터로 분휴합니다
시계열 데이터는 시간순서에 따라 나열된 데이터로 시퀀스 데이터에 속한다
독립동등분포 가정을 잘 위해하기 때문에 순서를 바꾸거나 과거정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 된다
Markov model : first order autoregressive model
이들의 문제를 해결하기 위해 Latent autoregressive model
hidden state가 과거의 정보들을 summerize한다
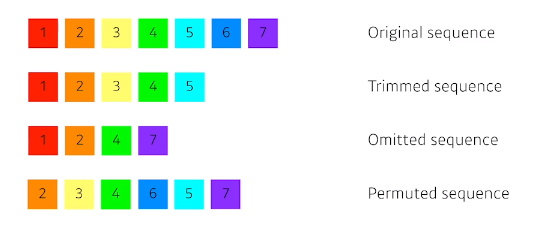
위와 같은 문제로, RNN같이 sequential한 문제들을 해결할 때, 중간에 단어가 빠지거나 하면 해결하기가 어려움
—> 여기서 나온게 Attention을 사용한 Transformer
지금까지 배운 MLP는 fully connected. 가중치 행들이 i번째 위치마다 필요해서 i가 커지면 가중치 행렬의 크기가 커지게 됨
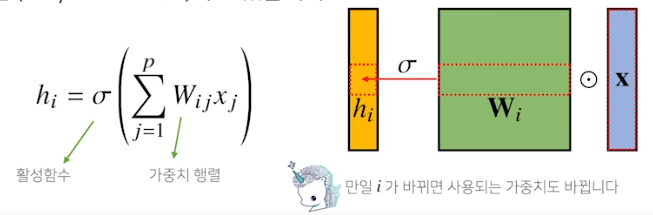
우리가 이제부터 볼 Convolution 연산은 커널이라는 고정된 가중치 행렬을 사용하여 고정된 커널을 입력벡터에서 옮겨가며 적용
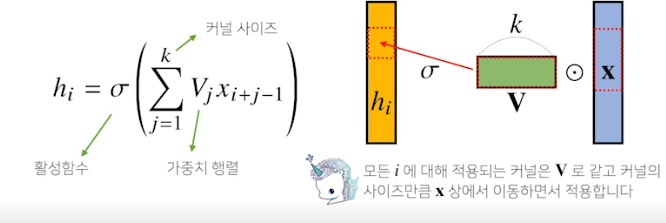
x라는 입력벡터 상에서 커널사이즈 만큼 움직여 가며 연산
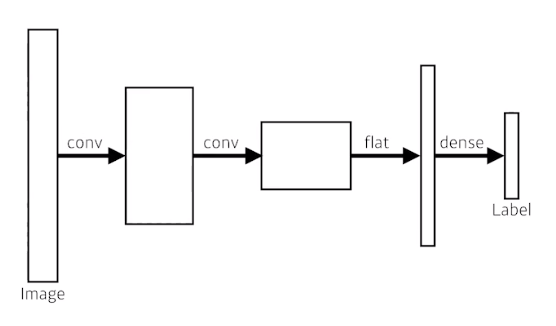
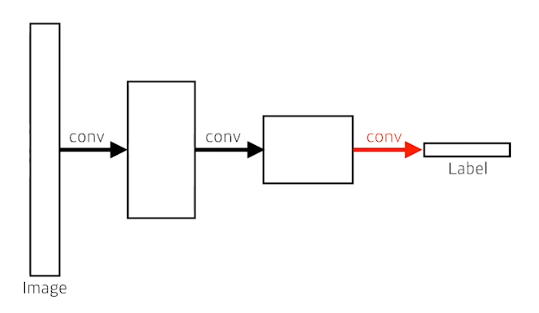
Dense layer를 없앴다. - > convolutionize
결국 input과 output은 같다
parameter도 같다
flat을 해서 dense layer를 거치나, convolution을 거치나 같다
ex) 4x4x16 이 였다면 이걸 256개의 vector로 flatten 시킨다
FCN을 보면 4x4x16에 똑같은 크기를 가진 kernel을 적용한다
parameter
4x4x16x10 = 2560
4x4x16x10 = 2560
같다